Generate with AI. Verify with CV. Trust the result.
A pipeline that generates a crochet diagram with Gemini (or accepts your own photograph), detects every stitch with a YOLOv8n-OBB model, reconstructs the scheme, and exports structured JSON.
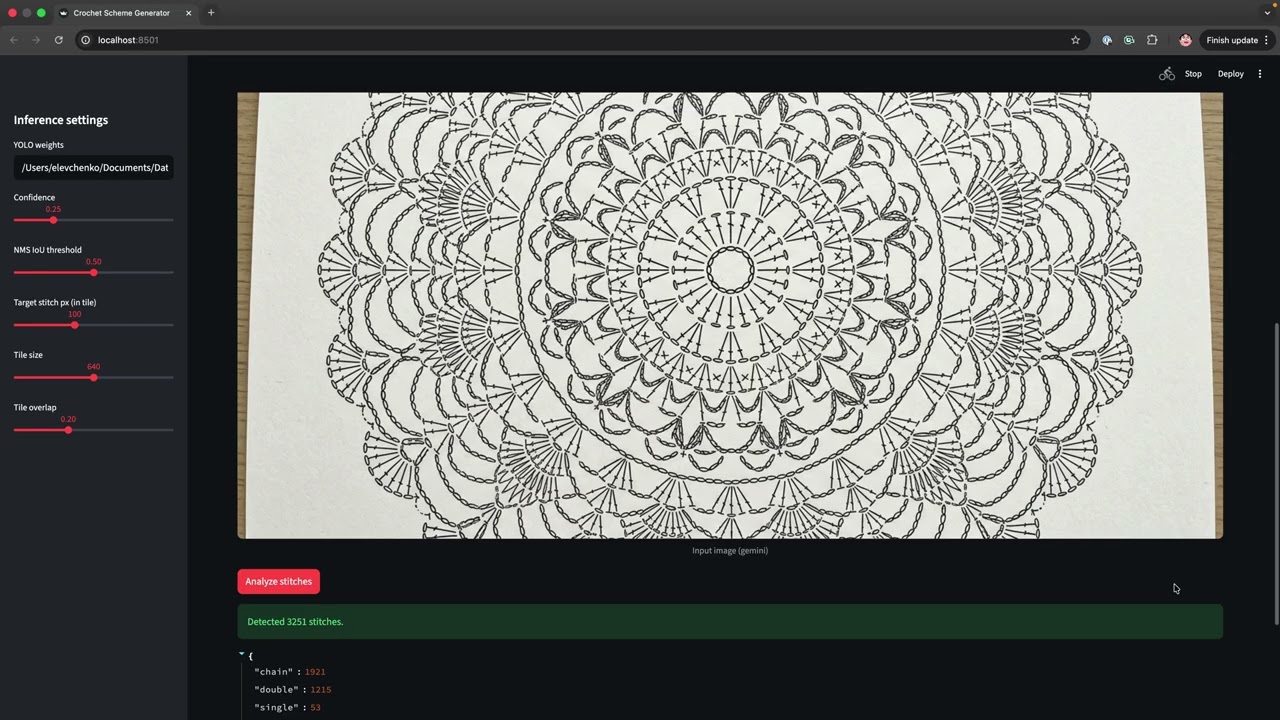
A 1-minute walkthrough of the Streamlit app: pick an example image (or generate one with Gemini), run adaptive tiled inference, and open the "Inspect tiling" panel to see how the photograph is split into tiles and reassembled with class-aware NMS.
Online marketplaces are flooded with AI-generated crochet patterns that have never been tested by an actual crafter. Buyers pay for patterns containing impossible stitch combinations, broken repeat sequences, and nonsensical construction steps. Nobody is checking whether these patterns actually work.
Crochet Studio is a step toward closing that gap: pair generative AI for creating patterns with computer vision for verifying them. The current release performs detection and scheme reconstruction; pattern correctness checking via a directional graph and the CrochetPARADE DSL is the next milestone (see Future work).
This is the final project for the Ironhack Data Science & Machine Learning course, completed over two weeks. The goal — turning a photographed crochet chart into a structured, machine-readable scheme — sits in an awkward niche: there is virtually no public training data for it, and the symbols themselves are rotated, irregularly spaced, and frequently merge into compound sub-patterns.
