From d33f5d4bc25e4e999d69f0282bc6096df2364c97 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 17:16:49 +0900
Subject: [PATCH 01/94] Create Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 1 +
1 file changed, 1 insertion(+)
create mode 100644 finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -0,0 +1 @@
+
From 7364c467d08ee4697f14ff6333eb0a828b5432ff Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 17:36:19 +0900
Subject: [PATCH 02/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 8 ++++++++
1 file changed, 8 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 8b13789..183e6c0 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1 +1,9 @@
+# Precision Medicine(lets change to something more descriptive later)
+### by Soyeon Kim, Hwayeon Lee, Meixian Wu
+
+### Sections:
+##### 1. Introduction to Precision Medicine?
+##### 2.
+##### 3.
+##### 4. ...
From 711d2b43ff6fab3f64dab46d7abdea723cd650d3 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 17:37:31 +0900
Subject: [PATCH 03/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 7 +++++++
1 file changed, 7 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 183e6c0..04c76a6 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -7,3 +7,10 @@
##### 2.
##### 3.
##### 4. ...
+
+## 1. Introduction to Precision Medicine
+
+
+
+
+## 4?5?. track 3 part
From 2bd2cac54f2d85c537895bb744e758618e605afd Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 17:38:51 +0900
Subject: [PATCH 04/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 04c76a6..040f29d 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -14,3 +14,6 @@
## 4?5?. track 3 part
+
+
+## References:
From ffe3f21172c427d0e49bb657f951013bb35d48ce Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 17:40:08 +0900
Subject: [PATCH 05/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 5 +----
1 file changed, 1 insertion(+), 4 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 040f29d..7be7fd8 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -2,7 +2,6 @@
# Precision Medicine(lets change to something more descriptive later)
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-### Sections:
##### 1. Introduction to Precision Medicine?
##### 2.
##### 3.
@@ -11,9 +10,7 @@
## 1. Introduction to Precision Medicine
-
-
## 4?5?. track 3 part
-## References:
+## References
From bb56b29e70a0494c2a50628c6a0041a06f20183f Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 18:04:15 +0900
Subject: [PATCH 06/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 8 +++++++-
1 file changed, 7 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 7be7fd8..b2b48bc 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -6,11 +6,17 @@
##### 2.
##### 3.
##### 4. ...
+##### i. Predicting Treatment Response
+##### i+1. Evolving Precision Medicine
+##### Conclusion
## 1. Introduction to Precision Medicine
-## 4?5?. track 3 part
+## i. Predicting Treatment Response
+## i+1. Evolving Precision Medicine
+
+## Conclusion
## References
From c22f8946013fd0691f9f32a3d590c6ca49024043 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 18:05:20 +0900
Subject: [PATCH 07/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index b2b48bc..c7ac72b 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -8,15 +8,15 @@
##### 4. ...
##### i. Predicting Treatment Response
##### i+1. Evolving Precision Medicine
-##### Conclusion
+##### i+2. Conclusion
-## 1. Introduction to Precision Medicine
+## 1. Introduction to Precision Medicine?
## i. Predicting Treatment Response
## i+1. Evolving Precision Medicine
-## Conclusion
+## i+2. Conclusion
## References
From e8f018b9b446b920fb76fe4c2a5e4dc31152e915 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 18:11:04 +0900
Subject: [PATCH 08/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 ++
1 file changed, 2 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index c7ac72b..ea1c4c4 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -17,6 +17,8 @@
## i+1. Evolving Precision Medicine
+
+
## i+2. Conclusion
## References
From b702ac1a21d27cfc4a896f3a50c3134a282bcb04 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 23:03:08 +0900
Subject: [PATCH 09/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 13 +++++++++++++
1 file changed, 13 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index ea1c4c4..343c24d 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -15,6 +15,13 @@
## i. Predicting Treatment Response
+After developing diagnostic and prognostic models from the previous step, there is a need of asssessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
+
+- Prediction models can be developed based on the diagonostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
+
+- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were chose and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+
+
## i+1. Evolving Precision Medicine

@@ -22,3 +29,9 @@
## i+2. Conclusion
## References
+
+Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
+
+Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and efficacy of mepolizumab in patients with moderate persistent asthma. Am J Respir Crit Care Med 2007; 176: 1062–1071.
+
+Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
From e577eba0287f8d640c0ec2595258b35d65000764 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 23:05:43 +0900
Subject: [PATCH 10/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 343c24d..f3f1641 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -19,7 +19,7 @@ After developing diagnostic and prognostic models from the previous step, there
- Prediction models can be developed based on the diagonostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
-- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were chose and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
## i+1. Evolving Precision Medicine
From 798d1073a33d01df5ed92988c38bae706ff66d67 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 23:17:23 +0900
Subject: [PATCH 11/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 5 ++++-
1 file changed, 4 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index f3f1641..db3107f 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -17,10 +17,13 @@
After developing diagnostic and prognostic models from the previous step, there is a need of asssessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
-- Prediction models can be developed based on the diagonostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
+- Prediction models can be built on the diagonostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+This process of building prediction models involves generating further knowledge about the disease and treatment from the diagonotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjusted for the clinical trial that could more precisely show the effectiveness of the treatment.
+
+In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
## i+1. Evolving Precision Medicine
From 6e0c2a011a5612987b818893bffce4b8ce8d5cde Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 23:39:16 +0900
Subject: [PATCH 12/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 17 +++++++++++++++--
1 file changed, 15 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index db3107f..ed57bcb 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -10,14 +10,14 @@
##### i+1. Evolving Precision Medicine
##### i+2. Conclusion
-## 1. Introduction to Precision Medicine?
+## 1. Intro part
## i. Predicting Treatment Response
After developing diagnostic and prognostic models from the previous step, there is a need of asssessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
-- Prediction models can be built on the diagonostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
+- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
@@ -27,8 +27,18 @@ In addition to the feedback, dissemination and communication of the taxonomy and
## i+1. Evolving Precision Medicine
+The figure below shows cycles of precision medicine and its subsequent result.
+

+As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagonotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at higher resolution.
+
+The detailed steps are as follows:
+
+1. In the first cycles, categorize patients into diagnostic/prognostic groups based on obvious charateristics.
+2. In later cycles, define more specific groups of patients using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
+3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
+
## i+2. Conclusion
## References
@@ -38,3 +48,6 @@ Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS
Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and efficacy of mepolizumab in patients with moderate persistent asthma. Am J Respir Crit Care Med 2007; 176: 1062–1071.
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
+
+Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
+European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
From 6824496ed9e09f8d58146dd1ad84f4180cb47c8f Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 23:44:00 +0900
Subject: [PATCH 13/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index ed57bcb..b100506 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -27,7 +27,7 @@ In addition to the feedback, dissemination and communication of the taxonomy and
## i+1. Evolving Precision Medicine
-The figure below shows cycles of precision medicine and its subsequent result.
+The figure below shows cycles of precision medicine and its subsequent outcome.

@@ -39,6 +39,8 @@ The detailed steps are as follows:
2. In later cycles, define more specific groups of patients using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
+
+
## i+2. Conclusion
## References
From 13e36016cdee529e1bbdf77a7ef6b81476d443bd Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sat, 12 Dec 2020 23:51:45 +0900
Subject: [PATCH 14/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 10 +++++++---
1 file changed, 7 insertions(+), 3 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index b100506..7a16128 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -21,6 +21,10 @@ After developing diagnostic and prognostic models from the previous step, there
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+Below is an illustration of applying different treatment to categorized groups to increase efficiency of a treatment based on prection models.
+
+
+
This process of building prediction models involves generating further knowledge about the disease and treatment from the diagonotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjusted for the clinical trial that could more precisely show the effectiveness of the treatment.
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
@@ -29,7 +33,7 @@ In addition to the feedback, dissemination and communication of the taxonomy and
The figure below shows cycles of precision medicine and its subsequent outcome.
-
+
As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagonotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at higher resolution.
@@ -39,10 +43,10 @@ The detailed steps are as follows:
2. In later cycles, define more specific groups of patients using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
-
-
## i+2. Conclusion
+
+
## References
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
From c8aef18fbed4b4301cd625625dfcf58612161ca8 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:08:53 +0900
Subject: [PATCH 15/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 7 +++++--
1 file changed, 5 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 7a16128..65e8ef3 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,5 +1,5 @@
-# Precision Medicine(lets change to something more descriptive later)
+# Precision Medicine(change to something more descriptive later)
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
##### 1. Introduction to Precision Medicine?
@@ -21,7 +21,7 @@ After developing diagnostic and prognostic models from the previous step, there
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
-Below is an illustration of applying different treatment to categorized groups to increase efficiency of a treatment based on prection models.
+Below is an illustration of applying different treatment, as known as "tailored medicine", to categorized groups to increase efficiency of treatment based on a prediction model.

@@ -57,3 +57,6 @@ Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of ref
Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
+
+the image-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
+https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
From 3cbe676cabe25c0d95c0b6b0773b0a915dc9ad2d Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:09:57 +0900
Subject: [PATCH 16/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 65e8ef3..14c5b45 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -21,7 +21,7 @@ After developing diagnostic and prognostic models from the previous step, there
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
-Below is an illustration of applying different treatment, as known as "tailored medicine", to categorized groups to increase efficiency of treatment based on a prediction model.
+Below is an illustration of applying different treatment, also known as "tailored medicine", to categorized groups to increase efficiency of treatment based on a prediction model.

From c039881f0b0c4439e9ace4699a60875fd6c2ac64 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:15:01 +0900
Subject: [PATCH 17/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 21 +++++++++----------
1 file changed, 10 insertions(+), 11 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 14c5b45..a73d55b 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -2,18 +2,17 @@
# Precision Medicine(change to something more descriptive later)
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-##### 1. Introduction to Precision Medicine?
-##### 2.
-##### 3.
-##### 4. ...
-##### i. Predicting Treatment Response
-##### i+1. Evolving Precision Medicine
-##### i+2. Conclusion
+1. [Introduction](#1)
+...
+5. [Predicting Treatment Response](#5)
+6. [Evolving Precision Medicine](#6)
+7. [Conclusion](#7)
-## 1. Intro part
+## 1. Intro part
-## i. Predicting Treatment Response
+
+## 5. Predicting Treatment Response
After developing diagnostic and prognostic models from the previous step, there is a need of asssessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
@@ -29,7 +28,7 @@ This process of building prediction models involves generating further knowledge
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
-## i+1. Evolving Precision Medicine
+## 6. Evolving Precision Medicine
The figure below shows cycles of precision medicine and its subsequent outcome.
@@ -43,7 +42,7 @@ The detailed steps are as follows:
2. In later cycles, define more specific groups of patients using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
-## i+2. Conclusion
+## 7. Conclusion
From c2f3436180e6a6a61b8c8e82fb672d87ef2dce45 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:23:01 +0900
Subject: [PATCH 18/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 23 +++++++++++--------
1 file changed, 14 insertions(+), 9 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index a73d55b..09cc1bb 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -2,17 +2,22 @@
# Precision Medicine(change to something more descriptive later)
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-1. [Introduction](#1)
-...
-5. [Predicting Treatment Response](#5)
-6. [Evolving Precision Medicine](#6)
-7. [Conclusion](#7)
+1. [Intro?](#1)
+2. [blah](#2)
+3. [Data Analysis](#3)
+ 3.1. [Preprocessing and Data Mining](#31)
+ 3.2. [Diagnostic and Prognostic Models](#32)
+ 3.3. [Predicting Treatment Response](#33)
+4. [Evolving Precision Medicine](#4)
+5. [Conclusion](#5)
## 1. Intro part
-
-## 5. Predicting Treatment Response
+## 3. Data Analysis
+#### 1)
+#### 2)
+#### 3) Predicting Treatment Response
After developing diagnostic and prognostic models from the previous step, there is a need of asssessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
@@ -28,7 +33,7 @@ This process of building prediction models involves generating further knowledge
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
-## 6. Evolving Precision Medicine
+## 4. Evolving Precision Medicine
The figure below shows cycles of precision medicine and its subsequent outcome.
@@ -42,7 +47,7 @@ The detailed steps are as follows:
2. In later cycles, define more specific groups of patients using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
-## 7. Conclusion
+## 5. Conclusion
From 15b6cc148d356caeb9c90e99d4f381cc9e36f30c Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:24:45 +0900
Subject: [PATCH 19/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 09cc1bb..eaf1d31 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -3,7 +3,8 @@
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
1. [Intro?](#1)
-2. [blah](#2)
+2. [sth about deep phenotyping?](#2)
+feel free to add more sections!
3. [Data Analysis](#3)
3.1. [Preprocessing and Data Mining](#31)
3.2. [Diagnostic and Prognostic Models](#32)
From b283897e4d9e5e9579a139087baa2d8254a4d76a Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:26:33 +0900
Subject: [PATCH 20/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index eaf1d31..774dce1 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -11,9 +11,10 @@ feel free to add more sections!
3.3. [Predicting Treatment Response](#33)
4. [Evolving Precision Medicine](#4)
5. [Conclusion](#5)
+6. [Reference](#6)
-## 1. Intro part
+## 1. Intro?
## 3. Data Analysis
#### 1)
@@ -52,7 +53,7 @@ The detailed steps are as follows:
-## References
+## 6. References
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
From 5c184b698ef3d84d4b9b12c8a209e326293e42d4 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:40:30 +0900
Subject: [PATCH 21/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 7 +++++--
1 file changed, 5 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 774dce1..218918e 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -11,7 +11,7 @@ feel free to add more sections!
3.3. [Predicting Treatment Response](#33)
4. [Evolving Precision Medicine](#4)
5. [Conclusion](#5)
-6. [Reference](#6)
+ 5.1. [Reference](#51)
## 1. Intro?
@@ -51,9 +51,12 @@ The detailed steps are as follows:
## 5. Conclusion
+As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady state or a specific output from the research with an endpoint.
+Once again, the ultimate goal of precision medicine is the most effective treatment for
+the individual and to get closer to this goal, the efforts to be even more precise and individualistic are ongoing.
-## 6. References
+#### 1) References
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
From e40b167b2806a21864e9d857b8e5d9b030248222 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:41:28 +0900
Subject: [PATCH 22/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 218918e..206c58a 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -11,7 +11,7 @@ feel free to add more sections!
3.3. [Predicting Treatment Response](#33)
4. [Evolving Precision Medicine](#4)
5. [Conclusion](#5)
- 5.1. [Reference](#51)
+6. [Reference](#6)
## 1. Intro?
@@ -56,7 +56,7 @@ As seen in the previous section on the continual evolution of precision medicine
Once again, the ultimate goal of precision medicine is the most effective treatment for
the individual and to get closer to this goal, the efforts to be even more precise and individualistic are ongoing.
-#### 1) References
+## 6. References
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
From 23b19a253083bab6435b48e6f42bc237802d50bc Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:49:52 +0900
Subject: [PATCH 23/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 206c58a..7aabe5e 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -51,10 +51,10 @@ The detailed steps are as follows:
## 5. Conclusion
-As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady state or a specific output from the research with an endpoint.
+As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady state or a specific output from the research with an endpoint. In this context, tailored medicine from resulting from new strafications can be considerd as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for
-the individual and to get closer to this goal, the efforts to be even more precise and individualistic are ongoing.
+the individual. To step closer to this goal, the ongoing efforts to be even more precise and individualistic, newly-gained knowledge, and new data sources would be necessary.
## 6. References
From 70ce76e29d2493a4ccc79a0f0e026ade6ed369f9 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:55:00 +0900
Subject: [PATCH 24/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 10 +++++-----
1 file changed, 5 insertions(+), 5 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 7aabe5e..41bb9a2 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,5 +1,5 @@
-# Precision Medicine(change to something more descriptive later)
+# The Process of Precision Medicine
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
1. [Intro?](#1)
@@ -45,16 +45,16 @@ As seen in the figure, the cycle of patients assessment(deep phenotyping), data
The detailed steps are as follows:
-1. In the first cycles, categorize patients into diagnostic/prognostic groups based on obvious charateristics.
-2. In later cycles, define more specific groups of patients using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
+1. In the first cycles, patients are categorized into diagnostic/prognostic groups based on obvious charateristics.
+2. In later cycles, more specific groups of patients are defined using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
## 5. Conclusion
-As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady state or a specific output from the research with an endpoint. In this context, tailored medicine from resulting from new strafications can be considerd as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady state with an end-point or a specific output from the research. In this context, tailored or stratified medicine from resulting from new strafications can be considerd as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for
-the individual. To step closer to this goal, the ongoing efforts to be even more precise and individualistic, newly-gained knowledge, and new data sources would be necessary.
+the individual patient. To step closer to this goal, an ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
## 6. References
From 8cbf914e36395b2eef6d09da1f5917da43d9680e Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 00:55:35 +0900
Subject: [PATCH 25/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 41bb9a2..06d6820 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -56,7 +56,7 @@ As seen in the previous section on the continual evolution of precision medicine
Once again, the ultimate goal of precision medicine is the most effective treatment for
the individual patient. To step closer to this goal, an ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
-## 6. References
+## 6. Reference
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
From 7aa451c9904a99281c7b5e9b133e9ed71438aaba Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 01:01:36 +0900
Subject: [PATCH 26/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 21 +++++++++----------
1 file changed, 10 insertions(+), 11 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 06d6820..564d39c 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -21,17 +21,17 @@ feel free to add more sections!
#### 2)
#### 3) Predicting Treatment Response
-After developing diagnostic and prognostic models from the previous step, there is a need of asssessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
+After developing diagnostic and prognostic models from the previous step, there is a need for assessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
-- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with nonsmall cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later aftering sorting&numbering sources].
+- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with non-small cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later after sorting&numbering sources].
-- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reductionin blood and sputum eosinophils, but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
-Below is an illustration of applying different treatment, also known as "tailored medicine", to categorized groups to increase efficiency of treatment based on a prediction model.
+Below is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the efficiency of treatment based on a prediction model.

-This process of building prediction models involves generating further knowledge about the disease and treatment from the diagonotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjusted for the clinical trial that could more precisely show the effectiveness of the treatment.
+This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjusted for the clinical trial that could more precisely show the effectiveness of the treatment.
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
@@ -41,20 +41,19 @@ The figure below shows cycles of precision medicine and its subsequent outcome.

-As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagonotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at higher resolution.
+As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
The detailed steps are as follows:
-1. In the first cycles, patients are categorized into diagnostic/prognostic groups based on obvious charateristics.
+1. In the first cycles, patients are categorized into diagnostic/prognostic groups based on obvious characteristics.
2. In later cycles, more specific groups of patients are defined using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
-3. Eventually, this feedback loops may allow the final cycles to target individual patient with specific data profile.
+3. Eventually, these feedback loops may allow the final cycles to target individual patients with specific data profiles.
## 5. Conclusion
-As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady state with an end-point or a specific output from the research. In this context, tailored or stratified medicine from resulting from new strafications can be considerd as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
-Once again, the ultimate goal of precision medicine is the most effective treatment for
-the individual patient. To step closer to this goal, an ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
+Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
## 6. Reference
From fd72c5e593e007e45c4ce88dfe5749fa741c24b8 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 01:09:12 +0900
Subject: [PATCH 27/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 564d39c..327c116 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -51,7 +51,7 @@ The detailed steps are as follows:
## 5. Conclusion
-As seen in the previous section on the continual evolution of precision medicine, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which were composed of preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
From d49a1e6a9ae99a383c528dd6466f7b83e066cccc Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 01:10:35 +0900
Subject: [PATCH 28/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 327c116..a7d2e6d 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -51,7 +51,7 @@ The detailed steps are as follows:
## 5. Conclusion
-In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which were composed of preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
From adc6af02f81c08b2e0707e5b273858a9f184651e Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Sun, 13 Dec 2020 01:12:26 +0900
Subject: [PATCH 29/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index a7d2e6d..608eb2d 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -51,7 +51,7 @@ The detailed steps are as follows:
## 5. Conclusion
-In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed (against the background of airway diseases-remove this part if we don't discuss the asthma example). As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
From 927ca66428637e5640ef72d00b6f9fe2942d5203 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Mon, 14 Dec 2020 17:39:49 +0900
Subject: [PATCH 30/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 13 +++++++++----
1 file changed, 9 insertions(+), 4 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 608eb2d..41ef308 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -2,9 +2,8 @@
# The Process of Precision Medicine
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-1. [Intro?](#1)
-2. [sth about deep phenotyping?](#2)
-feel free to add more sections!
+1. [Introduction](#1)
+2. [Deep Phenotyping](#2)
3. [Data Analysis](#3)
3.1. [Preprocessing and Data Mining](#31)
3.2. [Diagnostic and Prognostic Models](#32)
@@ -14,7 +13,13 @@ feel free to add more sections!
6. [Reference](#6)
-## 1. Intro?
+## 1. Introduction
+#### 1) Definition of precision medicine
+Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' The focus of applied definitions is moving away from classical 'signs-and-symptoms' approach or 'population approach' into 'N of 1 approach' in which each patient is an entire trial as a single case study from N number of individuals within a population.
+
+## 2. Deep Phenotyping
+#### 1) Deep phenotyping as process
+#### 2) Processing deep phenotyping data
## 3. Data Analysis
#### 1)
From 6c0d78148174b2f3df6d77a46c3de08a9738fd42 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Mon, 14 Dec 2020 17:55:55 +0900
Subject: [PATCH 31/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 41ef308..5fd0b9d 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -14,6 +14,9 @@
## 1. Introduction
+
+(EDIT!) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
+
#### 1) Definition of precision medicine
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' The focus of applied definitions is moving away from classical 'signs-and-symptoms' approach or 'population approach' into 'N of 1 approach' in which each patient is an entire trial as a single case study from N number of individuals within a population.
From 71d0d7d4a7c061caa105843afc5c3335597083b0 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Mon, 14 Dec 2020 18:52:53 +0900
Subject: [PATCH 32/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 5fd0b9d..a031ed5 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -63,7 +63,7 @@ In this paper, the process of precision medicine, starting from the deep phenoty
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
-## 6. Reference
+## 6. References
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
From 919cfca30ea4159c91f9d5595177ecbb891d6f2b Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Mon, 14 Dec 2020 18:53:07 +0900
Subject: [PATCH 33/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index a031ed5..1fce155 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -10,7 +10,7 @@
3.3. [Predicting Treatment Response](#33)
4. [Evolving Precision Medicine](#4)
5. [Conclusion](#5)
-6. [Reference](#6)
+6. [References](#6)
## 1. Introduction
From cb9aaa5272c23f8610dd0506e4d8d276b7bb629a Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Mon, 14 Dec 2020 19:04:09 +0900
Subject: [PATCH 34/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 ++
1 file changed, 2 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 1fce155..b675cd1 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -76,3 +76,5 @@ European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.003
the image-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
+
+National Research Council, Committee on A Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. National Academies Press; Washington DC: 2011.
From aa3004c25c56048a920739b61d242de8221becba Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Mon, 14 Dec 2020 21:42:35 +0900
Subject: [PATCH 35/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index b675cd1..0900d18 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -18,6 +18,9 @@
(EDIT!) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
#### 1) Definition of precision medicine
+
+
+
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' The focus of applied definitions is moving away from classical 'signs-and-symptoms' approach or 'population approach' into 'N of 1 approach' in which each patient is an entire trial as a single case study from N number of individuals within a population.
## 2. Deep Phenotyping
From ee249b8134bd2cd469c6cd8306d16bdd19a1ad46 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 00:13:06 +0900
Subject: [PATCH 36/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 1 +
1 file changed, 1 insertion(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 0900d18..f7ae9f1 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -25,6 +25,7 @@ Precision medicine is personalized treatment strategies on the basis of genetic,
## 2. Deep Phenotyping
#### 1) Deep phenotyping as process
+
#### 2) Processing deep phenotyping data
## 3. Data Analysis
From 02e871521d1e2435729f8d144fc76833672fd125 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 01:34:52 +0900
Subject: [PATCH 37/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 38 +++++++++++++++----
1 file changed, 31 insertions(+), 7 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index f7ae9f1..5272d33 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -15,18 +15,42 @@
## 1. Introduction
-(EDIT!) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
+(TODO) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
-#### 1) Definition of precision medicine
+#### 1) What is Precision Medicine?
-
+Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' [1,4]
-Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' The focus of applied definitions is moving away from classical 'signs-and-symptoms' approach or 'population approach' into 'N of 1 approach' in which each patient is an entire trial as a single case study from N number of individuals within a population.
+The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information. [3]
+
+
+Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
+
+#### 2) Framework off Precision Medicine Process
+
+(TODO)The framework of precision medicine is number of feedback loops, with no steady-end point. Each cycle is further trimming of patients for optimal treatment.
+
+
+(TODO) FIgure2 Description
## 2. Deep Phenotyping
-#### 1) Deep phenotyping as process
-
-#### 2) Processing deep phenotyping data
+#### 1) Importance of Phenotype
+
+The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests. [3]
+
+This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. [3] To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. [2] Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.
+
+
+Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
+
+#### 2) Why "Deep" Phenotyping?
+
+The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. [3] Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles. [5]
+
+
+Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
+
+#### 3) Processing Deep Phenotyping Data
## 3. Data Analysis
#### 1)
From f2f8f88217f5906108e251ac58a6d2ac38bc4632 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 01:36:45 +0900
Subject: [PATCH 38/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 5272d33..c18267e 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -2,7 +2,7 @@
# The Process of Precision Medicine
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-1. [Introduction](#1)
+1. [What is Precision Medicine?](#1)
2. [Deep Phenotyping](#2)
3. [Data Analysis](#3)
3.1. [Preprocessing and Data Mining](#31)
@@ -13,11 +13,11 @@
6. [References](#6)
-## 1. Introduction
+## 1. What is Precision Medicine?
(TODO) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
-#### 1) What is Precision Medicine?
+#### 1) Definition
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' [1,4]
@@ -26,7 +26,7 @@ The focus of applied definitions is moving away from classical 'signs-and-sympto

Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
-#### 2) Framework off Precision Medicine Process
+#### 2) Framework of Precision Medicine Process
(TODO)The framework of precision medicine is number of feedback loops, with no steady-end point. Each cycle is further trimming of patients for optimal treatment.
From f782f1182b0760266d83cf170a7b261fcdb09e3e Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 01:38:13 +0900
Subject: [PATCH 39/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 14 +++++++-------
1 file changed, 7 insertions(+), 7 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index c18267e..401125c 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -17,7 +17,7 @@
(TODO) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
-#### 1) Definition
+### 1) Definition
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' [1,4]
@@ -34,7 +34,7 @@ Figure 1: In the left diagram, colon cancer patients are clustered into one grou
(TODO) FIgure2 Description
## 2. Deep Phenotyping
-#### 1) Importance of Phenotype
+### 1) Importance of Phenotype
The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests. [3]
@@ -43,19 +43,19 @@ This is where precise phenotype information comes into play. As physician makes

Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
-#### 2) Why "Deep" Phenotyping?
+### 2) Why "Deep" Phenotyping?
The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. [3] Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles. [5]

Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
-#### 3) Processing Deep Phenotyping Data
+### 3) Processing Deep Phenotyping Data
## 3. Data Analysis
-#### 1)
-#### 2)
-#### 3) Predicting Treatment Response
+### 1)
+### 2)
+### 3) Predicting Treatment Response
After developing diagnostic and prognostic models from the previous step, there is a need for assessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
From 7ac21aabd2add1e4d8afa247e0e12a09eb1ea4ea Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 01:40:58 +0900
Subject: [PATCH 40/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 5 ++++-
1 file changed, 4 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 401125c..69127fa 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -26,11 +26,12 @@ The focus of applied definitions is moving away from classical 'signs-and-sympto

Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
-#### 2) Framework of Precision Medicine Process
+### 2) Framework of Precision Medicine Process
(TODO)The framework of precision medicine is number of feedback loops, with no steady-end point. Each cycle is further trimming of patients for optimal treatment.

+
(TODO) FIgure2 Description
## 2. Deep Phenotyping
@@ -41,6 +42,7 @@ The word phenotype can be used differently in biology versus medicine. In biolog
This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. [3] To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. [2] Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.

+
Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
### 2) Why "Deep" Phenotyping?
@@ -48,6 +50,7 @@ Figure 3: Individuals with the same endophenotype, such as hypertension, can hav
The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. [3] Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles. [5]

+
Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
### 3) Processing Deep Phenotyping Data
From 0d5650ef6dd7f31acfddef40542b9de9d0616212 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 01:44:09 +0900
Subject: [PATCH 41/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 9 +++++----
1 file changed, 5 insertions(+), 4 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 69127fa..3e36b1c 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -24,7 +24,8 @@ Precision medicine is personalized treatment strategies on the basis of genetic,
The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information. [3]

-Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
+
+##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
### 2) Framework of Precision Medicine Process
@@ -32,7 +33,7 @@ Figure 1: In the left diagram, colon cancer patients are clustered into one grou

-(TODO) FIgure2 Description
+###### (TODO) Figure 2 Description
## 2. Deep Phenotyping
### 1) Importance of Phenotype
@@ -43,7 +44,7 @@ This is where precise phenotype information comes into play. As physician makes

-Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
+##### Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
### 2) Why "Deep" Phenotyping?
@@ -51,7 +52,7 @@ The major problem with current phenotyping regime is sloppy or imprecise descrip

-Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
+##### Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
### 3) Processing Deep Phenotyping Data
From 5c389af64566cef4e7612ae1d136244a02c29a89 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 01:51:11 +0900
Subject: [PATCH 42/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 25 +++++++++++--------
1 file changed, 15 insertions(+), 10 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 3e36b1c..d9e25c8 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -19,9 +19,9 @@
### 1) Definition
-Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.' [1,4]
+Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
-The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information. [3]
+The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.

@@ -38,9 +38,9 @@ The focus of applied definitions is moving away from classical 'signs-and-sympto
## 2. Deep Phenotyping
### 1) Importance of Phenotype
-The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests. [3]
+The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests.
-This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. [3] To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. [2] Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.
+This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.

@@ -48,7 +48,7 @@ This is where precise phenotype information comes into play. As physician makes
### 2) Why "Deep" Phenotyping?
-The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. [3] Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles. [5]
+The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles.

@@ -96,6 +96,16 @@ In this paper, the process of precision medicine, starting from the deep phenoty
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
## 6. References
+Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
+European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
+
+Ginsburg GS, Phillips KA. Precision Medicine: From Science To Value. Health Aff (Millwood). 2018 May;37(5):694-701. doi: 10.1377/hlthaff.2017.1624. PMID: 29733705; PMCID: PMC5989714.
+
+Robinson PN. Deep phenotyping for precision medicine. Hum Mutat. 2012 May;33(5):777-80. doi: 10.1002/humu.22080. PMID: 22504886.
+
+National Research Council, Committee on A Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. National Academies Press; Washington DC: 2011.
+
+Leopold JA, Loscalzo J. Emerging Role of Precision Medicine in Cardiovascular Disease. Circ Res. 2018;122(9):1302-1315. doi:10.1161/CIRCRESAHA.117.310782
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
@@ -103,10 +113,5 @@ Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and effi
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
-Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
-European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
-
the image-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
-
-National Research Council, Committee on A Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. National Academies Press; Washington DC: 2011.
From bf3b7b01f9f7fadf46df0bff99bd1eb80577cf7b Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 03:21:43 +0900
Subject: [PATCH 43/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 6 ++++--
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index d9e25c8..8f2547b 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -29,11 +29,11 @@ The focus of applied definitions is moving away from classical 'signs-and-sympto
### 2) Framework of Precision Medicine Process
-(TODO)The framework of precision medicine is number of feedback loops, with no steady-end point. Each cycle is further trimming of patients for optimal treatment.
+The framework of precision medicine is a process made up of number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and results of these analyses then inform the further assessment of patients as an evolving result.

-###### (TODO) Figure 2 Description
+###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
## 2. Deep Phenotyping
### 1) Importance of Phenotype
@@ -56,6 +56,8 @@ The major problem with current phenotyping regime is sloppy or imprecise descrip
### 3) Processing Deep Phenotyping Data
+Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
+
## 3. Data Analysis
### 1)
### 2)
From 3b1cd126b8c968cb2b04e4ef807be8ef0d52a4d2 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 03:23:07 +0900
Subject: [PATCH 44/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 --
1 file changed, 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 8f2547b..13f1160 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -15,8 +15,6 @@
## 1. What is Precision Medicine?
-(TODO) Most medical treatments are designed for the "average patient" as a one-size-fits-all-approach, which may be successful for some patients but not for others.
-
### 1) Definition
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
From 6fd24f8ae511a6adc1ab7dbee4083528b8141359 Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Tue, 15 Dec 2020 03:30:00 +0900
Subject: [PATCH 45/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 9 +++++++--
1 file changed, 7 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 13f1160..6bf8cb7 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -2,8 +2,13 @@
# The Process of Precision Medicine
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-1. [What is Precision Medicine?](#1)
-2. [Deep Phenotyping](#2)
+1. [What is Precision Medicine?](#1)
+ 1.1. [Definition](#11)
+ 1.2. [Framework of Precision Medicine Process](#12)
+2. [Deep Phenotyping](#2)
+ 2.1. [Importance of Phenotype](#21)
+ 2.2. [Why "Deep" Phenotyping?](#22)
+ 2.3. [Processing Deep Phenotyping Data](#23)
3. [Data Analysis](#3)
3.1. [Preprocessing and Data Mining](#31)
3.2. [Diagnostic and Prognostic Models](#32)
From f21ea96f106542e5d733c1461eacb731f7f284c3 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Tue, 15 Dec 2020 10:05:18 +0900
Subject: [PATCH 46/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 14 ++++++--------
1 file changed, 6 insertions(+), 8 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 6bf8cb7..42a2632 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -72,19 +72,17 @@ After developing diagnostic and prognostic models from the previous step, there
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
-Below is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the efficiency of treatment based on a prediction model.
-

+##### Figure 4: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
-This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjusted for the clinical trial that could more precisely show the effectiveness of the treatment.
+This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
## 4. Evolving Precision Medicine
-The figure below shows cycles of precision medicine and its subsequent outcome.
-

+##### Figure 5: The figure above shows repeated cycles of precision medicine and its subsequent outcome.
As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
@@ -96,9 +94,9 @@ The detailed steps are as follows:
## 5. Conclusion
-In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed (against the background of airway diseases-remove this part if we don't discuss the asthma example). As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
-Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing efforts to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
+Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing endeavors to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
## 6. References
Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
@@ -118,5 +116,5 @@ Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and effi
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
-the image-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
+the image- might not use-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
From 2f0462a18ac375af4ccc0a27a854bb904a9a4ddc Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Tue, 15 Dec 2020 10:07:04 +0900
Subject: [PATCH 47/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 42a2632..9accbfa 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -81,8 +81,8 @@ In addition to the feedback, dissemination and communication of the taxonomy and
## 4. Evolving Precision Medicine
+##### Figure 5: The figure below shows repeated cycles of precision medicine and its subsequent outcome.

-##### Figure 5: The figure above shows repeated cycles of precision medicine and its subsequent outcome.
As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
From 6c09d1d230c3ea4bb94be91b89a14fd2f28d28e5 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Tue, 15 Dec 2020 10:08:24 +0900
Subject: [PATCH 48/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 9accbfa..23fefa9 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -73,7 +73,7 @@ After developing diagnostic and prognostic models from the previous step, there
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].

-##### Figure 4: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
+##### Figure 5: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
@@ -81,7 +81,7 @@ In addition to the feedback, dissemination and communication of the taxonomy and
## 4. Evolving Precision Medicine
-##### Figure 5: The figure below shows repeated cycles of precision medicine and its subsequent outcome.
+##### Figure 6: The figure below shows repeated cycles of precision medicine and its subsequent outcome.

As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
From e89acf2d3841295cae77920676f4ca8c1c499c3a Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Wed, 16 Dec 2020 01:39:57 +0900
Subject: [PATCH 49/94] Update Precision_Medicine.md
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 9 +++++----
1 file changed, 5 insertions(+), 4 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 23fefa9..c7430d7 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -24,21 +24,22 @@
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
-The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
+The focus is to move away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial or a single case study from N number of individuals within a population. Figure 1 shows the difference between classical approach and precision medicine approach. Ultimately, comprehensive study of such subclasses depends on computational resources to capture, store and exchange phenotypic data and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.

-##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
+##### Figure 1: The left diagram shows treatment based on 'signs-and-symptoms' research. Patients with colon cancer are clustered into one group and given the same therapy, which thereby varies in treatment responses. Treatment has worked for some individuals while it had no or adverse effect for other. This is because this approach does not take patients' phenoytpic information into account. On the right, the same group of patients have been divided into subgroups based on individual phenotypic recognition, resulting in better understanding of the causal pathways and better treatment responses.
### 2) Framework of Precision Medicine Process
-The framework of precision medicine is a process made up of number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and results of these analyses then inform the further assessment of patients as an evolving result.
+At the highest level, precision medicine process is a framework made up of feedback loops, with no steady-end point. Each cycle is an attempt to sort out and validate the process and stratify the subgroups further. The data assessed in the patients are used to try to develop clinically relevant models, and analyses inform need for further assessment of patients as an evolving result.

-###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
+###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
## 2. Deep Phenotyping
+
### 1) Importance of Phenotype
The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests.
From b7f76e66aae396e27df9063152ece3eb6e5756bd Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Wed, 16 Dec 2020 02:53:02 +0900
Subject: [PATCH 50/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index c7430d7..5dc6604 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,6 +1,7 @@
# The Process of Precision Medicine
-### by Soyeon Kim, Hwayeon Lee, Meixian Wu
+### Authors: Soyeon Kim, Hwayeon Lee, Meixian Wu
+### BENG 183 Applied Genomic Technologies
1. [What is Precision Medicine?](#1)
1.1. [Definition](#11)
From d94479fce00c00580bbf6152cab074d85af22e2f Mon Sep 17 00:00:00 2001
From: hyl023 <71542168+hyl023@users.noreply.github.com>
Date: Wed, 16 Dec 2020 02:54:11 +0900
Subject: [PATCH 51/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 5dc6604..f8d0152 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,8 +1,9 @@
# The Process of Precision Medicine
### Authors: Soyeon Kim, Hwayeon Lee, Meixian Wu
-### BENG 183 Applied Genomic Technologies
+#### BENG 183 Applied Genomic Technologies
+## Table of Contents
1. [What is Precision Medicine?](#1)
1.1. [Definition](#11)
1.2. [Framework of Precision Medicine Process](#12)
From 403e3aeec47d1e29bc50b2b5120a821863d5934b Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 12:56:02 -0800
Subject: [PATCH 52/94] add track1&2
---
.DS_Store | Bin 0 -> 10244 bytes
finalPaper/.DS_Store | Bin 0 -> 10244 bytes
.../Grup25_Precision_Medicine/.DS_Store | Bin 0 -> 6148 bytes
.../Precision_Medicine.md | 227 ++++++++++++++++--
4 files changed, 205 insertions(+), 22 deletions(-)
create mode 100644 .DS_Store
create mode 100644 finalPaper/.DS_Store
create mode 100644 finalPaper/Grup25_Precision_Medicine/.DS_Store
diff --git a/.DS_Store b/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..9d1a5bac95ae28c033ab686e18709c91cae63dd8
GIT binary patch
literal 10244
zcmeHMUu+ab82`RfV5Wd77$qh?2>y==F&HI=2YunuXf*N3_|483TTGi|!QQND!{Yk&vVcX_#SxxRY^g^#Pz0I~<)v)xe=WJ*?HR%;juDvdhWGQbaYogK5ClW&utRJ>3G<+~y%oKFh1Z{M-AS5b0~zE3w*
z*U0N})zzI|WvWByw5M!qZ&uF}5?v|V%%v@|RHsxkm7~Ub%rq0mDc$LI^%Jfr9dzuh
z+vYXwHpo}#dX;Iye^16WY|GiNXC0E9Uz|K6ym0Zd#^w$8$FEJfXR5-d@#$T8!!eSk
z-dQj-xBr0Zq;yL&tiFSUuH_oX3_Z)M@eJ><)Uv#)OcJQve9IjMuPpji9I1|l+L-bgJ0fE5
zR2_FuMz<)uH@ce8R>lqpOH9*rjnzi$B{@6IF2XzT0ek|V!WZx*T!riK1Kfn4;TQN7euF=7A~LMPNjMu9;6kj$mAD>T@IKs#
zG2D(ja2M{z1oq%z?8T#a3~kI{79AYGNAOX69G}2v@Fjd1&*Llj7QTn?<0ZU|SMV$R
z8o!rsSW%?-E?F<;c!Nr#Q{2h>^SR>4Xw(gF*}ARuu2A>-WWm?!Y4=W_F~7Ec`Komr
zW5b_x#8)gOl*b`S5|2DZa(JJzoRReHLv!Zxa3^t0KQVGP6#1@96l`LGDWRH3IIIX7
z$?Bpys#XxwWp&BYFjvMAkGa=)#Y!Gl#uH_wb@dv~l}h5Yw61R<>jYx2v~Jo=RuHpJ
znp^9rFQj#D3@(nz#Mj^rxC9>)2d~06a07mXpWt_5UnSmyGl_e1aUO3mJkH?9LIm}}LhwwD<@i9DuPZJ}b#pm#O
z;^c)93~VoQPfC1qEC!bDTsKe8U*hjvqp~$^|Fw(#Q`@o~t>6Aw))5}
zX3q@R2fHB#%fX@j?l?psPJ5qAPlU8`H#|u;1Dvw$0hY|aJ@3+Sf4K8}amT)m_@!w4
zyB^9g0)LsKVFW2aAV45MAV45MAVA&{K;TXwfR*t?
zypJT*rHN9Hblm*-zyt>4pE0lvJX0
a$NvoQuC9Xfe{lXEdHY;?;{AW0|NjJwRLZ#k
literal 0
HcmV?d00001
diff --git a/finalPaper/.DS_Store b/finalPaper/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..ee01f1d4599f1861a7f8947f6e8db1b67bb70fc8
GIT binary patch
literal 10244
zcmeHMTWl0n82~jwzPDCwF{-Blp<}RKoPL*E|&ro!nX9nW!dcv?Zn-gWoNbp
zYPIo(8a2jCjG%%+U&I)FFpBzM6z`f4geWmQ=!=gkYQmHHpE`Fr&-)=q|l
zfP;X8fP;X8fP=ul0RdXG*&|Hl(uo}e90VK$k_fQ*!9#(`CR>hhX-ypzSw{epxs+`^
z^iJmh%g1BOCR>hhX}MCF{PcjfE80g4mA`v$pmt%$bs#cSF7)6bJ>=3-*3^kFtkfm
z1_RP8udbOvRa0V?vnnfOvZqtkWPPwjk884FmE-3MK@bHoAe9Xb)va7!<7sFZuJH`j
z)itcF@vN+E93B>h*_CzcTK7i|9~ruR_>QMpUumYYXEd0})5-W4y=4Ifzkaa+g*9@P
zr5FQV4rtC(2|&M204j=8U9DTTZVO0K+)#EZ;h?DwD88Vn7y)UfLCCiD>e`N&GC(MH
z_UhqyL?caMZ!p{&Cu5~K9QLb66r;;j4w>w&$IxS@*D~x<$(Q8?q$1|OJ!-1DX6#a8
z21!voJ*~vOV9}D=hBdeNE=->>Qxc2BS)Bu_p@zar$Dk^k{oO&MSJ7lu>+7K}qnYXf
zRf&m(cvNiHf)V9H>FhGeHODn?A}>Lz5W3VhDUc^#ynJ5`z`)x!Y?piOd5F}ab2nRz-m}jjL
z8wF{r*g3$v%QM%C>xDwB5xZ!hM5sRo&u(^k1?gj9AFF#?&@i`06^*L5dROk+BnaJ1
z(=5x1EL1dAabj5rR5aD{l*HCu7u3Ld*a$r|nlu=Mhu~p&1dhQeI1R7C+wdWL1fRlZ
za1JiPx9~mu1Xth}_!WM`d=#(%r(zk-#|2n{%WyR|;?1}gn{f+n#WuVZ{kRABVgUE!
z0n{;yF*I-p@43k(-xaQ0i-5tb0<(q+||_1D;%5?G~je
z#B$LxzG<20mhy|Gq_U7^&0THAGK
zr_csLnt#|ngw}J|Mj=Q#%}V#BEovq2yp^ecDyk1IPGXT!8&dJiwv03+OFh&LD9Z!~
z+WFL{VNvXjWm85f9^D&GCAg7sTT(IkE9Io&Qar+NSui0Z`YcWaz(+DdJkgT-!kyNx
zFit!&Nk==yG^}9uyVtASRQ#@VCh@y2ZBE7XdY7GsGk6FNC>&>hJ!*HIj-uz{Q6B5y;Fly?@pwr})qNH)d27-8n>koTO)JKY!l$LSigU+WXopow;{fe~V61
zqoIUG1O0`i^Aj5x{Cw00&2*ZILYPKHFU_mtjgGu8f6vT2wcq7?Urh8ngZfjyb9N=9
z^*`@N)_>=jECN%wp@-f7Z>LCf1pb2vV6M;aYoUfGj@qO9!0y^T6!ueK
z53?KL(sH4QnXr88I-U~jI^Mc*pgjAo!O}O`b|YL`?&N2=leFAP^4t8s?Pq{>cj=t}
O)9=ch^Z)H1@V-^m;4Wg<&0T*E43hX&L&p$$qDprKhvt+--jT7}7np#A3
zem<@ulZcFPQ@L2!n>{z**++&mCkOWA81W14cNZlEfg7;MkzE(HCqgga^y>{tEnwC%0;vJ&^%eQ
zLs35+`xjp>T0
- 1.1. [Definition](#11)
- 1.2. [Framework of Precision Medicine Process](#12)
+
+1.1. [Definition](#11)
+
+1.2. [Framework of Precision Medicine Process](#12)
+
2. [Deep Phenotyping](#2)
- 2.1. [Importance of Phenotype](#21)
- 2.2. [Why "Deep" Phenotyping?](#22)
- 2.3. [Processing Deep Phenotyping Data](#23)
+
+2.1. [Importance of Phenotype](#21)
+
+2.2. [Why "Deep" Phenotyping?](#22)
+
+2.3. [Processing Deep Phenotyping Data](#23)
+
3. [Data Analysis](#3)
- 3.1. [Preprocessing and Data Mining](#31)
- 3.2. [Diagnostic and Prognostic Models](#32)
- 3.3. [Predicting Treatment Response](#33)
+
+3.1. [Preprocessing and Data Mining](#31)
+
+3.2. [Diagnostic and Prognostic Models](#32)
+
+3.3. [Predicting Treatment Response](#33)
+
4. [Evolving Precision Medicine](#4)
+
5. [Conclusion](#5)
+
6. [References](#6)
+
+
+
## 1. What is Precision Medicine?
+
+
### 1) Definition
+
+
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
+
+
The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
+
+

