diff --git a/.gitignore b/.gitignore
index 49c61fc..ba3f1ee 100644
--- a/.gitignore
+++ b/.gitignore
@@ -61,3 +61,6 @@ target/
# vim
*.sw*
+
+# jetbrains
+.idea
\ No newline at end of file
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000..bb3ec5f
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1 @@
+include README.md
diff --git a/README.md b/README.md
index 39742ac..c7c86ca 100644
--- a/README.md
+++ b/README.md
@@ -1,16 +1,13 @@
-========
+# FairML: Auditing Black-Box Predictive Models
+
+FairML is a python toolbox auditing the machine learning models for bias.
[](https://travis-ci.org/adebayoj/fairml/)
[](https://coveralls.io/github/adebayoj/fairml?branch=master)
[](https://raw.githubusercontent.com/adebayoj/fairml/master/LICENSE)
[](https://github.com/adebayoj/fairml/issues)
-FairML: Auditing Black-Box Predictive Models
-=====================
-FairML is a python toolbox auditing the machine learning models for bias.
-
- -
+
### Description
@@ -20,10 +17,11 @@ employment. Despite societal gains in efficiency and
productivity through deployment of these models, potential
systemic flaws have not been fully addressed, particularly the
potential for unintentional discrimination. This discrimination
-could be on the basis of race, gender, religion, sexual orientation, or other characteristics. This project addresses
-the question: how can an analyst determine the relative
-significance of the inputs to a black-box predictive model in
-order to assess the model’s fairness (or discriminatory extent)?
+could be on the basis of race, gender, religion, sexual orientation,
+or other characteristics. This project addresses the question:
+how can an analyst determine the relative significance of the inputs
+to a black-box predictive model in order to assess the model’s
+fairness (or discriminatory extent)?
We present FairML, an end-to-end toolbox for auditing predictive
models by quantifying the relative significance of the model’s
@@ -37,21 +35,28 @@ difficult to interpret.s of black-box algorithms and corresponding input data.
### Installation
-You can pip install this package, via github - i.e. this repo - using the
-following commands:
+#### Recommended
-pip install https://github.com/adebayoj/fairml/archive/master.zip
+You can install the latest stable version via PyPI:
-or you can clone the repository doing:
+`pip install fairml`
-git clone https://github.com/adebayoj/fairml.git
+#### Bleeding Edge
-sudo python setup.py install
+If you are intested in potentially less stable bleeding edge version, install directly from github:
-### Methodology
+- `pip install https://github.com/adebayoj/fairml/archive/master.zip`
+
+#### Development
+
+If you are a developer and prefer to install via a clone:
+1. `git clone https://github.com/adebayoj/fairml.git`
+2. `sudo python setup.py install`
-
-
+
### Description
@@ -20,10 +17,11 @@ employment. Despite societal gains in efficiency and
productivity through deployment of these models, potential
systemic flaws have not been fully addressed, particularly the
potential for unintentional discrimination. This discrimination
-could be on the basis of race, gender, religion, sexual orientation, or other characteristics. This project addresses
-the question: how can an analyst determine the relative
-significance of the inputs to a black-box predictive model in
-order to assess the model’s fairness (or discriminatory extent)?
+could be on the basis of race, gender, religion, sexual orientation,
+or other characteristics. This project addresses the question:
+how can an analyst determine the relative significance of the inputs
+to a black-box predictive model in order to assess the model’s
+fairness (or discriminatory extent)?
We present FairML, an end-to-end toolbox for auditing predictive
models by quantifying the relative significance of the model’s
@@ -37,21 +35,28 @@ difficult to interpret.s of black-box algorithms and corresponding input data.