The closest published work I found is Optical Music Recognition (OMR). The most directly applicable paper is Full-page music symbols recognition: state-of-the-art deep models comparison for handwritten and printed music scores [1], in which Yesilkanat et al. benchmark Faster R-CNN, Cascade R-CNN, DINO, Inception-ResNetV2, HRNet, Swin Transformer and FocalNet on handwritten and printed music scores. OMR is structurally similar to the crochet problem: a dense grid of small, rotated, sometimes overlapping symbols on a noisy paper background. The single biggest difference — and the central challenge of this project — is data: OMR researchers have curated public corpora; for crochet there is essentially nothing.
Two pipelines share most of their machinery:
2D pipeline (the focus of this release): Gemini → image → adaptive tiled YOLOv8n-OBB detection → reconstructed scheme + JSON.
3D amigurumi pipeline (exploratory): Gemini → reference image → Hunyuan3D mesh → horizontal slicing → perimeter-per-row → amigurumi instructions.
A small zero-shot text classifier routes user prompts to the appropriate pipeline.
The detector is YOLOv8n-OBB, fine-tuned via transfer learning on
Google Colab. There are nine stitch classes: chain, single,
double, half_double, treble, double treble, enseble_chain,
fan, and noise (row counters, arrows, paper artefacts).
Crochet stitches are rotated symbols — V-stitches lean inward, fan/shell motifs radiate outward, foundation chains slope. Standard axis-aligned boxes lose all of that information. The OBB head emits four corner points per detection, capturing both position and angle natively, which makes the downstream scheme reconstruction trivial: each stitch's centre, dimensions, and rotation are read straight off the prediction.
The Streamlit app has to feel snappy: Gemini already takes 20 s – 2
min for image generation depending on queue depth, so the detection
step has to disappear into the background. YOLOv8n-OBB at
imgsz=640 runs in ~50 ms per tile on a free Colab GPU and ~300 ms
on Apple MPS — fast enough that adaptive tiled inference on a
1000 × 1500 photograph still finishes in a couple of seconds.
A single 640 × 640 input is too small for full-page chart photographs and too coarse for thumbnail-sized diagrams. The tiler runs in four steps:
- Estimate — a low-confidence YOLO pass on the downsampled image yields the median stitch short-axis length.
- Calculate — derive an "effective" tile size so the median stitch lands at ~100 px (the training scale) inside every tile fed to YOLO.
- Tile & detect — overlapping tiles, per-tile inference, detections translated back into original-image coordinates.
- Merge & NMS — class-aware non-maximum suppression deduplicates the same stitch reported by neighbouring tiles in the seam regions.
The Streamlit app's "Inspect tiling" expander visualises both the split and the post-NMS reassembly so you can see the algorithm work in real time.
There is no public crochet OBB dataset, so the training set was bootstrapped:
- Manual labelling — hand-annotated ~80 real chart photographs in Label Studio with rotated rectangles for the nine classes.
- Initial training — fine-tuned YOLOv8n-OBB on the manual set to get a usable baseline.
- Semi-automatic labelling — used the baseline model to pre-label new photographs, then corrected the predictions in Label Studio. Correcting is roughly 5× faster than annotating from scratch, so each iteration roughly doubled the labelled corpus.
- Synthetic generation — a procedural pipeline emits 640 × 640 charts with YOLO-OBB labels, using PNG templates, per-class procedural drawers, layout generators, and photographic augmentations.
Comparing the same model trained on 79 manual labels only vs. 79 manual + 300 synthetic images:
| Class | Manual only | + Synthetic |
|---|---|---|
| chain | 0.93 P | (stable) |
| double | 0.92 P | (stable) |
| single | 0.94 P | (stable) |
| half_double | 0.69 P | 0.82 P |
| noise | 0.50 P / 0.03 R / ~0 F1 | 0.12 / 0.20 / 0.15 F1 |
(Run-by-run figures live in
notebooks/full_pipeline_YOLO_OBB.ipynb,
Step 2.3.)