-##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
+
+
+##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
+
+
### 2) Framework of Precision Medicine Process
-The framework of precision medicine is a process made up of number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and results of these analyses then inform the further assessment of patients as an evolving result.
+
+
+The framework of precision medicine is a process made up of number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and results of these analyses then inform the further assessment of patients as an evolving result.
+
+

-###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
+
+
+###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
+
+
## 2. Deep Phenotyping
+
### 1) Importance of Phenotype
+
+
The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests.
-This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.
+
+
+This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.
+
+

+
+
##### Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
+
+
### 2) Why "Deep" Phenotyping?
-The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles.
+
+
+The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles.
+
+

+
+
##### Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
+
+
### 3) Processing Deep Phenotyping Data
-Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
+
+
+Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
+
+
+
## 3. Data Analysis
-### 1)
-### 2)
+
+Large-scale of data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]
+
+
+
+##### Figure 5: An integrated precision medicine framework for heterogeneous data collection, data analysis, knowledge management, and implementation of knowledge and data services.
+
+### 1) Preprocessing and Data Mining
+
+The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing manoeuvres and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in analysis. **Quality Control** and **Preprocessing** of the data shall be preformed in this step. Since quality control is always dependent on the specific data type, more details can be found in paper. [Ferté ]
+
+Some of the common approaches for data preprocessing includes:
+
+1. **Denoising** and Baseline Correction
+
+2. Missing Value Filling
+
+3. Data Out of Range Filtration
+
+4. Data Below the Limits of Detection Filtration
+
+5. **Variable Selection**
+
+
+**Case Example: Denoising + Variable selection**
+
+*The collection of deep phenotyping data usually includes great amount of unselected data, which will inevitably include variables that are irrelevant for later modelling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which can shown in below.*
+
+45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.
+
+
+
+##### Figure 6: Impact of variable selection based on illustration
+
+Variable selection is important for filtering out noise data, yet how to define noise or whether a variable is revevant is always a unanswerable question. One important factor that can guide variable selection is scientifically based *a priori* knowledge about the possibly **biologically relevant variables**.
+
+### 2) Diagnostic and Prognostic Models
+
+After data is ready from track 1 for further training, models can be developed to estimate the risk with absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. Prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]
+
+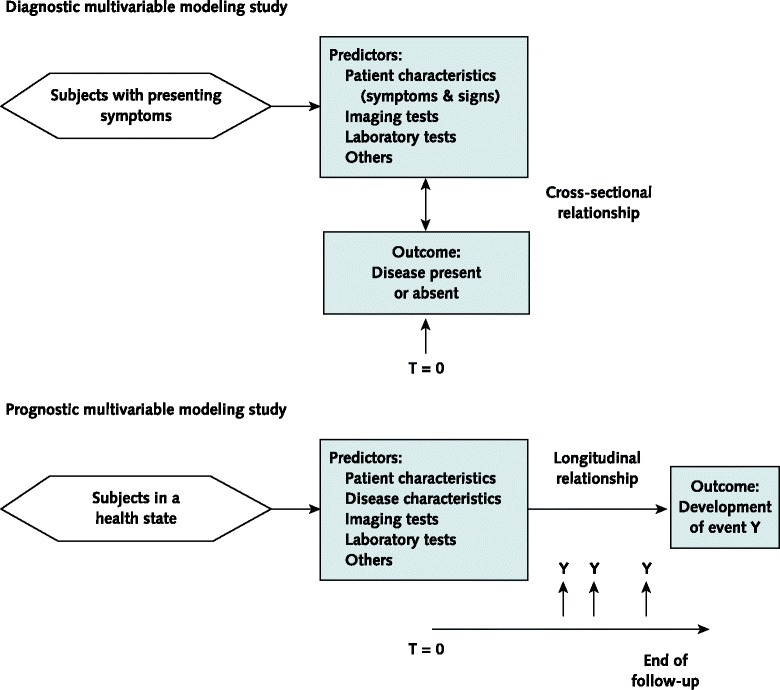
+
+##### Figure 7: Representation of diagnostic and prognostic prediction modeling studies
+
+- Model Development
+Two main strategies are usually used to develop the models:
+
+ 1) **Full Model**
+ No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
+
+ 2) **Variable selection**
+ **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
+
+- Outcome
+The outcome of a prediction aims to reflects a clinically significant and patient relevant health state, for example, death yes or no, or absence or presence of Leukemia. In case of prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
+
+- Clinics-friendly Accommodation
+Regression model can be too complicated to use in daily clinical uses, the model is usually simplify by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively effected the accuracy of the model and thus needs to be applied carefully.
+
+
### 3) Predicting Treatment Response
+
+
After developing diagnostic and prognostic models from the previous step, there is a need for assessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
+
+
- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with non-small cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later after sorting&numbering sources].
+
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+
+

+
##### Figure 5: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
-This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
+
+
+This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
+
+
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
+
+
## 4. Evolving Precision Medicine
+
+
##### Figure 6: The figure below shows repeated cycles of precision medicine and its subsequent outcome.
+

-As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
+
+
+As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
+
+
The detailed steps are as follows:
+
+
1. In the first cycles, patients are categorized into diagnostic/prognostic groups based on obvious characteristics.
-2. In later cycles, more specific groups of patients are defined using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
+
+2. In later cycles, more specific groups of patients are defined using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
+
3. Eventually, these feedback loops may allow the final cycles to target individual patients with specific data profiles.
+
+
## 5. Conclusion
-In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+
+
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+
+
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing endeavors to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
+
+
## 6. References
+
Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
-European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
+
+European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
+
+
Ginsburg GS, Phillips KA. Precision Medicine: From Science To Value. Health Aff (Millwood). 2018 May;37(5):694-701. doi: 10.1377/hlthaff.2017.1624. PMID: 29733705; PMCID: PMC5989714.
+
+
Robinson PN. Deep phenotyping for precision medicine. Hum Mutat. 2012 May;33(5):777-80. doi: 10.1002/humu.22080. PMID: 22504886.
+
+
National Research Council, Committee on A Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. National Academies Press; Washington DC: 2011.
+
+
Leopold JA, Loscalzo J. Emerging Role of Precision Medicine in Cardiovascular Disease. Circ Res. 2018;122(9):1302-1315. doi:10.1161/CIRCRESAHA.117.310782
+
+
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
+
+
Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and efficacy of mepolizumab in patients with moderate persistent asthma. Am J Respir Crit Care Med 2007; 176: 1062–1071.
+
+
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
-the image- might not use-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
+
+
+the image- might not use-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
+
https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
+
+ Ferté C, Trister AD, Huang E, et al. Impact of bioinformatic procedures in the development and translation of high-throughput molecular classifiers in oncology. Clin Cancer Res 2013; **19**: 4315–4325.
+
+Hendriksen JMT, Geersing GJ, Moons KGM, de Groot JAH. Diagnostic and prognostic prediction models. J Thromb Hae- most 2013; 11 (Suppl. 1): 129–41.
+
+M. Afzal, S. M. Riazul Islam, M. Hussain and S. Lee, "Precision Medicine Informatics: Principles, Prospects, and Challenges," in IEEE Access, vol. 8, pp. 13593-13612, 2020, doi: 10.1109/ACCESS.2020.2965955.
+
From 2d28b7472cfe6b62d559184a76221c5c9499ad7f Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 13:04:53 -0800
Subject: [PATCH 53/94] add track1 & 2
---
.../Grup25_Precision_Medicine/.DS_Store | Bin 6148 -> 6148 bytes
.../Precision_Medicine.md | 23 ++----------------
2 files changed, 2 insertions(+), 21 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/.DS_Store b/finalPaper/Grup25_Precision_Medicine/.DS_Store
index 5008ddfcf53c02e82d7eee2e57c38e5672ef89f6..54cff2322bc4e449809e8f33016565dece6a351b 100644
GIT binary patch
delta 305
zcmZoMXfc=|#>B`mF;Q%yo}wrV0|Nsi1A_nqLk@!;LoP!KkW87FxV#=DA;^%%kjaq8
zkcceFkk3#K6w3k9i3}+@>4w3{`MCu^)j$yN3P=#4D>vW8B`GIA38_4
zqUuaUxCYh2-24;*T5;(t$Ut^#!p1}yw#fz}EStGGxH*6UvN7>H^JIPzMOG%DOB5y>
MiU@D^5ZS{F0E%2f?*IS*
delta 69
zcmZoMXfc=|#>AjHu~2NHo+1YW5HK<@2yFhyD8{ylX%^#Vb`E|Hpgd6EJM(0I5k*d*
SG(!SN-DDFU<;^i7E0_TqCl31n
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 1f31150..bd608db 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,15 +1,12 @@
-
+
# The Process of Precision Medicine
-
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-#### BENG 183 Applied Genomic Technologies
-
-## Table of Contents
+
1. [What is Precision Medicine?](#1)
@@ -53,19 +50,14 @@
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
-<<<<<<< HEAD
The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
-=======
-The focus is to move away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial or a single case study from N number of individuals within a population. Figure 1 shows the difference between classical approach and precision medicine approach. Ultimately, comprehensive study of such subclasses depends on computational resources to capture, store and exchange phenotypic data and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
->>>>>>> d94479fce00c00580bbf6152cab074d85af22e2f

-<<<<<<< HEAD
##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
@@ -87,17 +79,6 @@ The framework of precision medicine is a process made up of number of feedback l
###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
-=======
-##### Figure 1: The left diagram shows treatment based on 'signs-and-symptoms' research. Patients with colon cancer are clustered into one group and given the same therapy, which thereby varies in treatment responses. Treatment has worked for some individuals while it had no or adverse effect for other. This is because this approach does not take patients' phenoytpic information into account. On the right, the same group of patients have been divided into subgroups based on individual phenotypic recognition, resulting in better understanding of the causal pathways and better treatment responses.
-
-### 2) Framework of Precision Medicine Process
-
-At the highest level, precision medicine process is a framework made up of feedback loops, with no steady-end point. Each cycle is an attempt to sort out and validate the process and stratify the subgroups further. The data assessed in the patients are used to try to develop clinically relevant models, and analyses inform need for further assessment of patients as an evolving result.
-
-
-
-###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
->>>>>>> d94479fce00c00580bbf6152cab074d85af22e2f
## 2. Deep Phenotyping
From 9a918b5cb2c03803ca6871ca3b711bcfd170a5bc Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 13:08:52 -0800
Subject: [PATCH 54/94] minor correction
---
.../Grup25_Precision_Medicine/Precision_Medicine.md | 11 ++++++-----
1 file changed, 6 insertions(+), 5 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index bd608db..4680315 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,4 +1,4 @@
-
+
@@ -173,18 +173,19 @@ After data is ready from track 1 for further training, models can be developed t
##### Figure 7: Representation of diagnostic and prognostic prediction modeling studies
- Model Development
+
Two main strategies are usually used to develop the models:
- 1) **Full Model**
- No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
+ 1) **Full Model**: No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
- 2) **Variable selection**
- **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
+ 2) **Variable selection**: **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
- Outcome
+
The outcome of a prediction aims to reflects a clinically significant and patient relevant health state, for example, death yes or no, or absence or presence of Leukemia. In case of prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
- Clinics-friendly Accommodation
+
Regression model can be too complicated to use in daily clinical uses, the model is usually simplify by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively effected the accuracy of the model and thus needs to be applied carefully.
From b02a19322959e69d87bcb6990b079470503f3aa5 Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 13:16:44 -0800
Subject: [PATCH 55/94] minor correction1
---
.../Precision_Medicine.md | 28 ++++++++++---------
1 file changed, 15 insertions(+), 13 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 4680315..b616105 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,4 +1,4 @@
-
+# New Document
@@ -149,14 +149,17 @@ Some of the common approaches for data preprocessing includes:
4. Data Below the Limits of Detection Filtration
-5. **Variable Selection**
+5. **Variable Selection**
+
+
+
-**Case Example: Denoising + Variable selection**
+**Case Example:** *Denoising + Variable selection*
*The collection of deep phenotyping data usually includes great amount of unselected data, which will inevitably include variables that are irrelevant for later modelling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which can shown in below.*
-45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.
+45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.

@@ -172,20 +175,18 @@ After data is ready from track 1 for further training, models can be developed t
##### Figure 7: Representation of diagnostic and prognostic prediction modeling studies
-- Model Development
-
+- Model Development
Two main strategies are usually used to develop the models:
+ 1. **Full Model**
+ No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
- 1) **Full Model**: No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
-
- 2) **Variable selection**: **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
-
-- Outcome
+ 2. **Variable selection**
+ **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
+- Outcome
The outcome of a prediction aims to reflects a clinically significant and patient relevant health state, for example, death yes or no, or absence or presence of Leukemia. In case of prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
-- Clinics-friendly Accommodation
-
+- Clinics-friendly Accommodation
Regression model can be too complicated to use in daily clinical uses, the model is usually simplify by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively effected the accuracy of the model and thus needs to be applied carefully.
@@ -302,3 +303,4 @@ Hendriksen JMT, Geersing GJ, Moons KGM, de Groot JAH. Diagnostic and prognostic
M. Afzal, S. M. Riazul Islam, M. Hussain and S. Lee, "Precision Medicine Informatics: Principles, Prospects, and Challenges," in IEEE Access, vol. 8, pp. 13593-13612, 2020, doi: 10.1109/ACCESS.2020.2965955.
+
From 0be67d899ae93ed2b9e1af4fb9fec9fdada1b320 Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 13:17:48 -0800
Subject: [PATCH 56/94] minor correction2
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index b616105..c3596ed 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -180,7 +180,7 @@ Two main strategies are usually used to develop the models:
1. **Full Model**
No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
- 2. **Variable selection**
+ 2. **Variable selection**
**Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
- Outcome
From af737463aa62c51966efb61ea24bee55cc003b4c Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 13:41:58 -0800
Subject: [PATCH 57/94] adjust fig num
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index c3596ed..7dec8be 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -207,7 +207,7 @@ After developing diagnostic and prognostic models from the previous step, there

-##### Figure 5: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
+##### Figure 8: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
@@ -223,7 +223,7 @@ In addition to the feedback, dissemination and communication of the taxonomy and
-##### Figure 6: The figure below shows repeated cycles of precision medicine and its subsequent outcome.
+##### Figure 9: The figure below shows repeated cycles of precision medicine and its subsequent outcome.

From 649dfd3ba096c95ccbca4406740204058eca4977 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 08:51:05 +0900
Subject: [PATCH 58/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 24 ++++++++-----------
1 file changed, 10 insertions(+), 14 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 7dec8be..1f91372 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,7 +1,3 @@
-# New Document
-
-
-
# The Process of Precision Medicine
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
@@ -10,25 +6,25 @@
1. [What is Precision Medicine?](#1)
-1.1. [Definition](#11)
+ 1.1. [Definition](#11)
-1.2. [Framework of Precision Medicine Process](#12)
+ 1.2. [Framework of Precision Medicine Process](#12)
2. [Deep Phenotyping](#2)
-2.1. [Importance of Phenotype](#21)
+ 2.1. [Importance of Phenotype](#21)
-2.2. [Why "Deep" Phenotyping?](#22)
+ 2.2. [Why "Deep" Phenotyping?](#22)
-2.3. [Processing Deep Phenotyping Data](#23)
+ 2.3. [Processing Deep Phenotyping Data](#23)
3. [Data Analysis](#3)
-3.1. [Preprocessing and Data Mining](#31)
+ 3.1. [Preprocessing and Data Mining](#31)
-3.2. [Diagnostic and Prognostic Models](#32)
+ 3.2. [Diagnostic and Prognostic Models](#32)
-3.3. [Predicting Treatment Response](#33)
+ 3.3. [Predicting Treatment Response](#33)
4. [Evolving Precision Medicine](#4)
@@ -135,7 +131,7 @@ Large-scale of data is expected to be integrated and converted into more precise
##### Figure 5: An integrated precision medicine framework for heterogeneous data collection, data analysis, knowledge management, and implementation of knowledge and data services.
-### 1) Preprocessing and Data Mining
+### 1) Preprocessing and Data Mining
The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing manoeuvres and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in analysis. **Quality Control** and **Preprocessing** of the data shall be preformed in this step. Since quality control is always dependent on the specific data type, more details can be found in paper. [Ferté ]
@@ -167,7 +163,7 @@ Some of the common approaches for data preprocessing includes:
Variable selection is important for filtering out noise data, yet how to define noise or whether a variable is revevant is always a unanswerable question. One important factor that can guide variable selection is scientifically based *a priori* knowledge about the possibly **biologically relevant variables**.
-### 2) Diagnostic and Prognostic Models
+### 2) Diagnostic and Prognostic Models
After data is ready from track 1 for further training, models can be developed to estimate the risk with absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. Prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]
From 56b643d166d79b1f8b4ca1119f5753c33e82827c Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 08:57:21 +0900
Subject: [PATCH 59/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 117 +-----------------
1 file changed, 5 insertions(+), 112 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 1f91372..68046d4 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -1,29 +1,20 @@
# The Process of Precision Medicine
### by Soyeon Kim, Hwayeon Lee, Meixian Wu
-
-
-
+
1. [What is Precision Medicine?](#1)
-
1.1. [Definition](#11)
-
1.2. [Framework of Precision Medicine Process](#12)
-
+
2. [Deep Phenotyping](#2)
-
2.1. [Importance of Phenotype](#21)
-
2.2. [Why "Deep" Phenotyping?](#22)
-
2.3. [Processing Deep Phenotyping Data](#23)
3. [Data Analysis](#3)
3.1. [Preprocessing and Data Mining](#31)
-
3.2. [Diagnostic and Prognostic Models](#32)
-
3.3. [Predicting Treatment Response](#33)
4. [Evolving Precision Medicine](#4)
@@ -32,97 +23,50 @@
6. [References](#6)
-
-
-
-
## 1. What is Precision Medicine?
-
-
### 1) Definition
-
-
Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
-
-
The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
-
-

-
-
##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
-
-
### 2) Framework of Precision Medicine Process
-
-
The framework of precision medicine is a process made up of number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and results of these analyses then inform the further assessment of patients as an evolving result.
-
-

-
-
###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
-
-
## 2. Deep Phenotyping
### 1) Importance of Phenotype
-
-
The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests.
-
-
This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.
-
-

-
-
##### Figure 3: Individuals with the same endophenotype, such as hypertension, can have different molecular phenotypes – resulting in different risk levels. Molecular phenotyping determines patients have different treatment responses as well.
-
-
### 2) Why "Deep" Phenotyping?
-
-
The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles.
-
-

-
-
##### Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
-
-
### 3) Processing Deep Phenotyping Data
-
-
Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
-
-
-
## 3. Data Analysis
Large-scale of data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]
@@ -147,7 +91,6 @@ Some of the common approaches for data preprocessing includes:
5. **Variable Selection**
-
@@ -185,115 +128,65 @@ The outcome of a prediction aims to reflects a clinically significant and patien
- Clinics-friendly Accommodation
Regression model can be too complicated to use in daily clinical uses, the model is usually simplify by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively effected the accuracy of the model and thus needs to be applied carefully.
-
### 3) Predicting Treatment Response
-
-
After developing diagnostic and prognostic models from the previous step, there is a need for assessing variables that define a novel taxonomy with their relevance in predicting treatment response. There are two strategies to develop models that predict treatment response.
-
-
- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with non-small cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later after sorting&numbering sources].
-
- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
-
-

##### Figure 8: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
-
-
This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
-
-
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
-
-
## 4. Evolving Precision Medicine
-
-
##### Figure 9: The figure below shows repeated cycles of precision medicine and its subsequent outcome.

