현재의 서비스는 방대한 DB데이터가 있다. 따라서 쿼리를 작성할 때 쿼리의 최적화 여부에 따라 서비스의 성능이 눈에 띄게 차이난다.
- 인덱스가 걸려있는 컬럼을 변형하게 되면 인덱스를 사용하지 못한다.
- 따라서 함수,계산,표현식을 사용하지 않거나, 꼭 필요하다면 인덱스가 없는 테이블에 연산을 작성해야 한다.
--비효율--
WHERE SUBSTR(EMPNAME,1,3) = 'lee'
--효율--
WHERE EMPNAME LIKE 'lee%'--비효율--
WHERE SALARY + 1000000 < 2000000
--효율--
WHERE SALARY < 1000000- 당연하게도 많은 필드를 불러오는 것은 더 많은 부하를 가져온다.
- 따라서, 사용한 필드를 지정해서 가져온다.
--비효율--
SELECT * FROM EMP;
--효율--
SELECT EMPNAME,SALARY FROM EMP;- 컬럼의 데이터 타입을 일치시켜서 비교문을 진행해야 한다.
--만약, DEPTNO가 문자타입 이라면,
--비효율--
SELECT COUNT(1) FROM EMP
WHERE DEPTNO = 1;
--효율--
SELECT COUNT(1) FROM EMP
WHERE DEPTNO = '1';- 비효율의 WHERE절은
TO_NUMBER(DEPTNO) = 1와 동일하게 때문에 인덱스를 사용하지 못할 수 있다. - 따라서 인덱스 활용을 위해서는 데이터 타입을 일치시켜야 한다.
- 중복을 제거하는 연산에는 많은 시간이 걸린다.
- DISTINCT,UNION보다는
EXISTS같은 함수가 효율이 더 좋다.
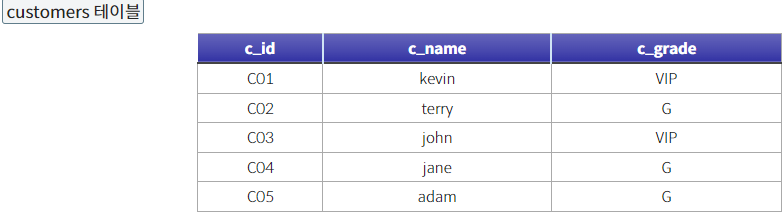
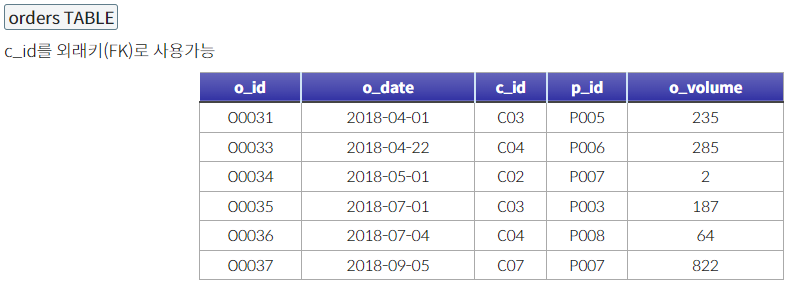
--비효율--
SELECT DISTINCT c.*
FROM customers c JOIN orders o
on o.c_id = c.c_id;
--효율--
SELECT * FROM customers WHERE EXISTS (
SELECT * FROM orders WHERE orders.c_id = customers.c_id);- EXISTS 함수는 존재하는지 여부만 판단하기 때문에 SELECT * 가 아니라 'X'와 같이 임의의 값을 넣어도 된다.
- LIKE'%...'의 경우
FULL SCAN을 사용하여 인덱스를 훑지 않는다. - 따라서 되도록 LIKE'...%'와 같이 사용한다.
- INNER JOIN 과정에서 FROM 에는 가장 크기가 큰 테이블, 그리고 순서대로 INNER JOIN을 하는게 속도면으로는 빠르다.
- 다만,
쿼리플래너가 효율성을 예측하여 쿼리를 실행시키기 때문에 이렇게 하더라도 항상 적용되진 않는다.
- 쿼리 실행 순서에서,
WHERE절이HAVING절보다 먼저 실행된다. - 따라서 WHERE절로 미리 데이터 크기를 작게 만들면
GROUP BY에서 다뤄야하는 데이터 크기가 작아진다.
---비효율---
SELECT m.id, COUNT(r.id) AS rating_cnt, AVG(r.value) AS avg_rating
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
GROUP BY id
HAVING m.id > 1000;
---효율---
SELECT m.id, COUNT(r.id) AS rating_cnt, AVG(r.value) AS avg_rating
FROM movie m
INNER JOIN rating r
ON m.id = r.movie_id
WHERE m.id > 1000
GROUP BY id ;