TP9
Noms des auteurs : Nathan Colson, Thomas CISERANE (Shi)
Date de réalisation : 07/05/2025
- Expliquez sur votre Wiki pourquoi l'utilisation de la directive
buildne convient pas dans le contexte Docker Swarm.
Dans un cluster Swarm, les nœuds ne partagent pas le contexte local de construction (le répertoire avec les Dockerfiles). Donc la directive build: ne fonctionnera pas dans un docker stack deploy. Il faut alors construire une image en local avec build puis la push sur un DockerHub pour ensuite remplacer le build par l'image de DockerHub.
Attention j'ai aussi du modifié le port du container (8081) pour qu'il ne soit pas le même sur le web (80).
- Documentez sur votre Wiki les flux de données présents, en vous basant sur un schéma commenté.

- Documentez l'adaptation du service afin de le faire tourner sur Swarm.
Pour adapter le service WoodyToys à Docker Swarm, nous avons remplacé toutes les directives build: dans le fichier docker-compose.yml par des références image: pointant vers les images Docker préalablement construites et poussées sur Docker Hub sous le compte goatuser17.
Cette modification est nécessaire car Docker Swarm ne peut pas construire d’images localement sur les nœuds, il ne peut que tirer des images existantes depuis un registre. Après avoir publié les images (db, api, front, reverse) sur Docker Hub, nous avons modifié le fichier de configuration pour inclure des directives spécifiques à Swarm comme deploy, replicas, restart_policy et placement constraint pour la base de données. Le service a ensuite été déployé avec succès à l’aide de la commande docker stack deploy -c docker-compose.yml woody.
- Documentez vos observation et analyses des limitations, en détaillant les performances chiffrées observées.
Lors des premiers tests avec un seul replica par service, le site était lent. L’API répondait mal si plusieurs requêtes arrivaient en même temps, car elle est limitée à une seule connexion. La base de données avait aussi des blocages à cause de cette même limite.
En lançant wget -r sur le site, le téléchargement complet a pris environ 12,8 secondes. Après avoir augmenté le nombre de replicas à 3 pour l’API et le front, les performances se sont améliorées : le site répondait plus vite et les délais de chargement étaient réduits. Cela montre que le scaling permet de mieux répartir la charge, même si les limitations artificielles restent visibles.
- Documentez votre campagne de mesure
La campagne de mesure a été réalisée à l’aide de la commande time wget -r http://www.l1-7.ephec-ti.be:8081, lancée depuis un poste client externe. Nous avons effectué cette commande dans différentes configurations : avec 1 seul replica pour chaque service dans un premier temps, puis avec 3 replicas pour api et front. Pour chaque configuration, nous avons relevé le temps total d’exécution, le nombre de fichiers récupérés et la taille totale téléchargée.
FINISHED --2025-05-11 07:39:39--
Total wall clock time: 16s
Downloaded: 2 files, 4.8M in 16s (307 KB/s)
real 0m16.098s
user 0m0.010s
sys 0m0.030s
- Est-ce que l'augmentation du nombre de replicas résout les problèmes ? Répondez en comparant les premiers chiffres de performance observés avec des mesures effectuées après la modification. Pour chacune des trois limitations, commentez les éventuelles améliorations en étant critiques (les limitations artificielles ne sont peut-être pas représentatives de la réalité).
- Est-ce qu'il y des choses que vous pouvez mettre en place au niveau de Docker Swarm (outre les réplicas) pour améliorer les performances ? (Hints:
healthchecks(pour l'api) etplacement constraint(pour la database))
- Documentez la mise en place du service Redis
Tout d'abord dans le docker-compose.yaml nous avons rajouter le service redis qui servira de cache :
redis:
image: redis:8
deploy:
replicas: 1Pour un usage basique de Redis nous utilisons l'image officielle directement et non une image personalisée.
Ensuite nous avous modifié le backend api/main.py pour la mise en place du Cache Aside, notamment pour les routes API suivantes :
@app.route('/api/misc/heavy', methods=['GET'])
def get_heavy():
# TODO TP9: cache ?
name = request.args.get('name')
cache_key = f'heavy:{name}'
cached_value = redis_db.get(cache_key)
if cached_value:
return f'cache: {datetime.now()} - {cached_value}'
# Cache Miss
r = woody.make_some_heavy_computation(name)
redis_db.setex(cache_key, 120, r)
# on rajoute la date pour pas que le resultat ne soit mis en cache par le browser
return f'db: {datetime.now()}: {r}'
...
@app.route('/api/products/last', methods=['GET'])
def get_last_product():
# TODO TP9: put in cache ? cache duration ?
cache_key = 'last_product'
cached_value = redis_db.get(cache_key)
if cached_value:
return f'cache: {datetime.now()} - {cached_value}'
# Cache miss
last_product = woody.get_last_product() # note: it's a very slow db query
redis_db.setex(cache_key, 120, last_product)
return f'db: {datetime.now()} - {last_product}'Pour éviter les .decode() pour chaque valeur de cache récupérée, redis_db est devenu
redis_db = redis.Redis(host='redis', port=6379, db=0, decode_responses=True)Où decode_responses=True le fait automatiquement. Puis nous avons reconstruit l'image, poussé sur Docker Hub et mise à jour le service. Nous aurions pu utiliser docker service update --image goatuser17/woody-api:latest woody_api pour mettre à jour le service woody_api mais nous avons réutilisé la commande docker stack deploy -c docker-compose.yml woody qui remet à jour tous les services en cours.
- Documentez les mesures de performances obtenues après cette modification.
Nous avons mesuré le temps d'accès à l'endpoint /api/misc/heavy?name=toto avec la commande :
time wget -qO- "http://www.l1-7.ephec-ti.be:8081/api/misc/heavy?name=toto"Deux cas ont été comparés :
- Cache Miss (1er appel) : l'API interroge directement la base de données car le cache ne détient pas la donnée voulue
- Cache Hit (2ème appel) : réponse servie directement depuis Redis