### Installation
-You can pip install this package, via github - i.e. this repo - using the
-following commands:
+#### Recommended
-pip install https://github.com/adebayoj/fairml/archive/master.zip
+You can install the latest stable version via PyPI:
-or you can clone the repository doing:
+`pip install fairml`
-git clone https://github.com/adebayoj/fairml.git
+#### Bleeding Edge
-sudo python setup.py install
+If you are intested in potentially less stable bleeding edge version, install directly from github:
-### Methodology
+- `pip install https://github.com/adebayoj/fairml/archive/master.zip`
+
+#### Development
+
+If you are a developer and prefer to install via a clone:
+1. `git clone https://github.com/adebayoj/fairml.git`
+2. `sudo python setup.py install`
- +### Methodology
+
+
### Code Demo
@@ -59,10 +64,8 @@ Now we show how to use the fairml python package to audit
a black-box model.
```python
-"""
-First we import modules for model building and data
-processing.
-"""
+# First we import modules for model building and data processing.
+
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
@@ -78,14 +81,16 @@ audit_model takes:
- number_of_runs : number of iterations to perform
- interactions : flag to enable checking model dependence on interactions.
-audit_model returns an overloaded dictionary where keys are the column names of input pandas dataframe and values are lists containing model dependence on that particular feature. These lists of size number_of_runs.
+audit_model returns an overloaded dictionary where keys are the column names of input pandas dataframe and values are
+ lists containing model dependence on that particular feature. These lists of size number_of_runs.
"""
from fairml import audit_model
from fairml import plot_generic_dependence_dictionary
```
-Above, we provide a quick explanation of the key fairml functionality. Now we move into building an example model that we'd like to audit.
+Above, we provide a quick explanation of the key fairml functionality. Now we move into building an example model that
+we'd like to audit.
```python
# read in the propublica data to be used for our analysis.
@@ -130,12 +135,11 @@ plt.savefig("fairml_ldp.eps", transparent=False, bbox_inches='tight')
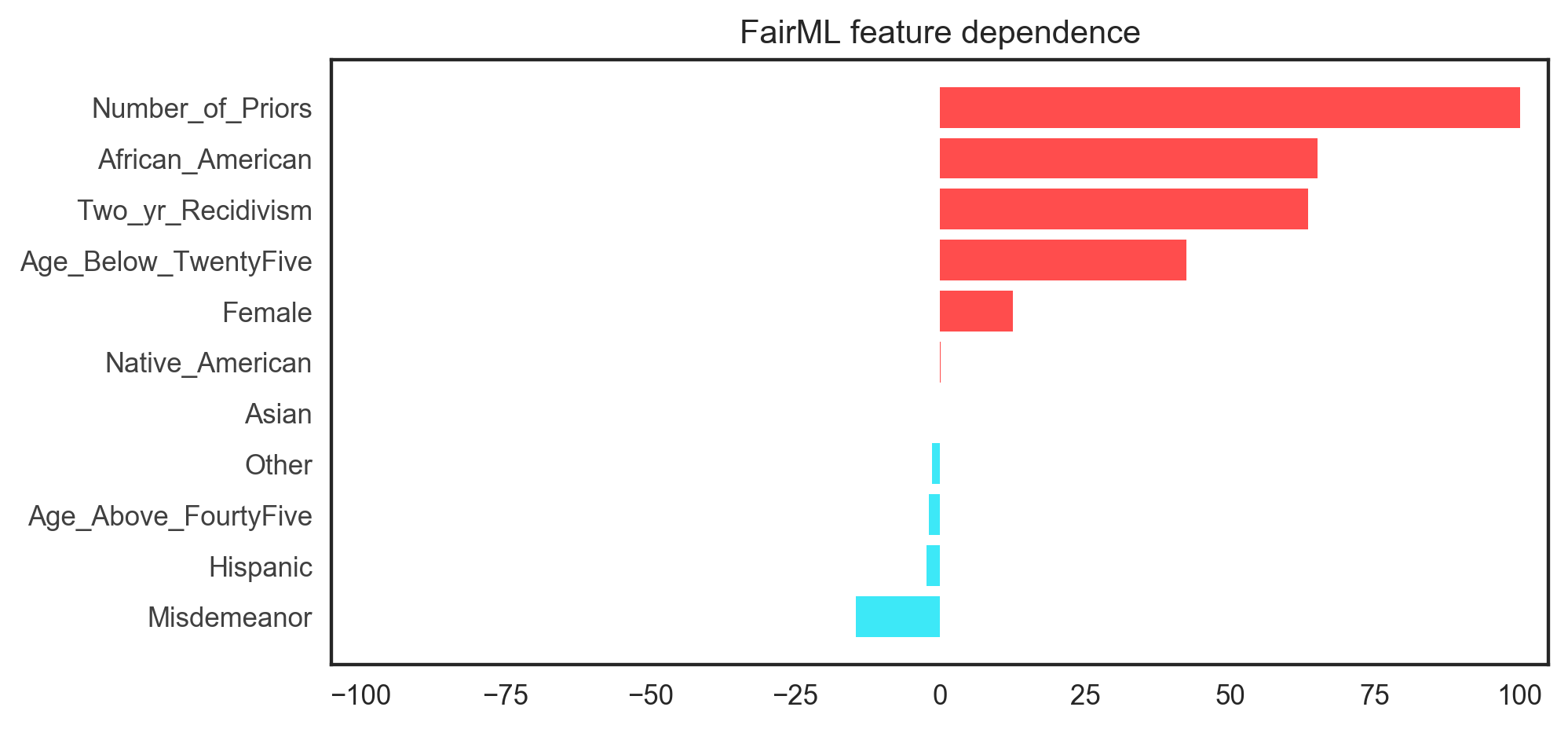
The demo above produces the figure below.
-
+### Methodology
+
+
### Code Demo
@@ -59,10 +64,8 @@ Now we show how to use the fairml python package to audit
