A tiered-memory Linux workstation architecture that runs 70B+ parameter LLMs on consumer hardware.
Architecture Spec • Configuration Guides • Benchmarks • Design Principles
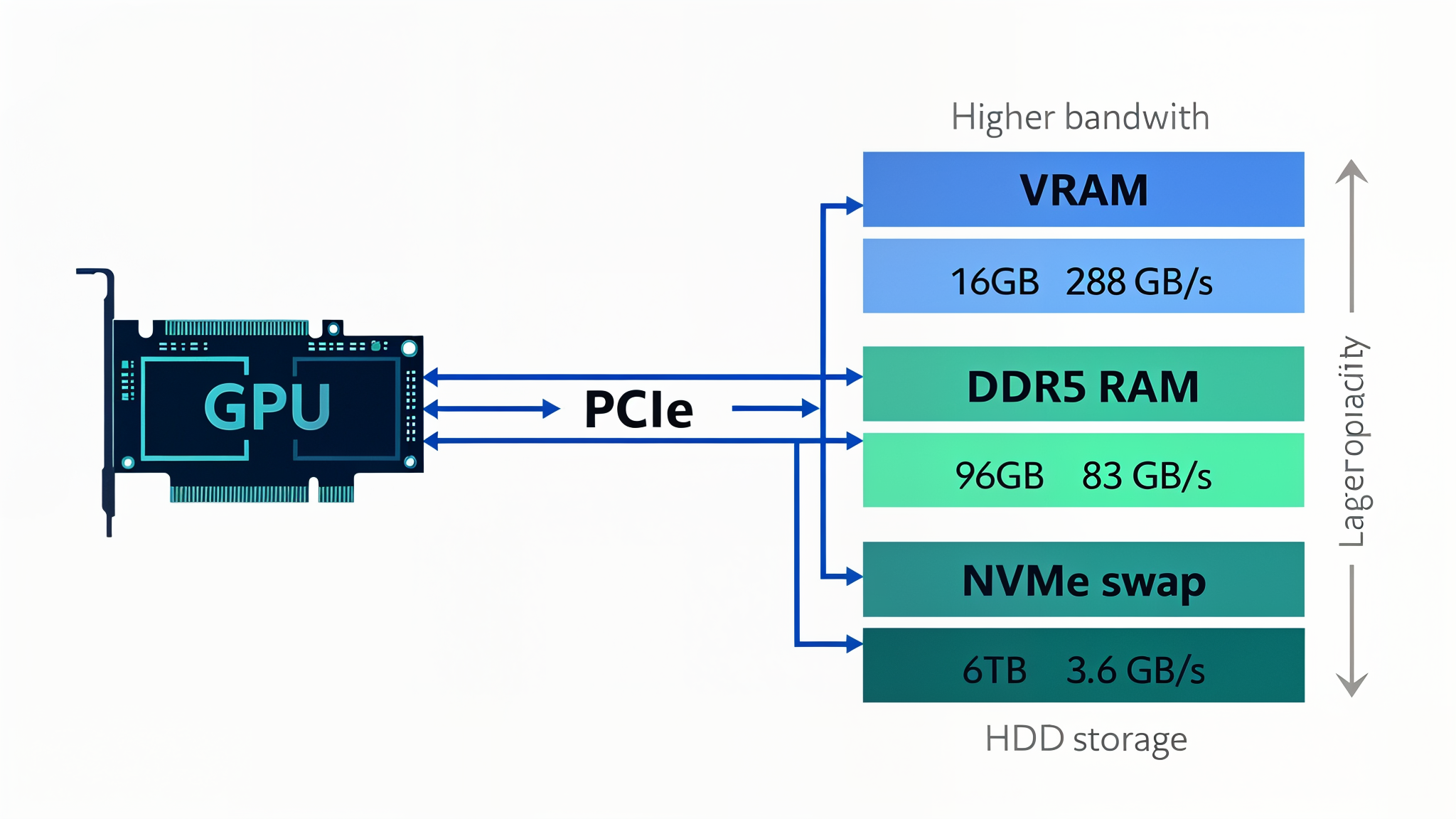
Consumer GPUs have 16 GB of VRAM. A 70B-parameter LLM needs ~40 GB. Rather than buying datacenter hardware, Project Host redesigns the memory hierarchy to treat VRAM, DDR5 RAM, and NVMe swap as a single unified memory fabric.