-
-
As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
-
-
The detailed steps are as follows:
-
-
1. In the first cycles, patients are categorized into diagnostic/prognostic groups based on obvious characteristics.
2. In later cycles, more specific groups of patients are defined using more in-depth data that was obtained from the previous cycle as the data from each cycle is fed back to the next cycle of patient assessment.
3. Eventually, these feedback loops may allow the final cycles to target individual patients with specific data profiles.
-
-
## 5. Conclusion
-
-
In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
-
-
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing endeavors to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
-
-
## 6. References
-Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp
-
-European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
-
-
+Inke R. König, Oliver Fuchs, Gesine Hansen, Erika von Mutius, Matthias V. Kopp European Respiratory Journal Oct 2017, 50 (4) 1700391; DOI: 10.1183/13993003.00391-2017
Ginsburg GS, Phillips KA. Precision Medicine: From Science To Value. Health Aff (Millwood). 2018 May;37(5):694-701. doi: 10.1377/hlthaff.2017.1624. PMID: 29733705; PMCID: PMC5989714.
-
-
Robinson PN. Deep phenotyping for precision medicine. Hum Mutat. 2012 May;33(5):777-80. doi: 10.1002/humu.22080. PMID: 22504886.
-
-
National Research Council, Committee on A Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. National Academies Press; Washington DC: 2011.
-
-
Leopold JA, Loscalzo J. Emerging Role of Precision Medicine in Cardiovascular Disease. Circ Res. 2018;122(9):1302-1315. doi:10.1161/CIRCRESAHA.117.310782
-
-
Riley RD, Hayden JA, Steyerberg EW, et al. Prognosis Research Strategy (PROGRESS) 2: prognostic factor research. PLoS Med 2013; 10: e1001380.
-
-
Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and efficacy of mepolizumab in patients with moderate persistent asthma. Am J Respir Crit Care Med 2007; 176: 1062–1071.
-
-
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
-
-
-the image- might not use-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
-
-https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
+the image- might not use-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/. https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
- Ferté C, Trister AD, Huang E, et al. Impact of bioinformatic procedures in the development and translation of high-throughput molecular classifiers in oncology. Clin Cancer Res 2013; **19**: 4315–4325.
+Ferté C, Trister AD, Huang E, et al. Impact of bioinformatic procedures in the development and translation of high-throughput molecular classifiers in oncology. Clin Cancer Res 2013; **19**: 4315–4325.
Hendriksen JMT, Geersing GJ, Moons KGM, de Groot JAH. Diagnostic and prognostic prediction models. J Thromb Hae- most 2013; 11 (Suppl. 1): 129–41.
From 4ff38e2bd8e5720b72f1c4be84a9948c087294a4 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 08:58:12 +0900
Subject: [PATCH 60/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 6 ------
1 file changed, 6 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 68046d4..9adb76f 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -5,22 +5,16 @@
1. [What is Precision Medicine?](#1)
1.1. [Definition](#11)
1.2. [Framework of Precision Medicine Process](#12)
-
2. [Deep Phenotyping](#2)
2.1. [Importance of Phenotype](#21)
2.2. [Why "Deep" Phenotyping?](#22)
2.3. [Processing Deep Phenotyping Data](#23)
-
3. [Data Analysis](#3)
-
3.1. [Preprocessing and Data Mining](#31)
3.2. [Diagnostic and Prognostic Models](#32)
3.3. [Predicting Treatment Response](#33)
-
4. [Evolving Precision Medicine](#4)
-
5. [Conclusion](#5)
-
6. [References](#6)
## 1. What is Precision Medicine?
From 9e67da332ed287bd01d5b26e9ca9b17fedf734e6 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 09:00:15 +0900
Subject: [PATCH 61/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 3 ---
1 file changed, 3 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 9adb76f..3e6d6d7 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -84,10 +84,7 @@ Some of the common approaches for data preprocessing includes:
4. Data Below the Limits of Detection Filtration
5. **Variable Selection**
-
-
-
**Case Example:** *Denoising + Variable selection*
*The collection of deep phenotyping data usually includes great amount of unselected data, which will inevitably include variables that are irrelevant for later modelling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which can shown in below.*
From 85d461323de106c694c55c1a72fdd0304af5d507 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 09:00:55 +0900
Subject: [PATCH 62/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 ++
1 file changed, 2 insertions(+)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 3e6d6d7..c0469ce 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -84,7 +84,9 @@ Some of the common approaches for data preprocessing includes:
4. Data Below the Limits of Detection Filtration
5. **Variable Selection**
+
+
**Case Example:** *Denoising + Variable selection*
*The collection of deep phenotyping data usually includes great amount of unselected data, which will inevitably include variables that are irrelevant for later modelling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which can shown in below.*
From 285653b3673d983603e6451151789eb066b36c5f Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 09:26:35 +0900
Subject: [PATCH 63/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 46 +++++++++----------
1 file changed, 23 insertions(+), 23 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index c0469ce..1aae017 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -21,29 +21,29 @@
### 1) Definition
-Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy' and 'deep phenotyping.'
+Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy', and 'deep phenotyping.'
-The focus of applied definitions is moving away from classical 'signs-and-symptoms’ approach or 'population’ approach into 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with same group of patients. Comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
+The focus of applied definitions is moving away from the classical 'signs-and-symptoms’ approach or 'population’ approach into the 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with the same group of patients. A comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.

-##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group from the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group are divided into disease subgroups with more precise and validated phenotypic recognition or better understanding of the causal pathways.
+##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group for the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group is divided into disease subgroups with more precise and validated phenotypic recognition or a better understanding of the causal pathways.
### 2) Framework of Precision Medicine Process
-The framework of precision medicine is a process made up of number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and results of these analyses then inform the further assessment of patients as an evolving result.
+The framework of precision medicine is a process made up of a number of feedback loops, with no steady-end point. Each cycle is an attempt to make the process more precise with more stratification of patients. The data assessed in the patients are used to try to develop clinically relevant models, and the results of these analyses then inform the further assessment of patients as an evolving result.

-###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from track 1-3 are fed back to deep phenotyping stage for subsequent assessments.
+###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after a number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from tracks 1-3 are fed back to the deep phenotyping stage for subsequent assessments.
## 2. Deep Phenotyping
### 1) Importance of Phenotype
-The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In medical context, however, ‘phenotype’ is deviation from normal morphology, physiology, or behavior. When physician makes note of patient’s phenotype, the physician is doing so by taking medical history, performing physical examination, diagnostic imaging, blood tests, and other psychological tests.
+The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is a collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In a medical context, however, ‘phenotype’ is a deviation from normal morphology, physiology, or behavior. When a physician makes note of a patient’s phenotype, the physician is doing so by taking a medical history, performing a physical examination, diagnostic imaging, blood tests, and other psychological tests.
-This is where precise phenotype information comes into play. As physician makes note of patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment which may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies in the molecular level.
+This is where precise phenotype information comes into play. As the physician makes note of the patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment that may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment, and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, a full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows the importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies at the molecular level.

@@ -51,19 +51,19 @@ This is where precise phenotype information comes into play. As physician makes
### 2) Why "Deep" Phenotyping?
-The major problem with current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as precise and comprehensive analysis of phenotypic abnormalities in which individual components of individual components of the phenotype are observed and described. Figure 4 shows precision medicine approach to phenotyping; even the individuals with same endophenotype may are biologically distinct and encompass different disease profiles.
+The major problem with the current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of the natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as a precise and comprehensive analysis of phenotypic abnormalities in which individual components of the phenotype are observed and described. Figure 4 shows a precision medicine approach to phenotyping; even the individuals with the same endophenotype may are biologically distinct and encompass different disease profiles.

-##### Figure 4: Individuals undergo deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping, because individuals are classified beyond their endophenotypes. Such methodology optimizes identification of biomarkers, clinical trials, and prognostication of disease.
+##### Figure 4: Individuals undergo a deep phenotyping process with data analysis performed using network analysis. This is deep phenotyping because individuals are classified beyond their endophenotypes. Such methodology optimizes the identification of biomarkers, clinical trials, and prognostication of disease.
### 3) Processing Deep Phenotyping Data
-Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
+Conversion of deep phenotyping data into tangible therapeutic utility poses a number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in a clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
## 3. Data Analysis
-Large-scale of data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]
+Large-scale data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]

@@ -71,7 +71,7 @@ Large-scale of data is expected to be integrated and converted into more precise
### 1) Preprocessing and Data Mining
-The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing manoeuvres and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in analysis. **Quality Control** and **Preprocessing** of the data shall be preformed in this step. Since quality control is always dependent on the specific data type, more details can be found in paper. [Ferté ]
+The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing maneuvers, and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in the analysis. **Quality Control** and **Preprocessing** of the data shall be performed in this step. Since quality control is always dependent on the specific data type, more details can be found in the paper. [Ferté ]
Some of the common approaches for data preprocessing includes:
@@ -89,7 +89,7 @@ Some of the common approaches for data preprocessing includes:
**Case Example:** *Denoising + Variable selection*
-*The collection of deep phenotyping data usually includes great amount of unselected data, which will inevitably include variables that are irrelevant for later modelling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which can shown in below.*
+*The collection of deep phenotyping data usually includes a great amount of unselected data, which will inevitably include variables that are irrelevant for later modeling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which is shown below.*
45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.
@@ -97,11 +97,11 @@ Some of the common approaches for data preprocessing includes:
##### Figure 6: Impact of variable selection based on illustration
-Variable selection is important for filtering out noise data, yet how to define noise or whether a variable is revevant is always a unanswerable question. One important factor that can guide variable selection is scientifically based *a priori* knowledge about the possibly **biologically relevant variables**.
+Variable selection is important for filtering out noise data, yet how to define noise or whether a variable is relevant is always an unanswerable question. One important factor that can guide variable selection is scientifically based a priori knowledge about the possibly **biologically relevant variables**.
### 2) Diagnostic and Prognostic Models
-After data is ready from track 1 for further training, models can be developed to estimate the risk with absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. Prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]
+After data is ready from track 1 for further training, models can be developed to estimate the risk with an absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. Prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]

@@ -110,16 +110,16 @@ After data is ready from track 1 for further training, models can be developed t
- Model Development
Two main strategies are usually used to develop the models:
1. **Full Model**
- No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
+ No predictor selection is applied. Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modeling.
2. **Variable selection**
- **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
+ **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly content-specific.
- Outcome
-The outcome of a prediction aims to reflects a clinically significant and patient relevant health state, for example, death yes or no, or absence or presence of Leukemia. In case of prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
+The outcome of a prediction aims to reflect a clinically significant and patient-relevant health state, for example, death yes or no, or absence or presence of Leukemia. In the case of the prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
- Clinics-friendly Accommodation
-Regression model can be too complicated to use in daily clinical uses, the model is usually simplify by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively effected the accuracy of the model and thus needs to be applied carefully.
+The regression model can be too complicated to use in daily clinical uses, the model is usually simplified by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively affected the accuracy of the model and thus needs to be applied carefully.
### 3) Predicting Treatment Response
@@ -127,13 +127,13 @@ After developing diagnostic and prognostic models from the previous step, there
- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with non-small cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later after sorting&numbering sources].
-- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction in blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].

##### Figure 8: The figure above is an illustration of applying different treatments, also known as "tailored medicine", to categorized groups to increase the effectiveness of treatment based on a prediction model.
-This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnotics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
+This process of building prediction models involves generating further knowledge about the disease and treatment from the diagnostics and prognostics models or the data itself. The findings from this process, in the form of data, would be fed back to the phenotyping of patients to further adjust the clinical trial that could more precisely show the effectiveness of the treatment.
In addition to the feedback, dissemination and communication of the taxonomy and models with the clinical and scientific communities, for instance, to provide utilizable algorithms for clinical practices.
@@ -143,7 +143,7 @@ In addition to the feedback, dissemination and communication of the taxonomy and

-As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnotic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
+As seen in the figure, the cycle of patients assessment(deep phenotyping), data processing(preprocessing and data mining), and model building(diagnostic, prognostic, and prediction model building) is repeated at least several times to further increase the preciseness of the medicine by categorizing patient groups at a higher resolution.
The detailed steps are as follows:
@@ -155,7 +155,7 @@ The detailed steps are as follows:
## 5. Conclusion
-In this paper, the process of precision medicine, starting from the deep phenotyping stage to data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, were discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with repeated cycle of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to the data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, was discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with the repeated cycles of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing endeavors to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
From f8953f38a073e9cf81753ff8d820974442849556 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 09:59:46 +0900
Subject: [PATCH 64/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 30 ++++++++++---------
1 file changed, 16 insertions(+), 14 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 1aae017..f4abb61 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -21,13 +21,13 @@
### 1) Definition
-Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy', and 'deep phenotyping.'
+Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy', and 'deep phenotyping'.
The focus of applied definitions is moving away from the classical 'signs-and-symptoms’ approach or 'population’ approach into the 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with the same group of patients. A comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.

-##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and give the same treatment, because they were treated as one group for the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group is divided into disease subgroups with more precise and validated phenotypic recognition or a better understanding of the causal pathways.
+##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and are given the same treatment, because they are treated as one group for the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group is divided into disease subgroups with more precise and validated phenotypic recognition or a better understanding of the causal pathways.
### 2) Framework of Precision Medicine Process
@@ -35,7 +35,7 @@ The framework of precision medicine is a process made up of a number of feedback

-###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoise and baseline correction and variable selection. Track 2 forecasts clinically relevant outcome as the model after a number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from tracks 1-3 are fed back to the deep phenotyping stage for subsequent assessments.
+###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoising, baseline correction, and variable selection. Track 2 forecasts clinically relevant outcome as the model after a number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from tracks 1-3 are fed back to the deep phenotyping stage for subsequent assessments.
## 2. Deep Phenotyping
@@ -51,7 +51,7 @@ This is where precise phenotype information comes into play. As the physician ma
### 2) Why "Deep" Phenotyping?
-The major problem with the current phenotyping regime is sloppy or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information. Other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of the natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as a precise and comprehensive analysis of phenotypic abnormalities in which individual components of the phenotype are observed and described. Figure 4 shows a precision medicine approach to phenotyping; even the individuals with the same endophenotype may are biologically distinct and encompass different disease profiles.
+The major problem with the current phenotyping regime is unsystematic or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of the natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as a precise and comprehensive analysis of phenotypic abnormalities in which individual components of the phenotype are observed and described. Figure 4 shows a precision medicine approach to phenotyping; even the individuals with the same endophenotype may are biologically distinct and encompass different disease profiles.

@@ -59,11 +59,11 @@ The major problem with the current phenotyping regime is sloppy or imprecise des
### 3) Processing Deep Phenotyping Data
-Conversion of deep phenotyping data into tangible therapeutic utility poses a number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in a clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
+Conversion of deep phenotyping data into tangible therapeutic utility poses a number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in a clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
## 3. Data Analysis
-Large-scale data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]
+Large-scale data is integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]

@@ -71,7 +71,7 @@ Large-scale data is expected to be integrated and converted into more precise th
### 1) Preprocessing and Data Mining
-The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing maneuvers, and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in the analysis. **Quality Control** and **Preprocessing** of the data shall be performed in this step. Since quality control is always dependent on the specific data type, more details can be found in the paper. [Ferté ]
+The first step of data analysis is data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing maneuvers, and different types of devices. Therefore, data is filtered and adjusted to be comparable in the analysis. **Quality Control** and **preprocessing** of the data are performed in this step [Ferté ].
Some of the common approaches for data preprocessing includes:
@@ -89,15 +89,15 @@ Some of the common approaches for data preprocessing includes:
**Case Example:** *Denoising + Variable selection*
-*The collection of deep phenotyping data usually includes a great amount of unselected data, which will inevitably include variables that are irrelevant for later modeling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which is shown below.*
+*The collection of deep phenotyping data includes a great amount of unselected data, which will inevitably include variables that are irrelevant for later modeling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which is shown below.*
-45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.
+In the figure below, 45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly in figure 6b. However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. About half of the individuals are classified incorrectly.

##### Figure 6: Impact of variable selection based on illustration
-Variable selection is important for filtering out noise data, yet how to define noise or whether a variable is relevant is always an unanswerable question. One important factor that can guide variable selection is scientifically based a priori knowledge about the possibly **biologically relevant variables**.
+Variable selection is important for filtering out noisy data, yet how to define noise or whether a variable is relevant remains unanswerable. One important factor that can guide variable selection is scientifically based a priori knowledge about the possibly **biologically relevant variables**.
### 2) Diagnostic and Prognostic Models
@@ -110,16 +110,18 @@ After data is ready from track 1 for further training, models can be developed t
- Model Development
Two main strategies are usually used to develop the models:
1. **Full Model**
- No predictor selection is applied. Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modeling.
+ No predictor selection is applied.
+ Pros: avoid improper predictor selection due to predictor selection bias.
+ Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modeling.
2. **Variable selection**
**Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly content-specific.
- Outcome
-The outcome of a prediction aims to reflect a clinically significant and patient-relevant health state, for example, death yes or no, or absence or presence of Leukemia. In the case of the prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
+The outcome of a prediction aims to reflect a clinically significant and patient-relevant health state, for example, prediction on death, or absence or presence of leukemia. In the case of the prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
- Clinics-friendly Accommodation
-The regression model can be too complicated to use in daily clinical uses, the model is usually simplified by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively affected the accuracy of the model and thus needs to be applied carefully.
+The regression model can be too complicated to use in daily clinical uses. Therefore, the model is usually simplified by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively affect the accuracy of the model and thus it needs to be applied carefully.
### 3) Predicting Treatment Response
@@ -177,7 +179,7 @@ Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and effi
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
-the image- might not use-- “What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/. https://getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/
+“What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
Ferté C, Trister AD, Huang E, et al. Impact of bioinformatic procedures in the development and translation of high-throughput molecular classifiers in oncology. Clin Cancer Res 2013; **19**: 4315–4325.
From dd339a5b16d178c5883b8a3d318d3acdbefe308b Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 17:05:06 -0800
Subject: [PATCH 65/94] Update Precision_Medicine.md
---
.../Precision_Medicine.md | 24 +++++++++----------
1 file changed, 11 insertions(+), 13 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index 7dec8be..accd75b 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -125,11 +125,9 @@ The major problem with current phenotyping regime is sloppy or imprecise descrip
Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
-
-
## 3. Data Analysis
-Large-scale of data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]
+Large-scale data is expected to be integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]

@@ -137,7 +135,7 @@ Large-scale of data is expected to be integrated and converted into more precise
### 1) Preprocessing and Data Mining
-The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing manoeuvres and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in analysis. **Quality Control** and **Preprocessing** of the data shall be preformed in this step. Since quality control is always dependent on the specific data type, more details can be found in paper. [Ferté ]
+The first step of data analysis is always data preprocessing. Studies on fractional exhaled nitric oxide as a marker of eosinophilic inflammation in patients with asthma might be influenced by variable techniques of measurement, sampling procedures, breathing maneuvers, and different types of devices. Therefore, data is expected to be filtered and adjusted to be comparable in the analysis. **Quality Control** and **Preprocessing** of the data shall be performed in this step. Since quality control is always dependent on the specific data type, more details can be found in the paper. [Ferté ]
Some of the common approaches for data preprocessing includes:
@@ -145,7 +143,7 @@ Some of the common approaches for data preprocessing includes:
2. Missing Value Filling
-3. Data Out of Range Filtration
+3. Data Out of Range Filtration
4. Data Below the Limits of Detection Filtration
@@ -157,19 +155,19 @@ Some of the common approaches for data preprocessing includes:
**Case Example:** *Denoising + Variable selection*
-*The collection of deep phenotyping data usually includes great amount of unselected data, which will inevitably include variables that are irrelevant for later modelling. The irrelevant variables that contain random “noise” can mask important underlying relationships and structures, which can shown in below.*
+*The collection of deep phenotyping data usually includes a significant amount of unselected data, which will inevitably include variables that are irrelevant for later modeling. The irrelevant variables that contain random “noise” can mask meaningful underlying relationships and structures, which can be shown below.*
-45 individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the cluster algorithm fails to find the three groups as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.
+Forty-five individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the clustering algorithm fails to find the three groups, as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.

##### Figure 6: Impact of variable selection based on illustration
-Variable selection is important for filtering out noise data, yet how to define noise or whether a variable is revevant is always a unanswerable question. One important factor that can guide variable selection is scientifically based *a priori* knowledge about the possibly **biologically relevant variables**.
+Variable selection is essential for filtering out noise data, yet how to define noise or whether a variable is relevant is always an unanswerable question. One crucial factor that can guide variable selection is scientifically based *a priori* knowledge about the possibly **biologically relevant variables**.
### 2) Diagnostic and Prognostic Models
-After data is ready from track 1 for further training, models can be developed to estimate the risk with absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. Prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]
+After data is ready from track 1 for further training, models can be developed to estimate the risk with an absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. The prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]

@@ -178,16 +176,16 @@ After data is ready from track 1 for further training, models can be developed t
- Model Development
Two main strategies are usually used to develop the models:
1. **Full Model**
- No predictor selection is applied . Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modelling.
+ No predictor selection is applied. Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to preselect the biologically relevant predictors for modeling adequately.
2. **Variable selection**
- **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly *Content-Specific*.
+ **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods. The choice of methods is highly *Content-Specific*.
- Outcome
-The outcome of a prediction aims to reflects a clinically significant and patient relevant health state, for example, death yes or no, or absence or presence of Leukemia. In case of prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
+The outcome of a prediction aims to reflect a clinically significant and patient-relevant health state, for example, death yes or no, or absence or presence of Leukemia. In the case of a prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
- Clinics-friendly Accommodation
-Regression model can be too complicated to use in daily clinical uses, the model is usually simplify by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively effected the accuracy of the model and thus needs to be applied carefully.
+The regression model can be too complicated to use in daily clinical uses; the model is usually simplified by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively affect the model's accuracy and thus needs to be applied carefully.
### 3) Predicting Treatment Response
From 55b0c5f3039dc3093c8f6b1226d6b0fa6b78264a Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 10:09:02 +0900
Subject: [PATCH 66/94] Update Precision_Medicine.md
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index f4abb61..9aafca6 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -129,7 +129,7 @@ After developing diagnostic and prognostic models from the previous step, there
- Prediction models can be built on the diagnostic and prognostic models from the previous stage as prognostic factors may act as the natural variables to consider when developing prediction models. For instance, epidermal growth factor receptor tyrosine kinase status acts as a prognostic factor for survival in patients with non-small cell lung cancer and a predictive factor for response to the tyrosine kinase inhibitor gefitinib as first-line treatment at the same time [Riley RD(will change later after sorting&numbering sources].
-- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the first clinical trials that used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment, the use of mepolizumab was associated with a significant reduction in blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].
+- The data can be directly utilized to extract significant information relevant to the prediction of the disease. For instance, in the study of asthma patients, the first clinical trials used the monoclonal anti-IL-5 antibody mepolizumab for asthma treatment. In the trial, the use of mepolizumab was associated with a significant reduction in blood and sputum eosinophils but did not have significant clinical benefit in asthma patients [Flood-Page]. Consequently, in the following trials, patients with refractory eosinophilic asthma were selected and in this subgroup, mepolizumab therapy added significant clinical benefit in patients by reducing exacerbations and improving asthma quality of life scores [Haldar P].