a black-box model.
```python
-"""
-First we import modules for model building and data
-processing.
-"""
+# First we import modules for model building and data processing.
+
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
@@ -78,14 +81,16 @@ audit_model takes:
- number_of_runs : number of iterations to perform
- interactions : flag to enable checking model dependence on interactions.
-audit_model returns an overloaded dictionary where keys are the column names of input pandas dataframe and values are lists containing model dependence on that particular feature. These lists of size number_of_runs.
+audit_model returns an overloaded dictionary where keys are the column names of input pandas dataframe and values are
+ lists containing model dependence on that particular feature. These lists of size number_of_runs.
"""
from fairml import audit_model
from fairml import plot_generic_dependence_dictionary
```
-Above, we provide a quick explanation of the key fairml functionality. Now we move into building an example model that we'd like to audit.
+Above, we provide a quick explanation of the key fairml functionality. Now we move into building an example model that
+we'd like to audit.
```python
# read in the propublica data to be used for our analysis.
@@ -130,12 +135,11 @@ plt.savefig("fairml_ldp.eps", transparent=False, bbox_inches='tight')
The demo above produces the figure below.
- +
Feel free to email the authors with any questions:
-[Julius Adebayo](https://github.com/adebayoj) (julius.adebayo@gmail.com)
-
+[Julius Adebayo GitHub](https://github.com/adebayoj) [julius.adebayo@gmail.com](mailto:julius.adebayo@gmail.com)
### Data
diff --git a/doc/images/feature_dependence_plot_fairml_propublica_linear_direct_small.png b/doc/images/feature_dependence_plot_fairml_propublica_linear_direct_small.png
new file mode 100644
index 0000000..65e09fa
Binary files /dev/null and b/doc/images/feature_dependence_plot_fairml_propublica_linear_direct_small.png differ
diff --git a/doc/images/logo2-small.png b/doc/images/logo2-small.png
new file mode 100644
index 0000000..e976946
Binary files /dev/null and b/doc/images/logo2-small.png differ
diff --git a/setup.py b/setup.py
index 7a62b03..3d34549 100644
--- a/setup.py
+++ b/setup.py
@@ -1,10 +1,33 @@
from setuptools import setup
+
+def convert_to_rst(filename):
+ """
+ Nice markdown to .rst hack. PyPI needs .rst.