The result: 70B-parameter models run on an RTX 4060 Ti by transparently overflowing into 96 GB of DDR5 and a tiered NVMe swap fabric.
This repository is the complete architectural blueprint — 1,750 lines of specification, 20+ subsystem guides, and executable validation scripts. It's not a config dump. It's a design reference for building high-performance inference workstations on consumer budgets.
Four tiers with order-of-magnitude bandwidth drops between each. The architecture ensures hot data stays in the fastest tier:
graph TD
subgraph T0 ["T0: VRAM (GDDR6)"]
VRAM["16 GB @ 288 GB/s<br/>Tensor cores, KV cache, hot attention layers"]
end
subgraph T1 ["T1: DDR5 RAM"]
RAM["96 GB @ 83 GB/s<br/>Overflow layers, FFN weights, embeddings"]
end
subgraph T2 ["T2: NVMe Gen4"]
NVME["Active staging @ 3.6 GB/s<br/>Model staging, swap fabric, runtime state"]
end
subgraph T3 ["T3: HDD Archive"]
HDD["Cold archive @ 0.1 GB/s<br/>Full model library, media, development"]
end
VRAM ---|"PCIe x8 Gen4<br/>15.75 GB/s bidirectional"| RAM
RAM ---|"Memory bus"| NVME
NVME ---|"Stage on demand"| HDD
style T0 fill:#51cf66,stroke:#2b8a3e,color:#fff
style T1 fill:#339af0,stroke:#1864ab,color:#fff
style T2 fill:#fab005,stroke:#e67700,color:#000
style T3 fill:#868e96,stroke:#495057,color:#fff
Key insight: Bandwidth drops 3.5x from VRAM to RAM, then 23x from RAM to NVMe, then 36x from NVMe to HDD. Inference performance is dominated by which tier holds the active data.
The core innovation is the GPU L2 cache bridging — CUDA UVM parameters allow the GPU's L2 cache to cache system RAM pages, dramatically reducing effective PCIe latency for repeated tensor access:
graph LR
subgraph GPU ["GPU (RTX 4060 Ti)"]
TC["Tensor Cores<br/>FP8 / FP16 / INT4"]
L2["L2 Cache (48 MB)<br/>cache_sysmem = 1"]
VRAM2["VRAM 16 GB"]
end
subgraph Host ["Host Memory"]
RAM2["DDR5 96 GB<br/>Overflow weights"]
end
subgraph Storage ["Storage"]
NVME2["NVMe Gen4<br/>Model staging"]
end
TC --> L2
L2 -->|"Hit: L2 latency"| VRAM2
L2 -->|"Miss: PCIe DMA"| RAM2
RAM2 -.->|"Page fault → prefetch"| NVME2
style GPU fill:#51cf66,stroke:#2b8a3e,color:#fff
style Host fill:#339af0,stroke:#1864ab,color:#fff
style Storage fill:#fab005,stroke:#e67700,color:#000
When a model overflows VRAM, the GPU doesn't stall — it reads overflow weights from DDR5 through PCIe, and the L2 cache ensures repeated accesses skip the bus entirely. A dedicated prefetch engine speculatively loads sequential weight pages before faults occur.