The takeaway: synthetic data clearly helps the rare and visually
variable classes (half_double, noise) while leaving the strong
baseline classes alone. It does not yet close the domain gap
entirely — the textures, paper artefacts, and ink variation in real
photographs are not fully captured by the procedural generator — but
it lifts the worst classes far enough out of "broken" territory to
make the model usable on real photos.
A subtler observation from the confusion matrix: treble remains
occasionally confused with background even after the synthetic-data
lift. That kind of nuance builds trust — if every metric just got
uniformly better, I would be suspicious of overfitting.
If you plan to retrain, please use a GPU. Both CPU and Apple MPS are too slow for the 150-epoch run.
Before the deep-learning path, I tried a fully classical pipeline: binarization → denoising → watershed segmentation → MobileNetV2 classifier on the resulting crops. It worked on clean charts but failed reliably on dense or low-quality photographs, where adjacent symbols routinely merge into a single connected component. The hardest cases were shell sub-patterns:
[insert image data/figures/shell1.png] A shell composed of five double-crochet stitches with detached bases.
[insert image data/figures/shell2.png] An equivalent shell composed of two double-crochet stitches whose bases are joined.
These are the same crochet pattern in two valid notations. Watershed segments the first cleanly; on the second, the joined base merges the two stitches into a single component and the classifier never sees individual symbols. A more sophisticated classical pipeline could probably handle this — likely combining stroke-based decomposition with morphological priors specific to each sub-pattern — but the engineering cost climbs sharply with every new pattern variant. An end-to-end deep detector with rotated bounding boxes side-steps the problem entirely: it learns the appearance of each stitch class without first having to segment it.
- Pattern verification via CrochetPARADE DSL. The detected JSON encodes positions and classes; the next step is to build a directional graph of stitch connections so the same scheme can be checked for structural validity (broken repeats, impossible joins, dangling chains).
- Auto-fix broken patterns. Given the directional graph, detect structural errors and suggest repairs.
- Close the synthetic-real domain gap. Better paper textures, ink variation, lighting, and shadow modelling in the generator — possibly diffusion-based augmentation conditioned on real chart photographs.
The same generate-then-verify pattern applies to any domain where AI can produce visual plans and CV can read them back:
- Architecture — AI generates floor plans; CV reads walls, rooms, and dimensions; output is a validated CAD drawing.
- Fashion — AI generates garment sketches; CV extracts pattern pieces and measurements; output is sewing instructions or 3D model code.
- Any craft domain — generative AI creates, computer vision validates structure, and a domain-specific DSL enables proofreading.
For a complete walk-through of the technological stack and the three
main pipeline steps, see
notebooks/full_pipeline_YOLO_OBB.ipynb.
crochet_studio/
├── main.py # CLI entry point (subcommands)
├── app.py # Streamlit entry point
├── README.md
├── requirements.txt
├── data/ # raw photos, templates, synthetic dataset
├── notebooks/
│ └── full_pipeline_YOLO_OBB.ipynb
└── src/ # all pipeline logic
├── config.py # class metadata + default hyperparameters
├── data_generation.py # Step 1: synthetic dataset
├── training.py # Step 2: training + evaluation
├── inference.py # Step 3: adaptive tiled inference
├── rendering.py # overlays + reconstructed scheme
├── label_studio.py # tile + emit tasks.json for Label Studio
├── generation.py # upstream Gemini image generation
└── pipeline.py # end-to-end orchestration
pip install -r requirements.txt
# Step 1 — synthetic dataset
python main.py generate --output-dir data/synthetic
# Step 2 — train
python main.py train --data data/synthetic/data.yaml
# Step 3 — inference on a real image
python main.py infer --image data/raw/easy/0.png \
--weights runs/obb/obb_train/weights/best.pt
# Streamlit app
streamlit run app.py[1] Ali Yesilkanat, Yann Soullard, Bertrand Coüasnon, Nathalie Girard. Full-page music symbols recognition: state-of-the-art deep models comparison for handwritten and printed music scores. Document Analysis Systems (DAS 2024), Athens, Greece, pp. 327–343. ⟨hal-04268139v2⟩