@@ -157,7 +157,7 @@ The detailed steps are as follows:
## 5. Conclusion
-In this paper, the process of precision medicine, starting from the deep phenotyping stage to the data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, was discussed against the background of airway diseases. As seen in the previous section on the continual evolution of precision medicine with the repeated cycles of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
+In this paper, the process of precision medicine, starting from the deep phenotyping stage to the data analysis part, which comprised preprocessing, data mining, developing diagnostic, prognostic, and prediction models, was discussed. As seen in the previous section on the continual evolution of precision medicine with the repeated cycles of the above steps, precision medicine should be viewed as the continuous process of feedback loops rather than a steady-state with an end-point or a specific output from the research. In this context, tailored or stratified medicine resulting from new stratifications can be considered as a makeshift product of the process that will generate new data for the next cycle, thus further increasing the precision.
Once again, the ultimate goal of precision medicine is the most effective treatment for the individual patient. To step closer to this goal, ongoing endeavors to be even more precise and individualistic, newly-gained scientific and clinical knowledge, and new data sources would be necessary.
From ca5abd39db0c9293424dfc6f9ab96cf271c45e7c Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 17:18:53 -0800
Subject: [PATCH 67/94] grammar check
---
.../Precision_Medicine.md | 36 +++++++++----------
1 file changed, 17 insertions(+), 19 deletions(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index cc95fc4..d125889 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -21,13 +21,13 @@
### 1) Definition
-Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy', and 'deep phenotyping'.
+Precision medicine is personalized treatment strategies on the basis of genetic, biomarker, phenotypic, or psychosocial characteristics to stratify patients into novel subpopulations that differ in their susceptibility to a particular disease or their response to a specific treatment. It is also commonly referred to as 'stratified medicine', 'targeted therapy', and 'deep phenotyping'.
-The focus of applied definitions is moving away from the classical 'signs-and-symptoms’ approach or 'population’ approach into the 'N of 1’ approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between two approaches with the same group of patients. A comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data, and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.
+The focus of applied definitions is moving away from the classical 'signs-and-symptoms' approach or 'population' approach into the 'N of 1' approach in which each patient is an entire trial as a single case study from N number of individuals within a population. Figure 1 shows the difference between the two approaches with the same group of patients. A comprehensive study of such subclasses ultimately depends on computational resources to capture, store and exchange phenotypic data and upon sophisticated algorithms to integrate it with genomic variation, omics profiles, and other clinical information.

-##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and are given the same treatment, because they are treated as one group for the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group is divided into disease subgroups with more precise and validated phenotypic recognition or a better understanding of the causal pathways.
+##### Figure 1: In the left diagram, colon cancer patients are clustered into one group and are given the same treatment because they are treated as one group for the same symptoms. This does not take into account that patients may respond differently to a particular disease or treatment. On the right diagram, however, the same group is divided into disease subgroups with more precise and validated phenotypic recognition or a better understanding of the causal pathways.
### 2) Framework of Precision Medicine Process
@@ -35,15 +35,15 @@ The framework of precision medicine is a process made up of a number of feedback

-###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoising, baseline correction, and variable selection. Track 2 forecasts clinically relevant outcome as the model after a number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from tracks 1-3 are fed back to the deep phenotyping stage for subsequent assessments.
+###### Figure 2: This diagram shows the process of precision medicine. In the deep phenotyping stage, data are gathered and forwarded to tracks 1-3, which are clinical data assessment steps. In track 1, data are preprocessed and explored for previously unknown structure with data mining techniques, such as clustering analysis to derive subgroup of samples. This step also composes of denoising, baseline correction, and variable selection. Track 2 forecasts clinically relevant outcomes as the model after a number of feedback loops. Track 3 predicts treatment response and generates further knowledge about the treatment. This step also utilizes feedback to patient phenotyping results. Results from tracks 1-3 are fed back to the deep phenotyping stage for subsequent assessments.
## 2. Deep Phenotyping
### 1) Importance of Phenotype
-The word phenotype can be used differently in biology versus medicine. In biology, ‘phenotype’ is a collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In a medical context, however, ‘phenotype’ is a deviation from normal morphology, physiology, or behavior. When a physician makes note of a patient’s phenotype, the physician is doing so by taking a medical history, performing a physical examination, diagnostic imaging, blood tests, and other psychological tests.
+The word phenotype can be used differently in biology versus medicine. In biology, 'phenotype' is a collection of observable physical properties of an organism, including the organism's appearance, development, behavior, and even characteristics such as gene expression profiles in response to environmental cues. In a medical context, however, 'phenotype' is a deviation from normal morphology, physiology, or behavior. When a physician makes notes of a patient's phenotype, the physician is doing so by taking a medical history, performing a physical examination, diagnostic imaging, blood tests, and other psychological tests.
-This is where precise phenotype information comes into play. As the physician makes note of the patient’s phenotypes, the physician is making a diagnosis for the patient’s disease – making a hypothesis of what it may or may not be and provides treatment that may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task especially for the cases of rare diseases of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment, and unnecessary procedures that result in patients’ psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making correct prognosis, a full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows the importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals, because their phenotype ultimately varies at the molecular level.
+This is where precise phenotype information comes into play. As the physician makes notes of the patient's phenotypes, the physician is making a diagnosis for the patient's disease – making a hypothesis of what it may or may not be and provides a treatment that may or may not work. Making a diagnosis, therefore, is perhaps the most important task in treating a disease, but it is the most challenging task, especially for the cases of rare diseases, of which 8000 diseases are yet to be classified. Today, major clinical problems arise from delayed or inaccurate diagnosis, treatment, and unnecessary procedures that result in patients' psychological burdens and unnecessary expenses. To prevent complications and set forth effective treatments from making a correct prognosis, a full spectrum of phenotypic abnormalities is absolutely critical for improving care quality while reducing the need for unnecessary diagnostic testing and therapies. Figure 3 shows the importance of phenotype and its molecular network underpinning. Even with the same endophenotype, risk varies between individuals because their phenotype ultimately varies at the molecular level.

@@ -51,7 +51,7 @@ This is where precise phenotype information comes into play. As the physician ma
### 2) Why "Deep" Phenotyping?
-The major problem with the current phenotyping regime is unsystematic or imprecise descriptions of phenotypic descriptions in medical publications. For instance, “still walking after 25 years of onset” is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of the natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease, or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as a precise and comprehensive analysis of phenotypic abnormalities in which individual components of the phenotype are observed and described. Figure 4 shows a precision medicine approach to phenotyping; even the individuals with the same endophenotype may are biologically distinct and encompass different disease profiles.
+The major problem with the current phenotyping regime is unsystematic or imprecise descriptions of phenotypic descriptions in medical publications. For instance, "still walking after 25 years of onset" is definitely a phenotypic description, yet it is unclear what the physician observed in the patient as such descriptions are likely to evoke different ideas for different readers depending on personal experience and imagination. Furthermore, the current gene mutation database has very little to no phenotypic information other than the fact that the patient has that mutagen. While this information is indeed important for determining pathogenicity, it is devoid of the natural history of the disease – which is very important clinically in understanding the spectrum of complications with the disease or genotype-phenotype correlations. Deep phenotyping offers solutions for current challenges, including semantics and technical standards for phenotype and disease data. Deep phenotyping is defined as a precise and comprehensive analysis of phenotypic abnormalities in which individual components of the phenotype are observed and described. Figure 4 shows a precision medicine approach to phenotyping; even the individuals with the same endophenotype may are biologically distinct and encompass different disease profiles.

@@ -60,7 +60,7 @@ The major problem with the current phenotyping regime is unsystematic or impreci
### 3) Processing Deep Phenotyping Data
-Conversion of deep phenotyping data into tangible therapeutic utility poses number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information are critical in generating the data in clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
+Conversion of deep phenotyping data into tangible therapeutic utility poses a number of challenges yet to be solved. First, computational environments for analysis of high dimensional data is required. Second, there must be data from large populations of patients as a knowledge network. The most important, however, is the integration of the two. For example, next-Generation sequencing enables genome-wide investigation of rare genetic variants, but associating these with diseases requires tailored statical tools that summarize the information of neighbored variants. Indeed, the integration of two types of different information is critical in generating the data in a clinically relevant way. To clarify this, the structure of the precision medicine process offers tracks 1-3, which are handling of the data for better prediction of drug sensitivity.
@@ -79,7 +79,7 @@ The first step of data analysis is always data preprocessing. Studies on fractio
Some of the common approaches for data preprocessing includes:
-1. **Denoising** and Baseline Correction
+1. ** denoising** and Baseline Correction
2. Missing Value Filling
@@ -94,7 +94,7 @@ Some of the common approaches for data preprocessing includes:
**Case Example:** *Denoising + Variable selection*
-*The collection of deep phenotyping data usually includes a significant amount of unselected data, which will inevitably include variables that are irrelevant for later modeling. The irrelevant variables that contain random “noise” can mask meaningful underlying relationships and structures, which can be shown below.*
+*The collection of deep phenotyping data usually includes a significant amount of unselected data, which will inevitably include variables that are irrelevant for later modeling. The irrelevant variables that contain random "noise" can mask meaningful underlying relationships and structures, which can be shown below.*
Forty-five individuals are clustered into three homogeneous subgroups if two variables are considered. A hierarchical cluster analysis using only these two variables identifies three clusters clearly (figure 6b). However, if three random noise variables are added to the dataset, the clustering algorithm fails to find the three groups, as indicated in figure 6c. We can see that about half of the individuals are classified incorrectly.
@@ -109,7 +109,7 @@ Variable selection is important for filtering out noisy data, yet how to define
### 2) Diagnostic and Prognostic Models
-After data is ready from track 1 for further training, models can be developed to estimate the risk with an absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. Prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]
+After data is ready from track 1 for further training, models can be developed to estimate the risk with an absolute probability of the presence or absence of an outcome or disease in individuals based on their clinical and non-clinical information. The prediction model can be diagnostic (outcome or disease present at this moment) or prognostic (outcome occurs within a specified time frame). [Hendriksen]

