UPSTREAM PR #22129: Tensor-parallel: Fix delayed AllReduce on Gemma-4 MoE#1361
Open
loci-dev wants to merge 1 commit into
Open
UPSTREAM PR #22129: Tensor-parallel: Fix delayed AllReduce on Gemma-4 MoE#1361loci-dev wants to merge 1 commit into
loci-dev wants to merge 1 commit into
Conversation
Skip forward past nodes that don't consume the current one, and allow a chain of MULs.
|
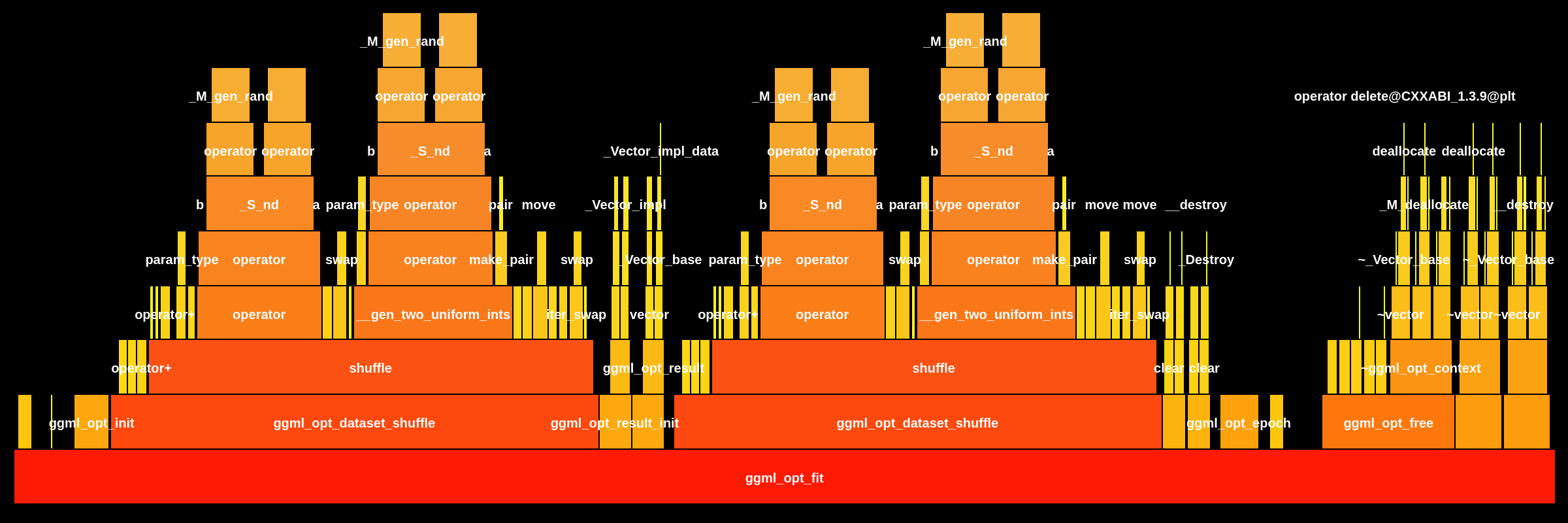
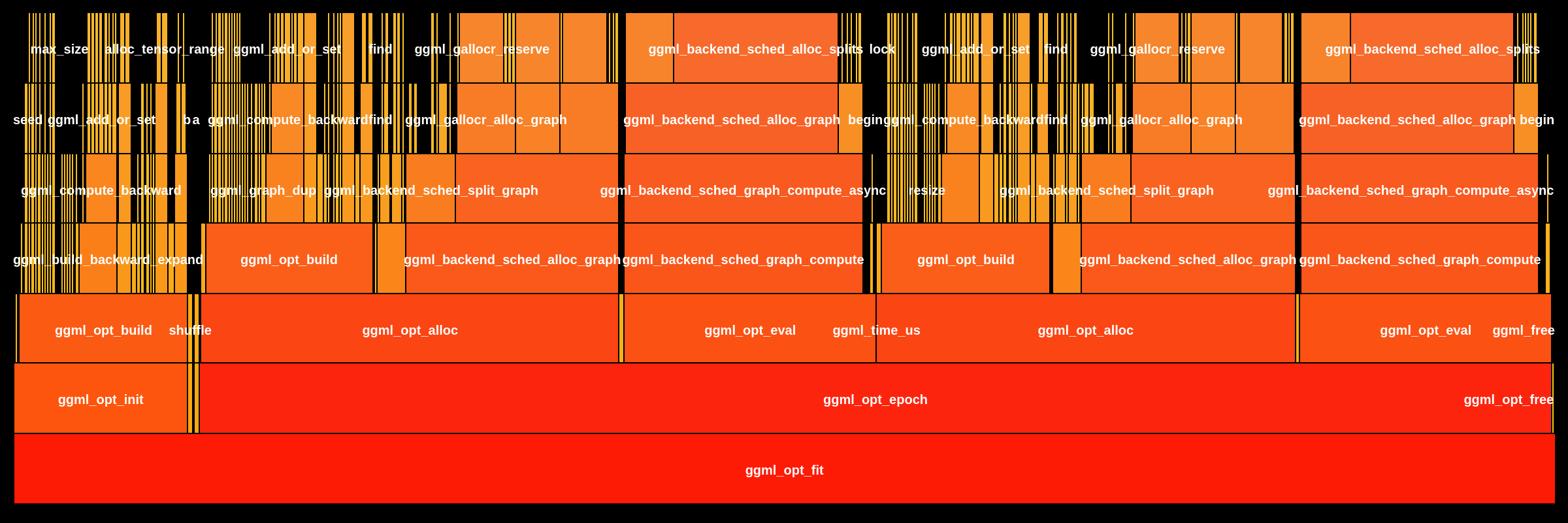
Target version: The base version shows minimal call depth (stub implementation), while the target version reveals the complete training pipeline with deep call stacks through Additional FindingsMulti-GPU MoE Impact: The meta-backend changes improve correctness for distributed tensor-parallel inference. The 142.7 µs local overhead is negligible compared to milliseconds saved per avoided AllReduce operation in multi-GPU Gemma-4/Mixtral deployments. Single-GPU and CPU inference paths are unaffected. 💬 Questions? Tag @loci-dev |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Note
Source pull request: ggml-org/llama.cpp#22129
Skip forward past nodes that don't consume the current node, and allow a chain of MULs.
When
down_exps_sis set, build_moe_ffn pulls the scale tensor in via reshape/repeat/get_rows. Topological sort places those betweenmul_mat_idand the MUL that consumes it, so the existing nodes[id+1] check never sees an ADD_ID or MUL and fails.The scale MUL is followed by a second MUL; the old code only accepted one.
Performance on 2x 5090:
Requirements