Three volume groups, each on a different speed tier. No cross-drive spanning — each VG inherits its drive's performance characteristics:
graph TD
subgraph NVMe_Tier ["NVMe Gen4 — 3.6 GB/s"]
SHELL["Shell<br/>Disposable OS root<br/>Reinstallable without data loss"]
GW_SWAP["Swap Fabric<br/>Static + LVM + Dynamic"]
GW_STAGE["Model Staging<br/>Per-backend zones"]
GW_APPS["App Runtime<br/>Containers, caches, state"]
GW_CONF["Identity<br/>Dotfiles, configs, KDE"]
end
subgraph SATA_Fast ["SATA 7200 RPM — 0.15 GB/s"]
DEV["Development<br/>Projects, source code"]
end
subgraph SATA_Slow ["SATA 5400 RPM — 0.1 GB/s"]
MODELS["Model Library<br/>1.5 TB across 18 modalities"]
MEDIA["Media Archive<br/>Personal files"]
VMS["VM Storage"]
end
MODELS -->|"Stage to NVMe<br/>before inference"| GW_STAGE
GW_STAGE -->|"Load into<br/>GPU memory"| SHELL
style NVMe_Tier fill:#fab005,stroke:#e67700,color:#000
style SATA_Fast fill:#339af0,stroke:#1864ab,color:#fff
style SATA_Slow fill:#868e96,stroke:#495057,color:#fff
| Principle | Implementation |
|---|---|
| Disposable OS | Root partition can be wiped and rebuilt. All user data lives on LVM volumes that survive reinstalls. |
| Speed-separated tiers | Each volume group matches its drive's throughput. NVMe for hot data, HDD for cold storage. |
| Models staged, never loaded from HDD | A staging pipeline copies models from HDD archive to NVMe before inference. Cold starts take 14s from NVMe vs 206s from HDD. |
| Signal integrity | Mixed-rank DDR5 placed per daisy-chain topology rules (1R at stubs, 2R at termination) for stable 5200 MT/s. |
| Thermal safety | CPU quota capping, GPU power limits, and core affinity spreading prevent thermal emergencies under sustained inference. |
| Validated configuration | Every documented setting has an executable check in the validation suite. |
Not all model layers are equal. Attention heads are accessed every token and stay in VRAM. FFN layers are larger and overflow to RAM:
| Model | Weights | GPU Layers | RAM Layers | Expected Throughput |
|---|---|---|---|---|
| 7B–13B Q4 | 4–8 GB | All | None | 40–50 tok/s |
| 32B Q4 | ~20 GB | 28 of 48 | 20 of 48 | 5–6 tok/s |
| 70B Q4 | ~40 GB | 30 of 80 | 50 of 80 | 1.5–2 tok/s |
| 120B+ Q4 | 60+ GB | ~14 | 66+ (+ NVMe) | < 1 tok/s |
The PCIe x8 Gen4 link (15.75 GB/s) sets the theoretical floor for overflow models. UVM L2 caching raises actual throughput above this floor for models with repeated access patterns.
graph TD
subgraph CPU_Complex ["CPU"]
CPU["i7-13700F<br/>16C (8P+8E), 24T<br/>5.2 GHz, PL1: 200W"]
end
subgraph Memory ["DDR5 (96 GB, Gear 1, CL40)"]
direction LR
CH_A["Channel A<br/>16GB 1R + 32GB 2R"]
CH_B["Channel B<br/>16GB 1R + 32GB 2R"]
end
subgraph GPU_Sub ["GPU"]
GPU["RTX 4060 Ti 16GB<br/>AD106, SM89, 140W cap<br/>PCIe x8 Gen4, ReBAR"]
end
subgraph Storage ["Storage"]
NVMe["NVMe Gen4 1TB"]
HDD1["SATA 1.82TB 7200RPM"]
HDD2["SATA 3.64TB 5400RPM"]
end
CPU --- CH_A & CH_B
CPU ---|"x8 Gen4"| GPU
CPU ---|"x4 Gen4"| NVMe
CPU ---|"SATA III"| HDD1 & HDD2
style CPU_Complex fill:#e8590c,stroke:#d9480f,color:#fff
style Memory fill:#339af0,stroke:#1864ab,color:#fff
style GPU_Sub fill:#51cf66,stroke:#2b8a3e,color:#fff
style Storage fill:#fab005,stroke:#e67700,color:#000
Design choice: GPU and NVMe are on separate PCIe root ports — they don't share bandwidth. The GPU gets a dedicated x8 Gen4 link (15.75 GB/s), and the NVMe gets x4 Gen4 (3.6 GB/s).
