This repository was archived by the owner on Oct 31, 2023. It is now read-only.
This repository was archived by the owner on Oct 31, 2023. It is now read-only.
Extremely unstable training on multiple gpus #23
Description
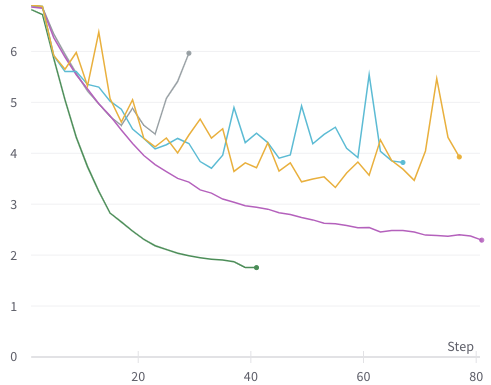
Hi, I'm trying to reproduce the classification training results.
I tried on 2 different machines, machine A with one RTX 3090 and machine B with four A100 gpus.
The training on machine A with a single GPU is fine; see green line (with default parameters).
But on machine B with 4 gpus, it's not training properly and very erratic; see gray, yellow, teal lines (with default and custom parameters).
Purple line is DeiT training on the same machine B (default parameters).
All experiments done with --batch-size=128 (128 samples per gpu).
This is validation loss, other metrics tell the same story, some even worse.
Example of the commands I used:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --use_env main.py \
--model xcit_small_12_p16 --batch-size 128 --drop-path 0.05 --epochs 400
Anyone's seen this or know how to fix it? Many thanks.