TP09
Noms des auteurs : BONTEMS Antoine, SCHOONYANS Ann-Lore, LAMAND Cyril
Date de réalisation : 16/05/2025
-
Expliquez sur votre Wiki pourquoi l'utilisation de la directive
buildne convient pas dans le contexte Docker Swarm.- Car les fichiers sources des images ne sont pas transférables d'un noeud à l'autre pour lancer les services sur les autres noeuds, raison pour laquelle il faut passer par Docker Hub pour les récupérer.
-
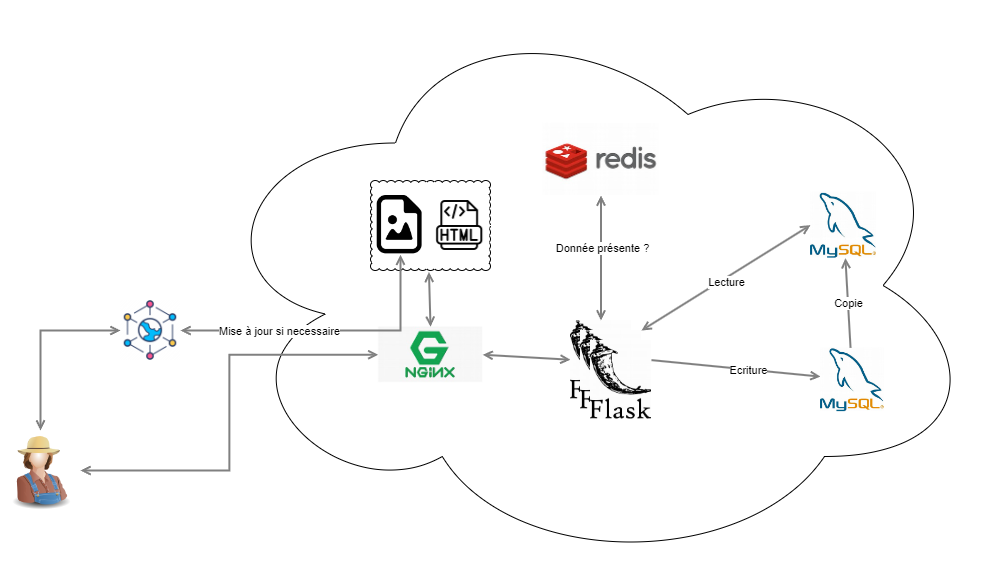
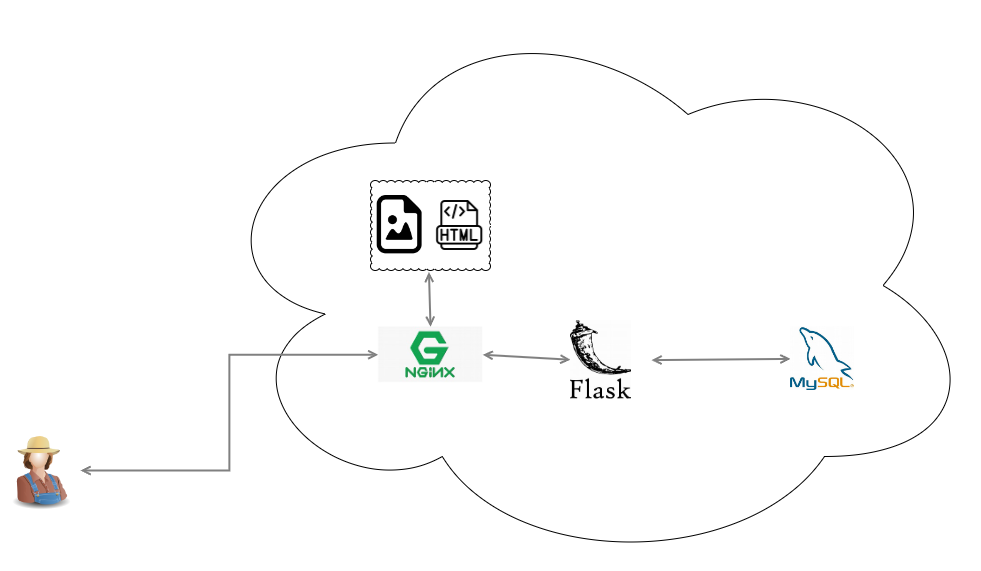
Documentez sur votre Wiki les flux de données présents, en vous basant sur un schéma commenté.
-
L'utilisateur envoie des requêtes HTTP via son navigateur. Toutes les requêtes sont d’abord reçues par Nginx, qui joue le rôle de reverse proxy. Si la requête concerne une ressource statique (HTML, image, CSS), Nginx répond immédiatement, ce qui réduit la charge du backend.
-
Par contre, si la requête concerne des ressources dynamiques, alors Nginx la transmet au serveur Flask. Flask joue le rôle du backend et interagit avec la base de données MySQL si besoin.
-
Une fois les données récupérées ou traitées, Flask répond à Nginx. Ce dernier renvoie ensuite la réponse finale à l’utilisateur.
-
 Stack Woodytoys
Stack Woodytoys
-
Documentez l'adaptation du service afin de le faire tourner sur Swarm.
- Pour faire tourner les services avec swarm, il fallait changer les
buildenimageet pusher les images sur Docker Hub pour un déploiement plus simple par la suite via d'autre manager par exemple.
- Pour faire tourner les services avec swarm, il fallait changer les
-
Documentez vos observation et analyses des limitations, en détaillant les performances chiffrées observées.
-
C'est supra loooooong à charger à cause de l'image en grande partie