This is a complete architectural reference, not a quick-start guide:
| Document | Coverage |
|---|---|
| System Architecture | 1,750-line master spec: hardware, storage topology, memory hierarchy, boot chain, inference pipeline, systemd orchestration |
| Configuration Reference | 20+ subsystem guides: BIOS, GRUB, GPU, CUDA, kernel memory, huge pages, I/O schedulers, CPU governors, swap fabric, Docker, network, services |
| GPU Direct Memory | UVM cache optimization, prefetch tuning, Resizable BAR, PCIe relaxed ordering |
| GPUDirect Storage & DMA | NVMe-to-GPU DMA bypass, PCIe topology analysis, GeForce compatibility |
| Inference Benchmarks | Layer-split strategies, PCIe bottleneck analysis, cold-start optimization, TensorRT-LLM compiled performance |
| Swap / L3 Fabric | Three-tier NVMe swap architecture with dynamic expansion |
| Diagnostics | 25-point system verification checklist |
Every documented configuration has a corresponding check:
./scripts/master-sweep.sh # Full 111-check system sweep
./scripts/master-sweep.sh --profile inference-only # Dedicated inference profile
./scripts/master-sweep.sh --profile benchmark # Max performance (thermal risk)The sweep validates GPU state, PCIe link, UVM parameters, kernel tunables, NVMe scheduling, storage pressure, CUDA version coherence, and 90+ other checks. Output is color-coded with fix instructions for every failure.
Three operational profiles: workstation (mixed-use, thermal-safe), inference-only (max throughput), benchmark (thermal risk accepted).
This repository is a blueprint, not an installer. To adapt it:
- Study the design — understand why each tier exists, not just what it contains
- Map to your hardware — the principles scale: any modern GPU + sufficient RAM + fast storage
- Implement incrementally — start with the memory fabric (UVM + swap), then add storage tiers
- Validate continuously — adapt the sweep script to your hardware's expected values
- CUDA version mismatch —
nvidia-smireports the driver's maximum capability, NOT the installed toolkit version - Ollama
OLLAMA_NUM_GPU— not a valid environment variable. GPU layer count is per-model, not per-server - systemd CPUQuota —
99%means 99% of ONE core, not total CPU. 16 cores at 98% =1568% - PCIe ASPM — must be disabled in BIOS, not just kernel. Some boards (MSI) override the kernel parameter
docs/
├── architecture.md # Master system specification (v5.0)
├── INFERENCE-CONFIG.md # Validated inference runtime config
├── reference/ # 20+ subsystem configuration guides
│ ├── gpu-direct-memory.md # UVM cache optimization
│ ├── cuda.md # CUDA version management
│ ├── swap.md # L3 swap fabric
│ └── ... # BIOS, GRUB, CPU, I/O, network, etc.
└── guides/
├── inference-benchmarks.md # Performance analysis
├── gds-dma.md # GPUDirect Storage deep dive
└── out-of-core-memory.md # Out-of-core model loading
scripts/
├── master-sweep.sh # 111-check validation suite (v5.0)
├── profiles/
│ ├── workstation.conf # Mixed-use profile (default)
│ ├── inference-only.conf # Dedicated inference
│ └── benchmark.conf # Max performance
└── legacy/ # Archived historical scripts
| Component | Specification |
|---|---|
| CPU | Intel i7-13700F — 16C (8P+8E), 24T, 5.2 GHz |
| RAM | 96 GB DDR5-5200 (4 DIMMs, mixed-rank, Gear 1, CL40) |
| GPU | NVIDIA RTX 4060 Ti 16 GB (AD106, SM89, PCIe x8 Gen4) |
| NVMe | 1 TB Gen4 (model staging, swap fabric, OS root) |
| HDD | 1.82 TB 7200 RPM + 3.64 TB 5400 RPM (development, model library) |
| PSU | 650W (390W peak, 260W headroom) |
The design principles — disposable root, speed-separated tiers, unified memory fabric, validated configuration — apply to any modern hardware with these characteristics: a discrete GPU, sufficient system RAM for overflow, and fast storage for staging.
MIT — free to adapt, modify, and redistribute.