+
+ Uses pandoc to convert the README.md
+
+ From https://coderwall.com/p/qawuyq/use-markdown-readme-s-in-python-modules
+ """
+ try:
+ import pypandoc
+ long_description = pypandoc.convert(filename, 'rst')
+ long_description = long_description.replace("\r", "")
+ except (ImportError, OSError):
+ print("Pandoc not found. Long_description conversion failure.")
+ import io
+ # pandoc is not installed, fallback to using raw contents
+ with io.open(filename, encoding="utf-8") as f:
+ long_description = f.read()
+
+ return long_description
+
setup(
name='fairml',
- version='0.1.1.5',
+ version='0.1.1.5.rc08',
description=("Module for measuring feature dependence"
" for black-box models"),
+ long_description=convert_to_rst('README.md'),
url='https://github.com/adebayoj/fairml',
author='Julius Adebayo',
author_email='julius.adebayo@gmail.com',
@@ -18,5 +41,15 @@
'seaborn>=0.7.1',
'pandas>=0.19.0'],
include_package_data=True,
- zip_safe=False
+ zip_safe=False,
+ classifiers=[
+ 'Intended Audience :: Science/Research',
+ 'License :: OSI Approved :: MIT License',
+ 'Natural Language :: English',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python',
+ 'Intended Audience :: Developers',
+ 'Topic :: Scientific/Engineering :: Information Analysis',
+ 'Topic :: Software Development :: Libraries :: Python Modules',
+ ],
)
+
Feel free to email the authors with any questions:
-[Julius Adebayo](https://github.com/adebayoj) (julius.adebayo@gmail.com)
-
+[Julius Adebayo GitHub](https://github.com/adebayoj) [julius.adebayo@gmail.com](mailto:julius.adebayo@gmail.com)
### Data
diff --git a/doc/images/feature_dependence_plot_fairml_propublica_linear_direct_small.png b/doc/images/feature_dependence_plot_fairml_propublica_linear_direct_small.png
new file mode 100644
index 0000000..65e09fa
Binary files /dev/null and b/doc/images/feature_dependence_plot_fairml_propublica_linear_direct_small.png differ
diff --git a/doc/images/logo2-small.png b/doc/images/logo2-small.png
new file mode 100644
index 0000000..e976946
Binary files /dev/null and b/doc/images/logo2-small.png differ
diff --git a/setup.py b/setup.py
index 7a62b03..3d34549 100644
--- a/setup.py
+++ b/setup.py
@@ -1,10 +1,33 @@
from setuptools import setup
+
+def convert_to_rst(filename):
+ """
+ Nice markdown to .rst hack. PyPI needs .rst.
+
+ Uses pandoc to convert the README.md
+
+ From https://coderwall.com/p/qawuyq/use-markdown-readme-s-in-python-modules
+ """
+ try:
+ import pypandoc
+ long_description = pypandoc.convert(filename, 'rst')
+ long_description = long_description.replace("\r", "")
+ except (ImportError, OSError):
+ print("Pandoc not found. Long_description conversion failure.")
+ import io
+ # pandoc is not installed, fallback to using raw contents
+ with io.open(filename, encoding="utf-8") as f:
+ long_description = f.read()
+
+ return long_description
+
setup(
name='fairml',
- version='0.1.1.5',
+ version='0.1.1.5.rc08',
description=("Module for measuring feature dependence"
" for black-box models"),
+ long_description=convert_to_rst('README.md'),
url='https://github.com/adebayoj/fairml',
author='Julius Adebayo',
author_email='julius.adebayo@gmail.com',
@@ -18,5 +41,15 @@
'seaborn>=0.7.1',
'pandas>=0.19.0'],
include_package_data=True,
- zip_safe=False
+ zip_safe=False,
+ classifiers=[
+ 'Intended Audience :: Science/Research',
+ 'License :: OSI Approved :: MIT License',
+ 'Natural Language :: English',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python',
+ 'Intended Audience :: Developers',
+ 'Topic :: Scientific/Engineering :: Information Analysis',
+ 'Topic :: Software Development :: Libraries :: Python Modules',
+ ],
)