@@ -120,17 +120,16 @@ After data is ready from track 1 for further training, models can be developed t
Two main strategies are usually used to develop the models:
1. **Full Model**
No predictor selection is applied.
- Pros: avoid improper predictor selection due to predictor selection bias.
- Cons: requires much prior knowledge to adequately preselect the biologically relevant predictors for modeling.
+ Pros: avoid improper predictor selection due to predictor selection bias. Cons: requires much prior knowledge to preselect the biologically relevant predictors for modeling adequately.
2. **Variable selection**
- **Backward Elimination** of ‘redundant’ predictors or **Forward Selection** of ‘promising’ ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods, The choice of methods is highly content-specific.
+ **Backward Elimination** of 'redundant' predictors or **Forward Selection** of 'promising' ones. The backward procedure is initialized with the full multivariable and then subsequently removes predictors based on a predefined criterion. Forward selection is when predictors are added to the multivariable model one by one. There is no agreement on the optimal method among the two methods. The choice of methods is highly context-specific.
- Outcome
-The outcome of a prediction aims to reflect a clinically significant and patient-relevant health state, for example, prediction on death, or absence or presence of leukemia. In the case of the prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
+The outcome of a prediction aims to reflect a clinically significant and patient-relevant health state, for example, prediction on death, or absence or presence of leukemia. In the case of the prognostic prediction model, a follow-up period is needed to be clearly defined for outcome development. [Hendriksen]
- Clinics-friendly Accommodation
-The regression model can be too complicated to use in daily clinical uses. Therefore, the model is usually simplified by rounding coefficient toward integer numbers for easier scoring. However, such accommodation might negatively affect the accuracy of the model and thus it needs to be applied carefully.
+The regression model can be too complicated to use in daily clinical uses. Therefore, the model is usually simplified by rounding the coefficients toward integer numbers for easier scoring. However, such accommodation might negatively affect the accuracy of the model, and thus it needs to be applied carefully.
### 3) Predicting Treatment Response
@@ -188,12 +187,11 @@ Flood-Page P, Swenson C, Faiferman I, et al. A study to evaluate safety and effi
Haldar P, Brightling CE, Hargadon B, et al. Mepolizumab and exacerbations of refractory eosinophilic asthma. N Engl J Med 2009; 360: 973–984.
-“What Is Precision Medicine and How Can It Help Fix Healthcare.” ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
+"What Is Precision Medicine and How Can It Help Fix Healthcare." ReferralMD, ReferralMD, 11 Dec. 2018, getreferralmd.com/2018/02/precision-medicine-can-help-fix-healthcare/.
-Ferté C, Trister AD, Huang E, et al. Impact of bioinformatic procedures in the development and translation of high-throughput molecular classifiers in oncology. Clin Cancer Res 2013; **19**: 4315–4325.
+Ferté C, Trister AD, Huang E, et al. Impact of bioinformatic procedures in the development and translation of high-throughput molecular classifiers in oncology. Clin Cancer Res 2013; **19**: 4315–4325.
Hendriksen JMT, Geersing GJ, Moons KGM, de Groot JAH. Diagnostic and prognostic prediction models. J Thromb Hae- most 2013; 11 (Suppl. 1): 129–41.
M. Afzal, S. M. Riazul Islam, M. Hussain and S. Lee, "Precision Medicine Informatics: Principles, Prospects, and Challenges," in IEEE Access, vol. 8, pp. 13593-13612, 2020, doi: 10.1109/ACCESS.2020.2965955.
-
From d8fa0019a58d95238401ebb9986e9de4f342aa1b Mon Sep 17 00:00:00 2001
From: meixwu
Date: Tue, 15 Dec 2020 17:23:48 -0800
Subject: [PATCH 68/94] fixed image
---
finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
index d125889..ecc91bb 100644
--- a/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
+++ b/finalPaper/Grup25_Precision_Medicine/Precision_Medicine.md
@@ -69,7 +69,7 @@ Conversion of deep phenotyping data into tangible therapeutic utility poses a nu
Large-scale data is integrated and converted into more precise therapeutic interventions. The analysis of deep phenotyping is distinguished into three sequential tracks: in track 1, the data are handled without knowledge of a clinical end-point; in track 2, data are used to build models for a more precise diagnosis or prognosis of disease or disease outcome; and track 3 leads to models that predict more precisely how well specific patients respond to treatment. [Afzal]
-
+
##### Figure 5: An integrated precision medicine framework for heterogeneous data collection, data analysis, knowledge management, and implementation of knowledge and data services.
From 4d290a40da0d80d3162fa0d0683d51837f85ae91 Mon Sep 17 00:00:00 2001
From: Soyeon Kim <37919264+ksoyeona@users.noreply.github.com>
Date: Wed, 16 Dec 2020 10:51:52 +0900
Subject: [PATCH 69/94] Add files via upload
---
.../Precision-medicine.jpg | Bin 0 -> 60161 bytes
.../Grup25_Precision_Medicine/evolving.jpg | Bin 0 -> 114592 bytes
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 finalPaper/Grup25_Precision_Medicine/Precision-medicine.jpg
create mode 100644 finalPaper/Grup25_Precision_Medicine/evolving.jpg
diff --git a/finalPaper/Grup25_Precision_Medicine/Precision-medicine.jpg b/finalPaper/Grup25_Precision_Medicine/Precision-medicine.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6ae1fb4f1c301abe0fdcd39f7d4da5c22a1624e1
GIT binary patch
literal 60161
zcmeFXby!th+b=o+k(82DW~n!jg%e+O`s-T1RopyTe--z&@dP9|=r`lCJ2eVFvgqnBKx>Km$rFPCdW
zyfG6~FnsC?f{2S>}F#TO&}O;>*o0ctIi0dSosda3m0gSKnUUme?<=At!?8kW3}oyGFy
z&^~$w?LD8nq&@fo%%z@Ai9btGG6h>N0l?3L7V`XmqH!#
zx^iIIwAqqwyB*@x2w#J2)msGsNPSr%6hWW206}P77SJ;>zf;&YV*SzDCN<@CR8sQZ
zdEfGY7-aoWmxJxsskck~kIa0ZQENC?gw(MsN*oJCgx*;c)VLOeVa#NTps%5RZ~ER=
zR&Nm01prz~+q|3JGChzozLPPZ53dqJP0hSXDmuEx-9(sbULB9#X6Acljt0QwK@!fv
zder1^u;4FMg6Lbs!s(CKa3r7RgmYJaPQB@z?2>yzwb|jlBXlLPY7bzdET_!f
z$9dVRPAMYX_!UXA4LjBgL-*-hSG
zHXWasTER&xE0)C`i{?0XHmH*S{)~K^j+<3OR{(n?-@4qy
zs!r|E3utHZ@^prDmeKOYbE<=Ka?58Yf6`n8|+RV
z6H6wa3t{J(#R&^xN3o7Q_Xv&^+!?6LfnOuEyHJ!o=?^p;Rn;Igpb3s(7xr%*Z?A6u
zL*TptQw{QRS_j{6vygD~TUzSww=`GL5Kr0ojx6DMxkb;Q);uED)Df39&o68xmHT8M
z+DJpgX)uc4>ikv8M5A@d@7H*hau?K{2g^pxeB(DXAG&)Bmza1TO%X=NKyLmzwW^Yk
z;7U$BcOW*K}S$ZwWxcKF@=REXGA)FE-0~
z-7jWoecGsUV5gWXRg`WIl^nkTcM~0ppBrf%T7-gir@a^eaL?n#fi&IgBJ0oj%}iKX
zPBJV6oZgyh?o?XWBu%1tD=b7m@o)`1i1R$~NMh`**S*aRb{GZ3#q443n7pOfg1My5
zbhVR$>T)XL;%H^_Sl4mij5$Yqv6Vmh7M1Jxvcqa}xTrdE+6p^kv=GX#GwCg!1%R9W
z-(kp*j74TfH0jkkz?y%GusqJUK19Am)ta~LoxVQI>7eUx{b%RteD{SwExA5u)jyqI
zNuIy?A;4W}J|&rM_sX=p(~jAXVxSpx-5}P<=k``Q3r8WA(-jSUP({gK1z&v)i~<0w
zI(j#$fc=6E|9$^@sfEq%0W}@R@ZZ2oR=eW%k@S-rSCz%G@8dG#%y-PWgo8{Sj^!=D
zeUrzruV#|>AF@5*){HK_te&=_nVB{2E32%kX?jDUt}OKWZm1FD8<^}OeR__5kZ51o
zTkTxXkV-�!~he|_ie7QRClaHS1T|4mp!z{Up
zujkoUvb+Q|JXp_WH+v=Ty<+jjV7dRY+!*^{o1`)-d=_;MxcOWS5g?X`JuLQ7I^=$|PhEDc7As4}BhKFbt(Ag&
z`+>;kuJ)YHsc5dt-5rYGK(^OE)q3RvQwy8oom8o=D;R#92I`G7(+4MKJtH?9axAG;
zr%JPLmuRP)#$b^Rv-i$G1>-%1&&bh(DUS-L2Eh)N%SA>%R+ih#&V<;Dts_9C7{5+Ea5C4P_ql3LEvA!227#*o)?H)F+_!(WORaA#8
z&7_gOuILnZTk`sud_0)<(G<_G1qOY568
z&aofdoZE@tpXoMugn&`A?dwm(ou8lPpBjsdSf~94g#AKhMn={TEo*s&loS2J&Te%j
zEpuf)e_es0kCG7p8WlnYEXz`O0iIhF*b)d(^o2_9wl15&;Q
zB1K3P_&jckcFSIQjeSaX;^x+zKe+s3{4UW?E})B`XH$XcdPD*wivo(1ffx(joj7Ju
z)j3bzC;G@}lRBj9F|?F`uTWFbq$itT#hxLO40*KWuO}=ITDiHa#-@*tTv{dW#L
z$pjv}Twdpqrsw>;d6yRo6)mezKx6P3)l(Q#!e**{z&n#oN{zmte26VzWa_J~4*Uf)H^)tnrv4dU1AEv$
zB#)0l%BhC(6Bbmvf>wPMF1D?@L#F(FkuhTLa^|0L&*PL0$JH%I`DfmUo!?5+E7=|*
zrqbx|BSFQF!2C{t6K?Y#vbksSFprnfo!#1RK;967IKG}P>lWGRm9pKSeOxDQV0RAc
zYPG55ad?h5o-^`x`}O5*^T^1^AxU2Z)`~l4>6J%E-gO&TMG)ZAl|yphA@#N1twxsc
z%;RnlK22}Nj`%rx8!W;#{t52iPUS`8%HTH9u97xW__=WFKI=cOYk!eFG+u1ivYl{g
zotb?FD2QkUDPF;zVf4TX(posP8{qpWhNo{1l
zMciVaZO>6S2lH)uJ2o)cD_rR9NFRr$l-^fg8$L}5;a1A8*e!r;i|
zL8tyP{n~f=Oi$wyS$N@^foy~Vm%%kN*E22X7b3*3#fGs;;
z%#=`}F<GN!nku9kVwqE*5rjy3gOvhK3I>#+J$%I`G
z5_I$VKEg_alB|XzA@%j5^n!QS1~JUcBsTdkWbmprj;2`{`f>&zZy}s>Y=t8|mKZyF`}qDSJQT
zGL{nauMJnjJxOLI`9I>^VFnKypcCnh4;Kj;IFD8}5?ALHE_o+!AmaL(<}?%y&uNfX
zT-fPo?aHPJPrVW&L;JP&0?vTy#pBsUFoMQAjdL(lU(&4A#(Q$x*{!NpUFTL*CzKRL
z?+to@wg_jz4Z0<{xF0zmwvS}@sq>AZE53gh_Qgd|2KV{oWh3U?Wz;W
zZZ*lpVG6Ts6U`M{Y0k{{oc$|Q$DD&z??uMf!$D@&aN#+Zr*|D-rMau}a)wolp@Pho`s>G@Vn-uoX)nzwwxU;&pLv}$x_Z`+JiY#B11ALK);nWoRyAL@yNdunh
z;}dI&Ee@hkm)*Pq}8X!gYsb4-d`_~vw6XB}?~qVrGXu8GG9
z_B5q${k4Jr8NfS8{|5L26a(D8FRr8*((uFrTz&@^VtfDT&Hr;%@3Q_&6aka~aQO-N
zfhXS(j!Yj9EFWLbg)BK=AK!B*VmtX4L^bJ_do7|
z;E0qJB>A6i9q}UGsppO`t~Z$)1IyuGh*%wS@=
zg3ZL;lb+@D^?`?D?=*=jF<4Dx0l=?cKPf~hL=o0Ug>L^47_pXW#a_FHY+ZcrQChx@
zX0%oXIbz8)jfW(&V_l784Zrx7pHvA~{hk*^$?mJdUfn|ZZ@MAQwRPi&o*0p_{K~%p
z2^cjHkPN91T~!Xr<%!*4-Iy&BGPS0Bky`R~^
z4h~$eqF^Ng5|lgdx_^AW@3^B
zkE@iQ#OFxNE*fLyR_&_o}rJL==IN7i;HwJjExiUY=t9x8YXR
zjcC>U_qDu3C*3=b#d9lHu`u*ZxR!96RYve9=$aw>&xoB)*^2LFTS_2vH-Shn&Maf3g3?<~)yexjiS`@QYGqfcH?}~^;
zykvf%$V&;eWzn^>oa!&$$53y9>u7PlQL8UO;#bO?gYi_xQ=9XJW*uiP!~aLc
zi4&7Rv@n|xxv%R}fm(Gumms@tR_4iS-i62uEb6R~$I6vgb
z;IfbpwIF9?uv+Ni<$HbDc=Q~FRb&1%bMIAJkJQdWr-|my
zHdf0aeU8geB)_6{hJ_i?jFvFWweA_Tkk5>%iYb#0tVj)fPA#>v_1c?)Rg6um3sEB@
z^gH&LXF>4R6HM09Y#Hr2hgU>7_wk&u4qhLV60T+J$`Q{ihxxVotJ7>)((L5FBLp+Z
zT^79JlI}TO_R@Z;V0Fh}$hh9$qAPhlnmzGz%6pJ+-0hfUc~k#y(NQgH|LR~Ry3{3>
zMkvgmFKRDYcMB^zsn5LH{$W&>XRK4z)zy~UF$s@f=zBvBhjXfCv@02+w?02V><*K6
zWH?=KIk^koco6TSWWg{2?fhS@nhYl0$%DmTn|y4&qSF!FbzoQJewQITFd#dnjLFI}
zAiS>#k5wV2V%7zj4D%oP9}-L@x-;rN+&3x`HWhQ(M;Q-F_zh@_X8noWVEsI3RaxYH
z7rgc6ZN{6{43RIrO@%FE@7!b8GAmXlzBcPCv=o~K2Ybr<7Q?eA&XZ#gN?D#u=Br&#
zYhAs#56rBrz8i}3>$__SZs*6EU5Ca02Y{enG?R)e*`X1{`1zGzPW#;IpA=nQrJGCt
zjPsD}pT3LbKDgco=`+z94PyC|f1*_^SoPn6xdgHO=_$7VXgki6xKVzWzK^qw_~!;s
zhR2PxPZzE{iCCD3bXlKNRWcr)!g{&@#D*}!jLCwk584AFp*J~wA6V*rJjw01*RQ#j
zql9EPcueVxT&?OT-kH4W8}L=xN&eNU60wW-(!(vm`Ue2Eh}7DqLfFgUVEm+P(5euy3pgf_h
zN$HaB)$u%@`anOIC2{!bl(2B{AdPV*{c`l$fo0lTa!be8U|dM5H9wv9fPu(PXyBHf
zh;;coSec`W(VQKie9&q~iY6vU>U)I8fbdJF{u(8%>FXA3x7R4FD)X*_-(57$;ZOXy
zR{q7+tKC;$(?Yp4&TC3e)QPXW(#hRkPM7?*sfI9%2bcZSmQilLr(`vCs0qdNe;l>-
zXx^=32$v}n(yk7=tY^#`R*R>apm<~^=(p;1oex=cMZ67JV9!)^e~o$nl4-v_7M>qh
z{D&n;ln5_}h+K@iqFV>2zduS6Ql7i#Kcen05sN>DA^Z?5X-q6$BltQNWkt8bV$E6Q
zrplBD`!uSPUpX0-ON)Z4v>%+C^!;lgVFBp^H&YwoLPhhYFkLlk*K*;z>0SsPb80<8igHH;jr-SGUS
zk6qqqTK$W#+=gY(=eT&4YvgcZJ>h{$I$cFZ+q(8goAPTfpQDmhu8G|lm=zwid|g#D
z_0m?49fY3oqhl77+-gUT+G_sfIybp_M*17*d{WI{qw;t3QV$c8Xo)Wgz`&5PHAN~v
zY^%ZTUJ@;3l6Y{xm?Y`buID+--Vg=?$s8Kzz>p}IHaE}2WiVL(f?Gb%u}gLC*2m1S
zvNO$sZN=s97=TAEZX)05d!Rp@7GmPXtD-KZ)>c73xoPo5bf3Wx3dMVl=F};FR=|+S
zV4`>I11qA*I6L-lnab#19CwO)3(To!mK#O9>YEPx4WM){h-ToCyf`M(hx$TIUFNZ6
z`2Df~Y#QYg80geGPa&Dk%}cfJ1Z!QL3Pl$e-=9j;|tbrn|iOKs4xt-gqI^BKng|Bw4+mvPTENBdpF?!>6
zT!(eaUnQ&>4fVQgPOmUXpTstfTL0Z)|N2z*#*QzS-$lu-YPItC*a7Rc
zwaZE#__NsG-6$fap;}-{mketg#y6B<+madO)6Cq=q6GEC%SE-)FAaJzj=uqe)aXtS
zXKB81%Ywd04@G8wrLE)Freo84wSI=f0GRa@c)7n*I(M)qx1#?tGtJZS@o{9OG8irx
zHX2X27qDAN*>dTY%)DiSv95aK!2btxTn48T&^F;eia0Xt5)b&bTDt2|ZY}q9HEN0Z
z3niCS|HGXGEU|7!;5EtgJWC)8cxwULL8+3W0d*BZm)`g*YVj)cMX&_j4k`iqhB
zpY{d;qKf1+T2K}9)uq1Ea&>5;$hO6v;IgQ7rRd_zu>3H(UgD>JxGwW96wK>juZViy
z-W3wD#l0{6ucVF13Z~pcS#07_dp2xXy@92Bl3p(c+9J|SfT$<5(uCr2edQlMDpk?p
zO4$y!w6JH}u$ESA@?V)+qH9EAY53$Hja_*9g`HoR9U8@$rfnGkaXVYdeZ8~OL2?$z
z;jn1c)iKLMv)TV$Iq_psR&r9hq(v2r>$IRe5T&8|<86N>Z!E|9hm#
zU{%LIA-G4z(3$ItKaIy!bm>0vYs6_kd;jD5^w9!6+DL8LWaMIsih-7`!c{K*{|?5rB-`=Lp>V1{7LPz#;?j9YOm{FS$bkbctSNVcQM=foi0l
zWkG$#AP?bhzz+)68DQ#PmJ0DjSsUDGXgI=(4dkn3aMCXXfQm?0c!B{_R^
z%SPhVW
zfO|s<05bp}zQ_Vk;{p28M=29VmA;pk`}HLNfLx*iUVdLQ1sJqP2@Si=u$NfMwB^+n=dgmJ4>ts5bG_Hno&ovUmCHmg6~b$cA-__-6pb_(6@s;_%I1?n-i-Oy|v@sN0W
z!e^InCTGXx$jVsA6(lFH90CzN+1%;NcuWYF%wfWZ^L;2&dVPweuxg9ZR3Vw`J~u#E
zNIJT^F`@P{t$EGNP6q%mbf*XLWd`EyE1X)qj7GmV$`uD-K+?zN`U}#Q1T8+Q!eQFA
z45P7B;)4h*iE@r$VYu3Ue2h5NUoksBx2x3C<)8roY!DsoKXe@8Mxi12C)Vjg52FR@
ztvd`%Roq9!{K`wy;iN#o5xCuIit3$g64Uv+eJ-l@4x$X)!oKw>(