-
La requête lourde dure 5s

-
Résultat de la commande wget avec 3 replicas vs avec 5 replicas


-
-
Documentez votre campagne de mesure
- Les mesures ont été prise avec la commande
time wget -r http://web.l2-7.ephec-ti.be/, avant et après les changements au niveau du nombre de replicas. Dans l'idéal, il faudrait en faire plusieurs et en faire des moyennes mais j'ai pas le time, sorry not sorry.
- Les mesures ont été prise avec la commande
- Est-ce que l'augmentation du nombre de replicas résout les problèmes ? Répondez en comparant les premiers chiffres de performance observés avec des mesures effectuées après la modification. Pour chacune des trois limitations, commentez les éventuelles améliorations en étant critiques (les limitations artificielles ne sont peut-être pas représentatives de la réalité).
Augmenter les réplicas ne change pratiquement rien (de ~16.2s à ~16.1s).
- Est-ce qu'il y des choses que vous pouvez mettre en place au niveau de Docker Swarm (outre les réplicas) pour améliorer les performances ? (Hints:
healthchecks(pour l'api) etplacement constraint(pour la database))
- Un healthcheck au niveau de l'api en vérifiant à intervalle régulier que le service fonctionne correctement
- Une contrainte de placement pour forcer la DB à être sur un noeud avec les ressources nécessaire pour que celle-ci soit stable
Avant tout changement au niveau de la cache :

Après un changement visiblement pire (alors que rien n'a changé comme l'image avait été gardée identique parce que Docker a pas envie de refaire les builds ou les pulls et que j'avais zappé ce détail) :

Après le bon changement :

- Documentez la mise en place du service Redis
- Le fichier main.py à été adapté pour que les requêtes déjà faites précédemment fasse appel à la cache plutôt qu'à la fonction qui est dans le cadre du TP volontairement ralentie.
- Documentez les mesures de performances obtenues après cette modification.
- Lorsqu'une requête pour une ressource déjà demandée à lieu, le temps de réponse est drastiquement augmenté.
- Analysez ces mesures : Est-ce que cette cache améliore les performances ? de combien ?
- Oui, pour les requêtes récurrentes, et de beaucoup, de 15sec à quelques ms.
-
Documentez la mise en oeuvre du CDN dans le service Web
- La mise en oeuvre est assez bien documentée ici : https://gcore.com/docs/cdn/cdn-resource-options/general/create-and-set-a-custom-domain-for-the-content-delivery-via-cdn
-
Documentez les mesures de performances obtenues après cette modification.
- La page charge maintenant bien plus vite car l'image ne prend plus 16sec à charger mais à peine 0.5sec

- La page charge maintenant bien plus vite car l'image ne prend plus 16sec à charger mais à peine 0.5sec
-
Analysez les résultats obtenus.
- Je suis pas expert mais 0.5sec par rapport à 16sec, c'est quand même pas mal hein. (analyse de qualité ouais mais j'vais me défenestrer là sinon)
Citer et expliquer sur votre Wiki une solution pour améliorer les performances au niveau d'une DB? (une brève description et la présentation de l'un ou l'autre avantage, inconvenient, particularité, ... sont suffisants)
- On voit ici que la base de donnée est répliquée, la copie est mise à jour régulièrement mais cela permet de répartir la charge entre lecture et écriture pour éviter le problème au niveau de la DB qui est limitée à une seule connexion.