Sous forme de tableau:
| Type de requête | Temps total (real) |
|---|---|
| Cache Miss | 5.029s |
| Cache Hit | 0.022s |
Nous avons également mesuré le temps d'accès à l'endpoint /api/products/last avec la commande:
time wget -qO- "http://www.l1-7.ephec-ti.be:8081/api/products/last"
Sous forme de tableau:
| Type de requête | Temps total (real) |
|---|---|
| Cache Miss | 15.118s |
| Cache Hit | 0.019s |
- Analysez ces mesures : Est-ce que cette cache améliore les performances ? de combien ?
L’implémentation du cache permet une réduction significative du temps de réponse :
-
Gain de performance ≈ 228.591x plus rapide pour
/api/misc/heavy?name=toto -
Gain de performance ≈ 795.947x plus rapide pour
/api/products/last - Réduction de charge sur le backend et la base de données
- Temps de réponse quasi-instantané pour les appels répétés
Pour un vision plus concrète nous aurions pu effectuer des moyennes mais juste avec 1 appel(Cache Hit) nous avons déjà un ordre de grandeur.
En outre, ces résultats reflètent l'impact sur les performances globales, en particulier pour des services à latence élevée, que peut avoir une simple stratégie de mise en cache.
- Documentez la mise en oeuvre du CDN dans le service Web
Avertissement : Le CDN n'est pas fonctionnel.
Voici dans un premier temps la ressource CDN créée sur le portail de Gcore :

Il est ensuite requis d'indiquer la ressource suivante dans le fichier de configuration de notre serveur DNS :

Cela a été fait. Le fichier l1-7.zone du serveur DNS a été modifié et le serveur redéployé avec cette nouvelle configuration. Cela se vérifie en attachant un terminal Shell directement sur le conteneur du serveur et en allant vérifier que la record est bel et bien présent dans le fichier de zone :

Cependant, malgré cet ajout, le portail de Gcore signale que la configuration du DNS n'est pas effective :

Nous n'avons pas été en mesure d'élucider ce problème, même en faisant appel à des outils d'intelligence artificielle.
Après cela, nous avons tout de même modifié le fichier index.html du site web de Woodytoys de sorte à ce que l'image en arrière-plan ne soit plus délivrée par notre serveur web mais par la ressource CDN, ce en modifiant sa source :