z#U*?Uuo)Rx7OMVQVP_S(UQdK0;JiLl`ZB{FvfGy~TK9v6OZPblQ_h7$`Og&*!B&q5
zxHKj{b}!qnUI>;>*{&z)uCsfE%Mhvn2K9!bZ1yJ=uTO07;UIZ3sq!66s2mquK~;oY
zBQ9;(a8!l>gQ|}o)#fHd&G_J3L(f#OG&3Wz-O)UOm2Q{BE1QFs9Dt!$94dR|yjd^`
zH>A=eQN9)9vp&=XuVd|(AAjUYS?Uaca+T$17MyGpr#?39X6cxsWQScobV6p49vwKxvYSh@Kof`KzJ>9^N
z-D?O?c~!`-rrF6MV>Z{oSPAqL!9!p^PqrwS@8&oXphr#HCwiP;38g{I6u)R*06gm3QCN_V$(1KUkgn+-_l
zf|b3?=11V;+s}k=|FT#;mZfwny_Dvpc~9Ln_qheK%L3prbG_w5ywK28IE#B(@dNn@
zvP20V&;rojhla}Z*gOKVxpVw6Z;b5yE-5@n9vzqvpw*il3B{2C3K}hA;@?jQk?!DUKR6#1|
zZJu{*05gmtdJwfasZ!MVEJSm=)eeUz^W0m|anF621%n@eum};-K?)^x*(W}6*%p9p
zJ1ck@F$-}z?WAOG$#8rC3>5zu|3#JnlLW$_EP;gckJ}%SXTCWXInSQ-WdAjaIw&kzvFGh_nS6F$6A=Ia5%E(w&-Ax8z9!|GpgiF}rBLmY
zpk+=>S_*f!pX2Xk{0g!iNJ;N76PGd?%p8l25c45?6^#Z`8bFIn=a(vRMTJj!-{n3_
zWZP15wBN$>z1!g1;(E<`7H$&xh>w{Y;aA)k0KiSaeY;=9KINvnvEXX+`CWZ#bDt&1
zj1k`$)mSwN5w1@pZo_i=k2>3Tk5;OoGir|)VwBrl5xK&X58ra+41#I`2*lhBj)x>X
zZ5yrho3zk&G^(W6TlXv}YPa5UjM#tvGlR9xBa+0#c`5c7_jvhj%%OLm!dF^$VcoRI
zgaHY-+Q}1j9^ofX*rqrH$=Jqamwy@4C%qq(7Q5lqtfWZ(qO0Tt6B+yfSc3TWF%gY5
z2Ys8mmGtwuthZxuCW6Fn#zeDGb}wCc4goSy$P;2wOfgG?nxzua+!k6Y0HCGwWG~6N
z))=uou*?WR0CiZBa>2bK5IULjY*N3)m83ZTL2Ii^fwg7>xdlra~
zUY(qL{{xjX`+0nqhkMF~YiWMYGZb{Xj!K8#)BV7AVmeZq$8v(91b|amBQP3KX9sBm#xkVUrYEkRwinJMAQ6Tj8iD7{ZYa2Vp}?Jbu=|H6Uy
z%LPn{L5Bw26v%=ug`WZRMVi~$(%7oVuZY9lEHX{f;uIq71*Vn`n;!w7r8mqu2yVDd
zPCz$H26-$>8xEq$6JLMvI32}e4nEPJchz2C?C3DZ*vN)HYD@$Ah9dS5+F+5fH
zLAic{v|I?GhuY6uXS=Y$YRr@!j#Ea6%cet3o66;NyPm?8s3bSX%S>`$wO_tym`Tb>
z32xM0=-hmBCXan?mrLnw!vcn-j@m&1Vo*7wnTHyF?vFrGZa)BMfVfUp&yr9XqbfcnZVvD}Xf>
zMqcZmYg;Km=86<~wzeS8vpPq1?PQ&l4u&BFVvhiX`5N5?k5}#L8CXIHUk0o9a#I|4
zHyti`&N0ClbTUb|UG@f-9yLHW4-`NJ&$9p+PFPHZ
zFUiRVJ2_r`?s&foLs|yBelOsj8Afrn?y0-0DV71u_5U9JU_YRR10WzFBA}q4-AB5A
z9{~vo8P*N}$hbIoRGd7{E)Vg!xSay4?-Nk-N@{B9#L_&`HhYsJq49x`R!TPLGoQ?}
z=Wny=q~p5GEovNH17gPhdczz+9QX~~yr4q}L<#cD834vW{(ku$%
z5yH(ROPc(Rdq=f`0U@VUS4bO~|8{s^$)@AZH>>As-KB=5ib^|+d#T1N$wzM+j8SRw
zP4<5g8XD%6fe*jYj}dJz`4XiwdP>@Inh9|pnQdhMtWw)I;K0p%!DHE$uSkB>M7>DM6kUBWdl^Sw@ggp^gn>zFjh!o$Q(yg82NdI4F;a+!FB
z7@kQ^sP`(DnHJ{w9e3zjXsmLwhoS{zchTvoWqE0&ostcQV{zVu=C81QHERqnL|zZ{
ztw)Dq`H2L5EV5I4M3ThEN@peZU6pr(pt^T;fQhs#Gj;-ZirV&WpNdSrAjzkZ`rR^n
z8c`J58Hj=4#Szx?>~gwiHXaHNLpam*D2hnBDj$0uH$y_v`p}y@CQBb4);UQ9{HlD6
z|Ip4g_6c@L+ELW>d=(a(cX5%++OVV{mifCXxqG_vN40{vgvxKS0Am{8j&%|ZseT8x
zn2o2T4S9-B(%h`@q0q^}wns|e+=d`O3vx`#j|oYon^<=+iW^Z!kt~lSOv;cIIt+6K
zKQ=0gjfO?jhpL1;b!20>bRBs-s~__l5HO)DcY9Ia=jkY=*a+R~XP(=$1xjwBuu$Op2b0&0E}9HU
z#2;5R4xdk@m*31{_G5C@uQ&Mq_Ho
z;4ESePz15&4pmme=?s>tAgXB%Vu_^x^a*viCxrAB_Bni;Qsy{eaoSPHrty&JP?Abw$ZM2IO1{cFrCr;CGST493N0gUq7v?rC!
zPc38}e$HYg#m2T&cZYq{w79QD!6;CX^&99N{*_r85zl^AOO5VSkd&I-3bAqAY*?X2
za}bED_Vr|RVS
zl;_;IF&cw5QcisckP+=~ORAp24k0w$(H*1uBa8(xRGxD0QhI0;(8!~7Vi+#vzY0$U
zZ~7AWHb~1hzvAj5)qbjt&9p-Q1DT?1b0)4~)|pn|dLKFMD9i>CCEnVmOiEDW!|aCI
zZy-Enozq0etIjD-`VRNN|8geo&Hdpkqb(xB2N=h$bB3|3s*c1-&vuTnw-=ISL(K8)u
z#c{vnex^3*eT!hCnvFeAVKYh?cu8OzPP{v~*EGr&xQSNDl;V(TVZj%JM_KBSfzeR4
z8wq9Wc^K&_iV#{u&JiJPgMyyc?f7c%{{3eoHWHA8R}?1P6rUollEkL>=$}kA_mGKo
z)yf)7Zy&jP5xqxKe#84?qlLA@cxEi~qXc3&W6%bR1NWAMCuN)NCJW}WzRd$VYW~br^gd-kQ0oEieAZ(;?`Q0(=dr(nxNFwo1`HiRYvx@k0yxvG9!|11Kqn5Kmw17|sTF74E7s%(As@slKm)|6gq
zP{X9q=YaY)h#sFs&e2t-MP58>%25W(#u+_dF#bI=jRTIwY;~3h&6IwmV>(FeUKy_-
z7F9sofO+QZW8rY*FOi}nl}E{+0~Z)8nPxSfqmxR#m((a2&$f|zBDgq&DV*@5^d;Y8
zXjW9^rOP@Y1;yEvi89X`Wvt$O09)8md6J%4d{#zHP9W_Q)KBj|Kpssv%$N#PjX9y~
z@!sb7F5>joTe@w~>2uM_In_N(4mFS^jXNrD8xU=mcvq!a`533+yAWY4n$N^L-JGAt
zH*d6*W@e>!&I&j6*M#&n3^ICh$`v%~ssd3ptY>1&g%-xcM)TI*K;D_~Z}srhaN4%z
zHgq!bT%)nDMc^}0Xtm+s{6J2!Zo6sa$#41W(95-nT1l_bFq=pi$f;#($WF<$@YKc<
zd^3E5&SQcz)FCVWEp{=lZBwhGLvMvR9i9Z`N%>TW#X=s>xJzPQ1oBgwPCUF+U*d4~
zxNJAGIlk=&JZT%nvRsngu)}*?GTJhe4@nkM;9p
zo0~XgelYr}k!G*OQ@ZM~nm0n)O;-gaG*lJ@LW~w9#
z)%eonc7#5l@39sCL}knon=#~ZuW&gBFXe8?*v~S$Y^s7~bd|5W6vIIABoZz2W-!&>
z{|!Fan|+XA#IZHvf8La(rNnu{oFnb79g3zn)HhzDfCfB}W=+HoPB05o{F3VMlI32Q
zloU?{-u1jWcdZPocYz5L9-`mB^lf4?x(|dkg>!Rk-
zimj@@S|LQ(cpu%wFv6TV;^DYrk5)`wDX${c_4`sC*=$+peToQRVAt%+bWl+s(j3ubXk`b|t$neTO0ZQBq!ZC+PJum`}(w
zu3!3(vQuMGD`@o6J(HEz%2Ly@bS3n=_0ts#A^bqlDOuEL^<2eWnk|ohInM32+<(KM
z)S_1C;j3Z
zb8Kno{e41!02kPLTN-WCt0y5jU&F!_GgRIiG3a&#h$oG#GNRhXsSSIT5q6V08>_=
z?aOp$Fx^B{+fjUtjt?@y!?HO2fl0I?^_Gck2aE6d&m;%rXv$2FXzoPEhi(~`jVPTFcD}>LFv3+UdL(h
zX+K+xTEICcwyq2@7InP6{*1&|XuOP>yRG(t;4iv|=V!asO^PvZIfGPx1JNYSN?v5L
zViRVbZ=a(T;f)EgXyH8>p5~$Qnm6_DV{0t;4rps+ug^ea)Z&}y;i>qr|Mgs#(se>q
z*)Xtj;kkfRg*U{BnE2GS{6sgz!X?aZfb!DhR&^)a@xFqw&N8y6Xob3Sr7)L3{6ROV
zuP58JypsvRi}|E(UIr`wca`YTlgf+4xD)CQg1gkcYQf<~70{z=tMj-G;f1{8BC~pd
z+5m-O7n8&q9Y^(QLA-iuNkw{QlJ})XcdmiKr=b%GbP0r`j!620c#7z#`aR?Z9!y=N
zCeg}aCy&#d`gC;a2^fEbvu#x%Q=Jvg+6r&Q43Nv^KVVpve!$e5hA69&a#A0g8|WMQ
zHMkfZU6Dy+Qr4jGI1itrOf7xDYhaL#448IaC@f~dY;jVYbln`-++P#2(#S7YV=R`5
zb>^i0LKFr@Jrc{wwt2mD8S6#OOtjlY|9t(VbX4qM8Q*I>3r|tbv*}@PJ6`btdQ~&0
z`3TKSJ?mlF#=3!V*
z*e?#L+0~bJblz$t>KvT;rHirFX=;LQBxaTle7XAyLJ-~rCED2-9yS(wtlY(NVsDlk
z`q#SA7N+>OH@i#43B@5X#!O-{I1l*!tGS$BqK`F=Gm|wGe39NqzE_GHSog>LI8x2!
z9H6A=eX)AA3QCD}`9hP9_;tk?TDs*7NG1-E^bJOiEEI}DQIf<}P^RrZG8<#s1!bj}
zoCG`ki3cr%vd^xN>8Ys@iZGdVTSN*G7yEFYlr|yS_BAu*^VBsgy!B03Pw{3RBX8#X
z(Xg45H~F+&#y-2vk@-vh=jSi1Sfc0p(A(+~jm+wHly&<#VmBPGiRbEH*l-A3+fEjg
z&=FEYkDlI^aTepI#s-9Nej>Bo?0RJOZmft&CviHD?U@(uJMnVE`&{GV^g6Fu<@60W
z`!JboFr;GL7;$VaBIUy_<-}r`>X>@p<~>)XEy$RElFZ@UN46(9T5XrGcxU>2hNU^*
z%c2>d)&GqFVS#cjsaVhR+`KIO1cv1&`G~QS(_8^M5+vWKshN~~yC1Nu)8hqY^cG6>
z^h;wnMy1qMMkLV$NB?Az8t-?v75&;Puh?UiZF3&TWUWP*SM*Hs(}t8zJw4TP#ZTG_
zLk_4HTK5yiYLdEc!$=4V1`M?BXmeR!_`mB!uigt^%j~TF6v_Kg?}~eg;6b?Ev_7+I
zHb<_oSD89dc|HC=gm~sC*-<^XLH~J!#mb|Vo9MIB`=bY&hBLBJ6Ds!3*BQLF3!1ae
z!*djSMZ(&?JL;;UEqrXwt(k*+UK<`f@iBSvnF_por0safbiCx%R7|w@bMx1gq(&XJ6!Nm|1nB7|t=lpeOqIKpNs@@0RT5{e
zD4mL*(0$SDMOM5B1{6Obs!G+hT?M8iKN!bJ9K}lmkN}?e_%i%7RGLBqa!Xm2z&cH(
zSVyWL6{$FC3F_K5U&O4gm!$exYq{gRQSsLv?4EKzF@ELOty>{yEAHpQfz$z&$W^Y3U%
z_=ZOw2?P_nZ;US(hdpdAnEwE-Nm6#hS(UX$w
z?58x0&iHB;*{X6Ka$2G3PtsWq&y2el(WhmnH@0_mi%IhuTI3p{^)J&N^KPH8iBc!(
zT+CEER)|}4OA2?6xNw)xV{o~q%LmvF>V!0ee7Qt|_OtV3u=QLb;atvCsqU_2$
z%!VaxyDOkS61{qC(m0lj}7cc)Tkol
z^bNUhcrX46m;!31mi@jnRSLY0M^2pP?9$j}i96reocH&dpeoN}UH=42*7WoPk`ngu
zK3rZF8~^tuk+rqmYPzn`4vM=oSFb@o>=-(0h0$
z7wTY!U@2}fuA7oqy680Mr_V(qUqwq|Q%Lbt+NM`7F}SWKI09evo;5c)bRbA!xa<9=
zRXut1)dSXuq+U2niijKMm>q7XsjT<}MtWL2H9&hvs4LJ|&4!kwrb$x}?cy`>1A&^g
z>DqF65@oF7nk_j-lHstAZfqgwPb4R8>Jt~GzSN~zTeLDJrNVeS)Hh|tW2&;DONHq?
zp_ME!ejW36O-|WhAopcaL`{R$h276mimx3^*XOuSRRf;(w1h%I_|uP$Ys1u^@AlECxw
z1q0y+s`DAkqjjfI2jeYD`=x5b9n^#W4D7W_mP(1&cmsHOJ96>xa%4*}<2anU9zXY}
zXky9XnLtgRpDWkm%V;9K3FdD~YWF6+(;D>9oRrn;7}r&sk_?q5iluQAcO8xFN$d);
z6`NG0j)Qjh9%m`z&0$%^VsYhGO(Jl*g$wd^LR<>1pc9wd~P2
zCnx=5eSkSfk^On_NlmdN6SGjTAk$Q)RG9pRWfA|E
z>qXnMZFb3*@?8@a^wQIPq!aaqeghBu2+Ze*dd2;I196QIQ^S(jeiNaADbu;|m0{k~
zit-Pcp${5NpBjv-(c%5&vCLnXXqTD3OwJDwlxbUQhoh?1Di9YdoMYDN8{!!&wU^Lo
zY3WEw&}B*>=J4o8OjsFcC!Te6Z+qV`s}Zx7u@wzy^{MK=ieQs0l*?PgQhtbmFcX!#
zMf@VGJWKvUO@WcVtMeJLv6{D?!dVzq(3=xn6{@Bk;Cu}ZB~N-Mb)k`ccdQG(95qig
z(??S&vLKCu$9Bl0;|teMpS9C7F)GF9AcFiI@h85C1vDfkWbH5sM7O+<#ttknR{A7>
z7Z-&>O@*nJt-+yb)zM&xaSu~Y{4+c){C|0eESD;|^gfn6wf9E&2546wPG?bWBz+Ve
z?9r{U5_>!G11MM8C&3YQ;OJaWlm<&4YXde
zB7Yg3r{_5`{8{v)7o)Ki<`YM=7Um`X^x9B>jR9Hv;GH3Jg**5wi>$2t!*@LNA|C=Y
zkQRZW8jP%9*I+z=ZhTWj$3+b>ac5DWv@7O1G6GNH7FjN_UI1q^HyakC3V-xzb4NoA
zWA_&)zsCkQ2kzi6l!Yufc1zK4>=qt46R~MNt4bo1f0}=yt!lJU%~mvXA1CloZ;e-H
z8*laj>X`DN>3E9Y#_IsQlcq94H@qcd^7v;=PKHtoP6-5Ydy)jt-M47^9y}R~&Tuj|
zs@Q29GOHOiw3B?C(XvcK&(Voi^;z_n9Mmy6Y`+?DUah`auQVx**uFJs7+xOnjIp>~U>%`LCUy}IJ
zq?2f~okNSqyN#N=^o=f?v7Q0VvP1V3Bkt#Tm_l|<;1WF~Fu6j&NemMyCfS~DOj>im
zGk&CG^ry|c1&g=(FG$~J)?dOR!FwYZK~F`d=bseo{*YolGt;R*Sp2A=31XV8t5`W1
zw={fzIq}}mvf5m~w%aaH^XjT;+F>!r)?CAV=Nf@6uXLdts)v-5x$j@aQ)FDCltYRpIDo+k;Kh}|!^%cdM~Sy1f4w^^8&v#^=Ex(duMe(w?w
zQMcA|aX!WPS0kWZ#4~Uv11J@UcRUM`39BW3mo1bhE8N!Oi(LzEhR(UJXOb_O!3rbn
zvh}AEEQjFL!9dAtm*OfMoZ1tBw@YedE^|`>gCXic?hQffBv=WDMwE&Y$3IeZp2kk`
ztNL;Y8MZne9gZDPm^k#LAA<8vT2ZQ-m58LmD#~6~{}*7Z>5>Ck#vVxuzAAJ89a-67
zK#KQ8ND<=CF^Bw1xDT!*8f44aKHUYI5ipLhFvNKo&V3G__jQ*9@x~GA2H>z_g5DgE
zS7*R?`+g67T<1)l85Jf$N5&;OdIv0Q);F%0Fbq)g6c)Pg`UU80PQ4T(Jt+EIR-)>8`F3RL`*ilS
zUA?NwW$w2~wY=l!LUtTEnOPLKu3=u&P6>H3=UP-XJ80N?N|tr@g%ja&Hpyp3)4>s6
z&eV-E6M$`KPh!ZC;8k9hg3s=I*bJ~EdbLF;>u+4A|
z9ckX(Gx6O>O03s4+xgzu#5O#A&jiVU?Jz_tq%svbxzoI0gx`e=qv2>mqVossS$~le
zx0s2Pk}sX>W`meYuTnq(EMcTu;4eV0xPC9{e}fIxD3(Gd)Sd=P1eIX)f`e7orR4a~
z-QvIXh!YJ)+IXTU(8D^tF#*=G2Nb~Va&N1*;S-yR=p>4Ews-KVSh~--J;(PC;(lr2
z;UPLXBhVxP*`qxREwGO;4MT>HH~Lq}^XBmkqY11+&nLU`fq+t4e2o!VcWuvEDIt`L
zYCbt{B9tU3gC<3&C;rE5NH^Lc
zS1xt&V0!Ik^+4f+sIU1qiSN;0OiL{j<3h-*T`o?Qer*qIi8
zp9hzT)!51GSGCtMAC#}JG_Y6F7z?urwWs{mn@lP`Vepfn^YY`rlL@V1C;WpdDB5m+
z?Ky)|H!hjNICeAUei$T?&sRs`EVtP2k7%e_HDl4z)qh&35hU^QsG`(GDoe>D%F%U-;q8v&v*;7L{9BKwC(bu
z4;UuUk#D!pp97^V6NDvr-`N+kI>>UR+FvBMugOvPDn4O@`Sv8cXH!k}a}*7VmSc4F
zZ7*KIPk%PgVtYIodH@Gkdh}5?Az@d;FTgtD-z%-(7i_vxe(9e}mC`_cd2}_^lDm8u
z(-?H^RI2S1`7^df9hJ_%)WZp+f72^~AtN^+Pm`~hO|-H
zCBLo`I7hu%?HqNyJ2?OOYguQp2le;-Z>wkShv$Q?gT`eaAU~5D%kt^s-_PpLFZMmO
zv7ba24RTm^7#XDKSA>UtBR=}j956wu@rg@%Nh0Zux%NV1ayT$Zof80o0m#|1DDVU~E$Nt7}@6
zt`gr@O6-#^LmI3hFVEyIby)riT~-0wyWyDHAl}f-Y$0QBN4hpEGxt(bqs4hjs|cID
zhsDwW^Sf~H1T^ja3xRRJb_U-r_3-knHV}}`4p%Hmr&$dqg71P1aJ%h8A;
zmgHXlbZDDus<#l*8~uJ-Nba$?)B9;(Yl#@0Z-&ivdd&L$#YvHAXP>Ed?^0`r5)YBk
zzU#C!ai~Lm%CAaD`q%PB5fqZMO%hI=8RIk
zNRr;3Le(eJ0}<(yII!c{9dP9#4C@5Z^DzpZpi6$_ZUF1J$T>3aFG9A@KdkHR2>rBL
zDH7={Uxd<830OeM=JDVy)b_^00+4a6OR6M~DaL4THMy|3uBl2LneB;jzV4m?l
zY%VUd!;i7WWbI}
zrjEatxd&7POJ+0EuD|^Uz~AyNd~Y}9)sl9)p~Qb(Hx|hOh3z>>9EP;z8De)edURhIlF?t3KhPDnS8-bT)Wru;l@^w-1yr@dX
zlBw#apz}`0!p@#NW7SSD-cb0keep?Si}Z)*EYAoO>SldapVHH0AXHFY2y*l3DRo+-
zJyUZZ3N#njKC=JHz`wA}r0hzzrP_qZ_A-DO2VV`LFz{_%LrEeBK0R^W6%jd7_G@R3
zul&39Hqx6$oE-WKU9YBQ))%@QN+3a0?^sKfvBaqi%td>10p{L4OlzvU{pZbq&T}0G
zDth;PjR^u$aB}oDuay~oylTxQ(3g1YA}#{_)aC`V^Ypub2w4p%$vc$3wm^8rG_u#M
zJ9~s-puUE0o;a6`Z9GuBV9YTq(e4Ar{lDaEYgSv8|4;Ju@!KBBPuDdFUNKTyIuGFC?ixoQiUW(f8o{PZ
zLYtc~y~OX76phqA9??!2q#%$LVT#;c>Gxh70BA>R9;F|uxj@m;7~&f;sPx>Tgo51=
zoVWnrLpYdt`|Nthgdq#TvuN|42w`c1$|sr0jI~;p6tdOXPB8JkL{5GiQkvIs{yH-}
zrnZzTHoRYx8S4+Zq^)x(@1^0Gz=4?6(H@pyD_B@u-=76s3vyJ*h$~N&V1wXc8F=O>
zgCLlj%rTZH6Bm)BP;haCx$IhfQ6}G^^exjHWL8SUT*|L%E-YsTwPc`D-Pi12!g@06
zP9hTA-o;LE+y4TD9yP@a7{zz!2fFd?C%jKo`#y7_^QjB4y8Ux+KQ)ZUL8=~;z6yU%s-9(5>6GoU>WNS9|z|{UEQBE1O{?px4X=GE_R0@z{9@l-y^yL2!w4Vy1BElGdGP*T#;VKw1}irpkuixq(cemN
zFoYt2$}qb*#ra!IK8AiS@^vB@Vuf|eg2xa
z(ej@51K(L!Y?0oRJr~wX&D{Yr&!!LaC#zKO4PnSdKWoz?LaZ2g&r1O~$&EDw8tJxc
zCdftVMFuCz*$->n-#r|w_Cq1O3UUoSg~U$r&4ZsoW-etGbXNwR7T8t+x9Wu2!0*3&
zH7<7^vqArpbwLkVH?o?eTNa)8mh?7>_15Th9<+EaXVaobKIYKnhQ}Q0{_i#~{s$+{
zZ3ce^Tv+LQ`qRWa%e29tCeW$$9fvkz@0o_BvR?hm->-mxN&`xvvpCRkPAH{12Rfy!^4lhUGG4?8nua8mlv@G#&_qHm09)xM|>
zYN}BQW4hp@m`5WibQm$k#nBd|0*I1h+`+l&lJL|Sx-$o%pr0K4@!5}r-WHl_6a1^F
zia@ilup8rElg)iCm_nX#tN8dPGW;}Soa9K`U`#UuhG(gv3rC@Nt|g04wQC@hsA5>bAjzIxC*y239KVR_z0q%Ea5q~u!4^%ar2@R;Zmx-7LTocZ-@lGr#|m$7)BzPj1R9
z+5-$GFoe}Nex9xM?u~{v3!u%7c5;O3Dggpj*HW(8adn|fn4oh-WBK|Ns(n`$-kL*Y
zEI9oXHfNpCi3?Uia%A6{1NIlx_Op*VqR~A|Hz-7B%~wthL_^9;woZs%G=isn_ayS;
zL*YD1Ow%TgEYW}~z||Sm9}>7AsV%>ukwpc8=qMt@9r?VUe;WsdRQey`bY&n!g81eA
zH0=P=oehL-$llTgNBoK7KsPu`YYQWS36ZgNB28!a>mn~FGgD|
z{32@Qu{sd_p{5IxCoW_PJ5xfY;}3My6!Q57
zu|Ru2$(og?_JqHmn=g2p6_TJP!Qak3VtfzRCS4%S7&fSaM8zKkUAU?wN`Z`Vcd58X
za=cJKOBb^88%Ri5zlk(L*@g%qjO9$1An+Jg>b&8H&1CFJ4W+@+B;Y>IE)7KnRdFiUq=ia<
znQeZLn597NdD;9fu}y)}Cty%UaY8jitLh=pVOTUZ>4u72|TD=_R9QmaRAN1
zm|FzU0{pqx;M&!=>wDop4BD1Ee0=jd*wS>@@i1AP~l2Dng|~){WcBS|fV@dW4pa5m^d`5&*b@`LjedS(yn|2~q&#*wIcU
znJSKIGoW1OWy^5LIgp5`w`jyFvRT?sWp2_Ukiihsub{n`k)_4qj#V-%)z=tuz3ru(
z#Nli7>ylCm$|{z9;rad*Vv3yEmarcTKEHWLj8Bin6ysuS8D(Z~3N<($yZ2#J8=Kb{m1XggN9A1j{4rggr8G9rAmRz#5V?~P-Af$66lr=@qEWxK8_&n^dZX+MxBl}`xI7iM7W{1-YiIIZ5R$G
zQ^^*arm25zqtruTZnQw1p(+f#5T-*iUg7uU+zA${^4F83KHaiF7zka;rwxXY>}9k>
z&$Q$RgXQ04d;1WBItFpJ^V)lyVGl68sIoFDN>B?OjYMtZ++1CgDHIn^Vaz=Nw<=-J
zGdOh-@!;_dU-O2&{0@_lN|yQD!U|1Y;d%MaItddh$#|oS2bzo_C#142h_Mhe>jlQE
zW=DloSz?AnEBmWcWNl_jk~6bu(E9U4uK)stg{L0qCe?;a=)GJQ`0UwX?$Z1{(k(Qj
zr)eS|I0K@qm2r(mLe4W$H-o4QL`&qv9EenS!maT?ixj^9q^P?YsvYH_G}oJ{M>V1e
zg3lcDHG)&h=RkjpDB9NI$ZjBW7Pb;d(IAZoTOOe-%fEP(+dG99h$fO}+T(ehU3>hz
zW>PNgp<2XH!pZ{cODq`8xARxUfr{M)vEQC0eY&N6S1DOP1!4e4eBBkC$hU7eHyWt%
zb?i)wzU?C*4Z%yiIu;y>I$MJx4pH;L2T
zYn!3dLu=EqI#FA?wNCa3d=(t6#nJrt>t80T%YrOy2I&3TP(mw5m*k@)Zp>Hku1gWg