Et sans surprise, nous faisons face à un problème. En retournant sur la page web de Woodytoys, la nouvelle page est alors servie (cela se confirme par le changement de la source de l'image dans le code HTML) or, elle est introuvable étant donné que notre CDN ne fonctionne pas, résultant donc un arrière-plan vide à l'exception de l'alt text :

- Documentez les mesures de performances obtenues après cette modification.
On peut dire qu'étant donné l'absence d'image, les performances ont été drastiquement améliorées ! Plus sérieusement, étant donné que le CDN n'est pas fonctionnel, la mesure de performance n'a été effectuée.
- Analysez les résultats obtenus.
Le résultat obtenu n'est pas celui escompté. Il aurait fallu une image de fond chargée plus rapidement étant donné le changement de source mais cela s'avère être un échec et les analyses n'ont donc pas pu être réalisées.
Citer et expliquer sur votre Wiki une solution pour améliorer les performances au niveau d'une DB? (une brève description et la présentation de l'un ou l'autre avantage, inconvenient, particularité, ... sont suffisants)
Par exemple celle ci:
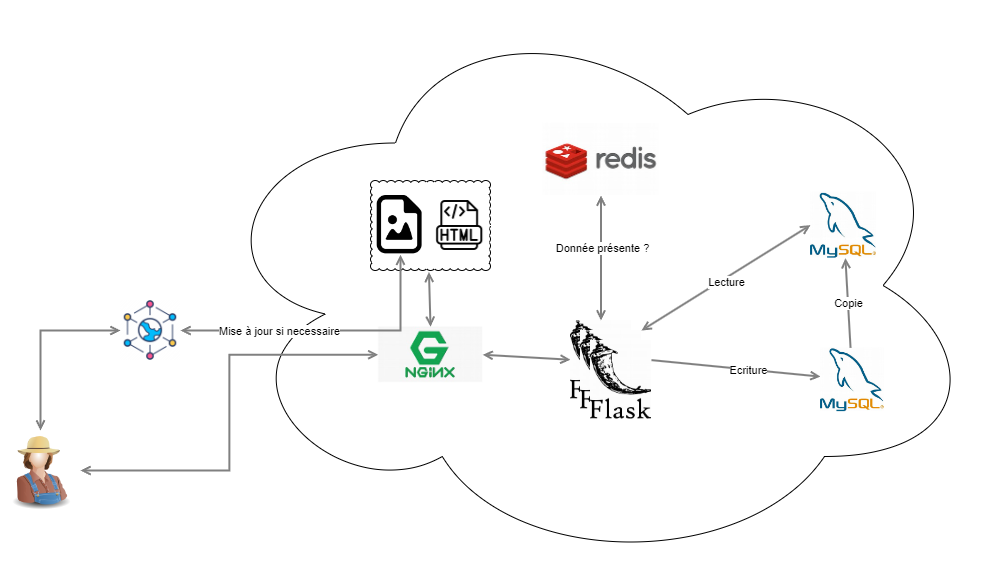
Command Query Responsibility Segregation(CQRS) is a software pattern that divides the system into two distinct parts, an append-optimised command side and a read-optimised query side. -Wikipedia
Donc au lieu d'utiliser une seule base de données pour tout, on divise:
- Une base de données pour les Commandes (création, modification, suppression)
- Ici, une copie de cette base de données optimisée pour les Lectures
- Scalabilité améliorée : on peut scaler indépendamment les lectures (souvent plus fréquentes) sans impacter les écritures.
- Optimisation ciblée : chaque base peut être optimisée pour son usage (ex : indexation pour lecture rapide).
- Moins de contention : les lectures n’interfèrent pas avec les écritures lourdes.
- Complexité accrue : Nécessite plus de composants (copie de la base de donées , synchronisation des données, gestion des incohérences temporaires).
- Temps réel pas garanti : Il y a souvent une latence entre une écriture et sa disponibilité en lecture.