zNeG}KpJY8nYc($(k@sO>&0zc;KOuyth9z=@Y?GlTZ+EIfMe?(&Xa+y@2{WSmt6wmx
zB@sOh3f!J!6(NdnLmLH_Ai1-qy~^P0VAjAlj;Bi?wpWRZPwK3==BUQ
zW2h|>BBd=!kVNpp-yA|mqFeJFWHiQAh7h$aE?d3RxpRU#Meq3ItT*Rnr%Csc-_c%-VjcbYE(Eara!
zFtX1gF5S5It4|3ULrsP1wxwz~6<~8=#k%DJjYF*6`P`Y7O);
z5#-Ip=d3B&<3YM2Gre&{AkYO6E%%|Q6U#^ZK5es~D3F#{+F@ASC0YcD;mTOA!!O9`
zuyEw-ae<0TVNq4_OpKI~hTx2xoZDW0fJDH*ki|ng8re6~tr6Ga
zVulNs3BWW4ncdNqBHW$>BU&G%Zu37~gc_@D&sM4ySlGl(zov~j#vVlqAFSWOI=YNj*ML{%->33$7k;S|b6{gm7a8r$
zm(&RY$3-LQakB<;5C<^$iN=Egy;4uFzGRBJyvVg+q|8Q%_B+6Y?t~(Li9bvpjALLg
zO(jK4x|i*$oX|J@N(x27mLc9;;{mzUUzc*LA1n8(DL>{_k+xYP@njA;{DAAjT;w=u
zZCy%zRK^krMqyeSK6Q_!Rz^VRWnlk)7SS?L6uar}yoF`8NIOD)9C`blZ@R+iCA
zBJ(k=C#W``>z8t?Yl&+4Av5gEx*TYt)g=-3RPpg7Rd3TUD5#k}N2s`yj9W0{(l1T&
z%OE5y$f0LU@6%=-N>^x)X`@_ZsAOpJE=_!`h_Jr1M#w^i_YTIVvQ%N|V7@l*eCm7f9lWh|zXO@YAp*2L-pH6~v
zfsPrdRAM%vMnGnqb3&|FLK)3DoAHOk_$v~1$D
zYy0NB)`@#6QKm;;bDGHvB_97mv`o%grb2$(vmL$&?Eb3!$K|n$G%HV;Lp2rc7iHc0
zJwd-(UCC}gh6oHqQGQe_F8>k+IN+IIQqC=2v=a*h6(-wC23J`DT~Ok&USJJ^qsB_#
z4T!~zr{Wt$BtfsGImH@RK0WvOF+ahHs9M<=I`KcP>D@K&$0&sDKKJZ5zBt-vTJbXn
z60V)O8kEg9sc$ZL;>mzaq-c^6i*K>CrT(k#t2L{`|4U)1o0itS$<+HVsYDPCT4q4EP8;
zZdeq`iUI%BN_(w)n#c2=;l?dcE
zm}`9o@n#&rv6e2?5hN}XQPJb=EoGe7wvK6h27=7BEf}?=6lO4_CUn8&L6Zxfe%b6H
z!peK(C1XXoZ$Tc3eRT4VLp(I8mX9
z1rba>W4fkbRP;1ZTDm;~secjZtU;@6j-Ekl{x?yQdZxf?p)WWiy}ys2F`978(h@Ff
z>6BM0DA$DSck>h@z^Ru=^%HxFC5&ICf9S2&A4Q4U@YVWXGQIGs7xk%OxtHN9+>VR7
zcdwXc%Q@x~4rcak$?Ydz()MPH`{Bn@34zVwVdD@!m?qo7QvZGmlXPO|6e2<6RyD
z5*lFz$;0lJ^c3cSAV#eipSWMGDi0^Cc)I3>&>i-=0r)2c%cL3v|Az9(*g16al5
z9ByG?$>Js5Zax({MVypr9J0eJ&J|lyVg!!zt|7k5Gi~lu!@}4tdnNx<pt#T+c$g)
zQ9U9Hg~6I!WG2OS6rCOETS^$6Gs$kD+~;CZPF3=I!fW>JN+z#j{2YZ3OFii~^2~5V
zb-L=<*M9mZ#kIvTF3ZZ26Ys@5%2UFlG(cf{t>malqCH}r^#jk
z)oDHkKv3d8)R5i-HIz5k+97{vFL2LovfH-6x#E6x&HS_N7l7vO%gAg)L&CQSv+79!
zmeMV4m+C9BI$7WQ!P=t|uU5QOjmWQJqL1XzSBE#$3vd?BJN)Q*sZC4NfXyM0nBYmd
zdB0i8dBo{}so9Q~O8C?d-Ugh7+?sFCN@jUV(Tj5tFeulmNnW}!Z!Jfn#v6b|6Vw%r
zUor{U)=g;S(Kj)9j8q1EIzl7ZX>p?;NFu8k$x5u6_G>*2t=Qzhm1T*qwA1Jkou)gx
zm{THWwvS&2dlm?_KQMOYI=ZaAY9v#lUh6Y^GFucq5tVvutsB7$CA?(>v|MXfOhGaS
zeSCQyeaEb9gqhjo=5&0|#|Scu&@HKi?2TQs6m91!;-?eIlv;LVbK`geF}*Yocr%}t
zExoZT3Ggq*;r#pd+;&qOcva2bu7Q~Ig+hJoCxOK*t79h5%{Y!~)bG}IOG^}zllBG+
z#8beaprqCAAHvrgZ{b&i&sZ$Y8=DG3Mgl5v!}ttZ^PEYu+;7NfQ@yIJBk7Sm=NghS
zsjl_)lgNyp<4D)@h+Hq7gqjafA+g@zM#15}?KS14%GutC-?iVw(v_g~GFE2~A2|E)
zd49AHO_l@Wm4nIxJN-F5^ThlIz`A|cIduS02a}ZTc!?3NY*!Sdb36hQGM;f
zCRZV=ZBSWW&FvSwZLakWF2wAb{5MuUgjvPOI*?-)B!Ma}+fe8HPAnjhwXad*2A1h6
z7NvI*aI3H^Zp|uTQ2kLO>zI+#f1L4-eHkOti
z6zi%A8!ylUB&;qZWQOP2ho6hMHGF&brD@Cs75z+@kW52VI`30U?FLY1CQZT>RYX`$
zx+y*BMIW#Zx>*ll-zSQcF@)>X@q?IVh=+@GP6gTR^0~Xg@p(Dkr_K2h
z68TB@u#d{yqpIu>21|Tr0AqSr#+c5^_o57#3merYE6dB1eg|>D{O0EoElwW-*S>SP
zz-uc>B-I=^zSb^v^qRXnR4jy9sH`iebm2k&BqwwHTh{d*piG)CDx^1tt%xuGACIGhPN^!;lQKjVP-=gAMnewAVMp?le
zkLV+}_1W`CWj1cA@(meOk*Pn-;_mC0TydF{_fEr0m+-{~AL~SZ7}S{N7=E#_r$@vQ
z5Vst>-81$Wm|~FE6O5xrvF@&q&Vlk9^&>lF7x+7g=QlZ~Q<@BMEAHNk31UaRAUT#b
zgy%nh=+A**xM4jUvFwOgEam)TLwI?jyw4v=1rS50FNIG0H3M?_;e5q0V@i!kJF(-|L@EQaVo`NV
zQ!%>~=i&|6){~`d*0%J!PjcH0$@5;#aJ-Es)$^p>p+cFGdeWRTYqK#m_g3y*^>ML1
zymFLIv86HZcQ2;dq}V|Tlr_ZINfQGna`Bl1)P+SwH}R{|ScZ<8WysM`p95oQ$^BZuiPC9yUQ)AwT&eEt?<_aHSyP{0b8|na-G+Y?j9sq?=@J)5
zriU#-dQ@2r7TfW96x^Vr$nj-Aby2t9B8+O@i186)-6(s>vgT$x^pY0MjoYKDa>cL0
z>}&gGWuW18SHe#`BOZy2<^=XuSE=bw_JiN)64_@{Vlv#`7?kn;##?n*Sx4+KsirG$
zxLNUvSn}K76lIsbJc0izO6z4g;>IyxYPvmMK43`1o9dw5`Q%4KO)mgam
zHcJvo>A9tIG}G+2Q&aeC&&=@h(I#TH!MD$=OT!>a-dfcQ2<44#dJ3hv8p$#CxTvjD
z;1!ZV(025>49EztgqK7dEF-?npJ
zA}g(pZI*)nti#n!>1yx-cCh7n7lV0exYE3mO?nskdJrUQlRpLH;VAp^QN$%gnG+?u
zZ7*M(89(*nT1b)Zksi&F7Y#v?Fz-L#GvWO_u3QOvqOhR0LBSNzrNo}D3E2e?5
zAPT7tq`g6xie54uoRwcDg+7DqW5`O`@p%pN%U=Meo{3s4tdQ^M`yZ(q&;zqRyP@&q
z6W9Sk2a7hjQXCa>mn^laVM-aFU3jNtvN^CnE!jX+74mAh5uiX?v9Zo(?i)JZ$uMh4
zyzG}GCff@aXRbvnvK*`!sStMl2XyIkUk_A0F=UkuPz~)~m;QI9aM^n?=R|yvvWoA#
zfZd>WR8cnDMKyps1@TbLW}d2OlK5REvTZFZRP7f(ua1{rmK~$$%j(t`&XaABB`(Lb
zGGrF3Ugth_+Lc@&UZ?LZYtn+wVhDJUe?xy#OYf~q=<=*dBH+G3z%TO%`3^c8w__84
zk$lT=zzz3B?f!4k?_D}t0gh>9ZCkx&4{C0OyU$afAvwlGJWnco^N@NwQqX8RZQ7rk
zeGo28&E++YL!-|^Y|6(sWPwxzmeN-xDiZJ!QIvG(3`Su=&yp{ySJn#eEZ#G2($#E7
z*tL^|3bWL=$x-?$xI-mmRa5Buo;kHaNPYO(xG_QC^{4b?3K8O(n0hZQeoBQzG2~Xp
z^_Z;6IZS0Zh#6qEd@8mZQ7pokX~oX>MCYpqRU=SMli5pk8^hrszz1z*(kN&=qIrKt
z_MXd@%-~>w#$}Ke8B4RiwYD^omU>bu;COpOKv8qo0jwKg
zQrsj|bJ2xj&+91CPN|7Ox?Y?(3n(E@Bm_U|4-bmI$qDZL(dp_@_qzk}7J&+z`->RL
z%350U3Q~P++%eyobEu?(b`>ahOHg!p{9v9n6o2f{(~PLEQ~u;vjH{^Wj7eJvkA^ON
zuyizDcQHFJA@Ke4@wCEt?V^H~6yN;cDx%5f9F(SxfpI$*L#
z0rgRNFG?M9-hrRs8+rcV*Y)=4(BZy7n?Lc4bp@vhOsrSDE|9^}fD3u0NPwoy}iO)6}sC?6q
zw35`>oDrrXwC^98o{O<4$_x&7vK9(~l5@nPhB4>z*kx0jNerY(gJ4{Dv2-{QUnSI~
zAEe&@on#RM|SZ!gsVN$1KO;71+K@fFw1LhlWb4
zOOujH4w*r&a$0NSHCfAGKANM&H{v~x@r2k=3^-*X=MWBswGI)>0Sovc((t0U#2lN2
zHrW7e>NEt|VssN)B~AOhbS5Ihn3&g8i$H@(1{V6m9sftA^6#-R;I~P$^3A%#vulTk
zj)TE`sh04XQ=4a7z+$IPXc4?v!O@Uwzo@@DATVuL`S*#hv5LLs{GEM*A|3^D?pL=K
z>d;K{D3E(-Djb9=E5NIhj_)P@Udeh^|4_o&z39><)b8wJT12L9>(&+>gUfG;$xiBwV5S0J%*^5#8!D*19-l!qDB36
z%iUqZa%kiTbJW89ZzW*Y?CbhJO2DEACE#Q4#l>a(U)g9Q^prfxMq{BJd(2&YM8bVa
zO5@**$w5#25BX3e+eg-0MH0m+$wg
z<{Y%I+&mf{Y8W1ujW#M&sFUJBI_d2TPqdm=B=2%B-li9M&_}U|_;px1_fbCwxzm&0GZ6;8U
z5V1J4n3kb*7qa60B_G*COqABNe3iQ_wf!d^Uc3JS$fJZ$y_`?5)hq3gb4GjLY_VDh
z{oUvPXMl3`hQ%fMWBDj_hu-2v56@th(#*fqkO4c>d>7(IkZ8|mpFk|tL6e0vKRh3W
z9;I{t>fg81Lf3!`P|7e^3QItla
z6TcRNs;nPWd!;R-OaEjjZxbWBw!H1*h?1mxlAla{m26?&K}nW$AF7Q$HHt%2K43G(
zE`Djg#FnPa?2t~e0s8rRVE;f-S#*d~ky#yAXzl`_k(IrEbN#&e5_75X1?$RnTSo3^
zU5U74Lf-L7im=ocJN{0A*Vb%$=53;!yw84EoL+Cltvfg%T^oM#B`=E~?%?BVdhWr;
zy1+!6xboaYUpP!*{GmlY3K_zavC)FcqX{(?zf)R+J=n*ioKFck>>Cd`jr)9cHNEx8
zVVVg_GiQ>(Fo^mRu~o^OImLJ;*^Kh=u7fd!yP^E&C#fRRTa36Ry9x?h1#jy-R_^^C
zK4|Ot_jW{%n&js?HbN#0!xotx7S!w%@o5(K2LDfi=SW`TxcK?#|6Sna(ib?sr~u=t@YEdN~=PWFK+NJ=7zbC${CKU`XUb$)9Zx9tUW%QDno
zgq|IF!ZxJJCtB{}53he{(ibi@!`)iAL2%^#{CswtIjQ^qXFKKeM)`+nTDj1Ab5i8dp
zeNB(TJ|MJ386YjNeGh!-HYKmrIJIwVZ2l(b?h77|sx8|P9{~rEu)`u#6;hdfbKfEAPcnc~@5*3Xh
zI-o%f!vP&-^0uO&W?6<3P8?J;13(vce*(_x)nrmeFGw@aA^G!Sc6m+!V-8-VaL&7j
z>tfpKD_cJFCSgJJr7(#c`%sIKl-`+0sR`~@GSt!|NE-zSgp4u+E8N=KO{z(iV0;yE|bEhPPfoqQUL0-yG4QZjPj{Qd6K;Vu1R4M~N1mgo?<&yjBe_28O
z?U}S5Pw@MzzDwPR(;>-=Ba{38t0rEGLsQGn9pYbO(>GZU;F6rlL`eS2oVEa^GKlmo
zD-VKXYvvoe3)6eU=;{(GX-fZmY8j50^!0MQqdT)N#x7ry+v@pee3uI#N#Ka9_^2da
z6tCk2WEttPOgHbRGUibJE-6~no%#A{eY~CN%lSRFB}VncyU46h%~Wp?6;pnM0l}H6
z7?gX>w^lTKW-u~MY){MQ?m&bl8&IdvT+UnDY(7NnJg9ls%7Rr~W$F##JnxN`P3AID
zoG9j;e*GTspHYuL*SmgjyCSXvA{YRPQvt?F(?g_(j1zL2My5OwvvcGC$!UyApOpq~
z`N2Xg<+)7Edm6j@3O@^J8DP0e&w#=Pf)int{=VIoMIU0Rd{ieX0zq=#DSb-8Qa1=V
zD$?{g&Z)IYw0!;K!08-0*j&Lvj6%JRU8y1bv#w0N5nzTriF$(x49B>0gnAqf2F#S^TEE9*Fnua=H2reeJ7K-PK$(d
zTr7?0MR7Rt7T^l6w8~si7PDUI3+#lPy%19m4{6#yyNdCL!>1OPmfM_W%
z*p=EpJx#d@bc9YCMXW-tY5RVf-e>A;3vIl-MA_kh!kldd>UkOa~;F20_M0jAw8+KG{2utY9!Dh1iG)w?~{ke}4LME`iRQTs8
zUJ4gCKrAX|fqB^8>!szx1~l}FAX=?X7obKEark2Mn>%CED|!WjU>!#8ZQeH0nukrb
zRXGItIX|L#Zn&tbk4~VM5sKj~%mqU2c^G+Cb06V`%kRwq?uN@}!)bDHgxRUgVtSNF
zlttzuwi~$K$SqU1$4TcWEMFA2o}&BlWbth{5He5=
z@UyU~n;wIBOJE9#20MOM+XTT<0Vr8L(JK0sxKN$cD#w&JaI(w_RFl>j`OnBX4yk$@XVwRi|*
zT*$!qb2Tu%@X;5o3<nlZmf2
zgK@+da;VTV=m7AM!p5zQo@;lR}gg(Gx58X&*Tw~
zB)9PphWd@M%4pKPS(i%#YsIILn<@10As6M;NJr;vTw&S4$xX8=ZqmWu1*T$X7lVfk
zs>$%$(79NplvHB<0>wWFc9LC3fLF2SwBu?DEtnMPB;_V(iwN+X(UcQD1im`+5rR4_
z=EI7ZZ00|$tnwXlO~@lb&sfXn8n5BWDS;1!Q`ki2SbV?oFMcg=@GWm?Yi5XWrfb_!
zce($PCAQAD!7<-ofaw@9vM2l(&!ZB)3Vc&TE|Q_DHy50~k(1Q5j>CtVt$g&<(e-6V
zpgJLw-vl866MeOmUhj|uKVK%!sZP9=e&P#nh|X$mO$VfeDNg=Oz08r3u7g0Y*go@a
zY-CK{wlYJiPRuGl5dk=3#}$~{9Z2bik;M=l6Uq&B>5u_}Y_G7;S&@M!sKDTEjv~i$
zYS`RX)UcnCTnDz4tThOBYOK(y
z-ha)9dpv{A{@U+wj0ks6Enb!yOMasIn*Q0Z_T!fB}>(!U)pO|-0n@#LY
zk9pi~d`#nyosv*GIE<}&6>8Gs87S$<@dnpN@Z%V@hEkIKngsNni)!k4^&a7rsy{4{
z3@CbVWcfRjW!^-Kj^lB1b*9PWV8LRkSahz3+h)&!k%}NwAsz>?ah>2UTO4*xN{rzM
z_CgF(S|2<5$sekLJr2iphYY!dNHK2sGcDzS=uu6E8so_b1tPCi1o-J5C4boXb^fjc9
zlJ`bJSY*mVEH{C|2@Oc9RDOtW^~p?3Y+qQKcC*_eOL)e?|6`6ZJzds%QTX!`*#JDg
zl$dL97e-@=l!#)HEM%>)nA-64O&reZiOa)a8sXh*puL4s_JRUtMG;2*xIrUsjzsGTh
zH6Iw2?{du6w7#-9t)>Z98)-sM$Gb007=scEdQr=r==6|0>yptZ1uBi(LSW3y>U-Gmw|)GMjzzJB>8Wm-JKuOsBO7@_h0RA}*Re3-9C(-)QCoRP1K3y-$ZNz(m
z79yXpVjd||csgIN6@5Fm^Nhp!buPYPb(cF0&J^KbFw^BwN;7O}Lz1=iN
za5`JH2=lY-MfB+aVEWlqZiGSr87zVZx!W@*dIB{X0Y7xJD(4jDw0@+B!E!MZ1HP#}
z!%0q>=$!S*a3tsQ@-Ju6CC^s0_k#CsVF@~yoUhfHVIB9E5Z1>R=7
zLZ}VXXAO>(lQL^)pvltLXmQ@jlGgA&DNcNl;j6XOw00@i)?HV#EL$#Cmx7xtMyl9C
z!RJ*kyP-tNjy8F)NK{M7>4th_E*XEV_3(8w7ty8Ba=!R4fZB@%PP9a*(G#{>WJ_s}
zYM-^Yw`kW)TRo#Ex65=m)RWZVZ^E=pmi0g2cuJpN2k-P{hrE(9&T^amtOhK3iZU4
zm&&gA??|COr%lWs6y@DnC*IG3=WE^*LLClDKHw_zNWY@{t|I(Kb20R^e^r*WGaYdZ
zE-E5nP3$4S){&jlVL3T5)BodvQT|p#Ande2o7M*B73Zq6o$q
zrh$2hn`a5&So>(pf&3|>*Vv;esP`z3A`Gb6R^5aDS)0?wKW1A{sYU(_6ar*klvI;S
z&x>6sA@<6PTuAj-lNp_gA}Z2bST!hI)V^IHu&Fs(P?y%Nd61Svi&)A!l!reriR#Me
z)0_EzTGR`PB8P(F9xEhh?iI(AS-${9#7D$WWRB;ekcuQ$W(~hQAbyz!2l`8Rt;tOm
zJ(YYte1DTO=ag=*>hN?tYZH%<>`;QnVkgK@ZDho~dRX0G{*`DbNt&&P4rTcV6)6NV
zQgz09--T)Q>TN54DGiZy)Pp*YJ=Z10~o^EoULq0tm8@rj=}b}
zFJKld#_DJ)Q~<=!-yyLbPe~~K4B*KU=7sQg+oAxBqX7oTB+ZO*fBJw|K8vN47Qm2#
zH3H(V`CZRoA9P|yg1bB3)Bl6Kw+@S{efLL)?jDftF6mNg
z=o*HG0Tob$K|op*32Bh-&SB{85Gg4YX=$Y;MMO{#{jI_G{chg9_jjLtopY}1{Biza
zU|8!}@jUB()^p#V;CMwuEJaS^Ch^mJ!bA3c&{ygxcdcMb^PUsRcH2qk=-TGOz=HYm
z1iDDQO@%QyqC>3-H4~zyL`2J<1%W%0M_4pPN|?;O0Jcio$P8tCM^b=?A>dfj$6$gXFeu1)^{5q=jDn4e-h%sZzRqj
zx0GOb^fW_?ftfFlXZPeN(DD~01p|J{P${qy>fBe!n!4IJP7cGyq2Lnke2@HCz~N$1-7hB
z3F=c9*YsxKgDcaTi9Y|%Au!INkY8d+$ZDh48#U6q;DGa2Xn(KRD)6@UC5FUn5|PBz
zcuImnjDNgt`bmkTQEw7#7p6BWIPE@T1G1QPS_QV9H=AeU>uHt0Z?kf-alk+hw@*~R
z;Hb=T944%!erdU0YaA2ymoVo1e-+034FZ%gr~JYmo%u`JFO1K+FG=B@^UpOmoqad*
zvy~1dPDE?29{y+1)vJ;px4Q@Lhn^Y(0)a>8|I)Frt^ZSWaRwB^ialoUEDbv^r0+|*
z1Nm|~p$;NIsO6;Pv|jg{r*7))rls-XCzrJyZ$w81?e6>sW;r8ovq$dA^O^f)3r0(A
zY)+L2+g9FNS2Ds^2%ULdIXs!F{_3=w+!>*dJ4({7TL^+dW;JS#6o_N0MSXdwP!*pOmZlPlClh1g;=Q%e9@>lqQH7&ACwVfC
zWcRn++rBxqC{j$9IV$7Gy13?~r}o(a@DWcyKAmI8sjSoLO({(q1)y#P6wVvyjJ{+e
zWNZueOT9A$HC3J)`4H+Qn!{xG?Yy|0WfH2i*fZ)!oHu7o#|g|OzNH$)$<#In8V;ip
zVUq~CiFmQ{VZqYulX5$h&JoQjcp0~#9>pOwQTvKxuE1}a<>g;R)XVZ#Wok~M|E4Bd
z=W*NWf;$uNh>v*s-;eR&}^sG)!&((EYdIvU>FRCu~lH_kuaivu~
z@objUX0|&2;gOET`?&5+L
zS2&}(>&abZ&TM&VMu`bbtVqsZkL|*8G~c?>4gcH)^rVaEqv#Pl*C?_BZr024zznT4
z{gRtPj+&sgXA&vJD&SJa
zC^*#wj0u(Nz@}QP#kY@w6T$cmA-)I!NIO4X?YiMaLR17bSL0Tha}^ioTA0Mb<1HlU
zBoWah9jFZ^#rp97?F~kDEt)d=jYi>er)-eSK;B8+^XB66q8hOfQeem&JLI@J-jZfK
z665aEPK+TL!6LGlU_)cPd}GO!hR7LGYI!?eh{pFaO+$zl{Qw6$tQdz}l2}j4HCc#f
z&WHx~u4vx1FcdqK;*%_SsNlzh$WkKN5se07guNsY>;&@xPFrr3&l9bY9!oLGq`_D7MGV}c3PICoF^<}>rbn;2{ljS#XdHFy;i}Zt#8L>F$9Tg#7afa)LIJ-`>kuX
z?}cmxIAqu}k3wEfTi&a2FBmpX)qYPmV3HH&IDn`1K*s@)uhv%P`~^w(%Mjw4F{KHP
z#XBf^9V0|&M2Ztqf$6T>5s^4aCz|v46{`R?>}7p8Wu(EKxVR<+U|AUVN3Ia9g%maX
zFCh|3V&!G
z)Ms07?)K6!p5ue&5@(l__0al;4giFbcL_pqzXYLNsgL`g?eyNWL^hjJM0u5d6s5k`
zp%jBJa@MBlDl_**8JxZO1ODCHC?r~IGgh7`_iytHA7Ib*NgE4h8rEjrA*2n
z6fmplGd~+$;L1Fv{iN7e0btL~I*d--`k8Ul8k#yQ6P_$@mom96O8f>H9;~3Alra>s
zKT&CpUC!lqSKqD)tE_+Guu{VQ4>Jq2V3`mwGylpLB)Xu3&MYIyy6
z*W{?!JbTR!W?t)Sf6D|`wtDz3<1J~o97;=KEAnxjt`NB;sJA;7BCOX69@$^|kxKtf
zmt{OlJgrx@t89v=RSWAicABp=y-{C(;c!=S@3GenyE85*R6jDa){CB1g3|MD;#w>^Lk=pU~xA+05pL5C+nuprD;sTQ156_CxpGyRv^KE+gXj?#it8lG9c!
z&L**=B<#YM;R6n8YLNNoOvTyS^xFCkEIpTMYgR%igz|=mxblhF$
z+7?Uu7zNI6`rDrvc~dS#+>!lM${b2UC+HDIGb3Y9ELyYojOA{*Bt(AkzNf
zr^+0gwC`ReM7xqL0EjgIdby8s4ox%M5{P9#qV>-gr8LX;nkrJ>jWX~3L(6cYh~4TDt!sQr
zAi#Ob?e6KBJHYDXdrqBbW*|C!A|x@GxFywXwtM$CHD!4Mr#nGeOuw`fEH)!Is
zacqb`v$`DF;m#6}RX>>eRd(a}MMl-ey~vqUlNFfUS}WpL@!LM#Z-&z9s>k8ZOfPO4
zum1;JP}R940_}*Aa8RzWjgm`k!L>v$6&1PVGP0i>B@;U@I;E!Cw_bFMiiqT&F5qBz
zUKFnJ>1IfSE2TQsNifU=o{#6m(ciFn*yRfKx|QDk{K2ljr5cMpmU0Z=j1zTG+7t>J3cvU-|CXZM+}sCgB0%)BBcciEQtpnEdV#
z*en)CB(g}B=(ao~KMmuGd|0qEay1!aP8Cz63?E|dSZd2fGZ1L
zKtP6+@FaG?$y&P?xKOU%pLBwI7DCo5@+vb68C=I(Z&Fpv|pM_?a?7cAs{{FmTJzncho^Fw^@xV
zbQZS_SF{ChcBONWBhu5{zd9zl(nXld#-OTGr}a0Bg|XeC_Vln(?eIFjg*2sZ1`yKN)m%Fnxu
zEaL|SN1TVVAZj2f+XeD*K>DApCkjlO{2x#-_p}V`pjG94>emh5OMex%c?VFlOqmJ4
zTP-?^+L-%k9AIG8p%@icYV@wGELLXzMH90&Cx@(J=~(ME)oZVv!i|jrm9f_hm|iLq
zsZe~-)|#>?V}6?a^`SiVx72T#9>`3)`#SR8LOy*0{jTzPfZV6y$4)qf}<~P1!eC5Lfq3Y3%49zD^{xS2LSBavR~6!mA4Q6C)G`X9Lp?J
z=C0*3_%nR-3+k--RQ*3JHf|TZKEZiQ%E72&T){zTdr(mKm+
zNT}6qt;U+dh8;}+O1N5Gvk+ajEY^aur_rrWYT+N3F#53KGncNV(P*%dt
z&+c>?x!FIxq9XdLgwzn-6sdQG<;clJks3Y{JKFO6ePo)Y