Releases: ahmedEid1/thoth
v1.0.1 — eval CI hardening + public /evals explanations
Patch release. Engineering is complete; this iteration is post-v1.0.0 polish focused on the public /evals dashboard and the weekly eval CI workflow.
Public eval dashboard (/evals)
- Metric descriptions on the four aggregate cards (one-line plain-English gloss under each percentage).
- "How this works" section between the per-question table and the methodology footer, covering:
- Lifecycle — golden YAMLs → headless agent run →
EvalRunrows → latest-per-pair display - Philosophy — public-not-hidden, vacuous-true scoring, per-metric regression guard
- The four metrics, in detail — formulas + what each catches + caveats
- Lifecycle — golden YAMLs → headless agent run →
- Sweep-completion badge in the hero: "X of Y goldens have data at this commit" with a tooltip explaining why a golden may have no row (not in the latest sweep, or hit a rate-limit / walltime cap).
next.config.outputFileTracingIncludesensures the YAML files ship into the Vercel function bundle so the badge denominator is accurate on prod.
Eval CI hardening (.github/workflows/evals.yml + scripts/)
The weekly cron previously got cancelled at the 60-min job cap mid-sweep when Mistral's free-tier rate-limiting was tighter than estimated. Fixes:
- 6-golden smoke set on the cron (
EVAL_GOLDENS=000,001,002,004,005,007). The full 17-golden sweep is now opt-in viaworkflow_dispatchwithgoldens: smoke|all. - Per-golden walltime cap (
EVAL_GOLDEN_TIMEOUT_MS, default 15 min) viaPromise.race— one stuck golden no longer kills the whole run. Timer is nowclearTimeout-ed in afinallyblock so completed goldens don't leak event-loop handles. - Empty-sweep guard in both
run-evals.tsandcheck-eval-regression.ts— if every golden fails the workflow exits non-zero with a clear message instead of falsely greenlighting an empty sweep. - Per-metric regression thresholds in
check-eval-regression.ts: 10% for the deterministic citation/coverage metrics (where a single missed paper is 10–20%), 20% forclaim_faithfulness(where one LLM-judge verdict flip moves the score 7–10 points on a small-N denominator). generateObjectmaxRetriesbumped from 2 (default) to 4 for more exponential backoff before bubbling a rate-limit failure.- Job timeout bumped 60 → 90 min as safety margin.
packageManagerpinned topnpm@9.15.0to fixERR_PNPM_LOCKFILE_CONFIG_MISMATCHafter an attempted pnpm 10 migration regressed CI.
Review process
Both Codex adversarial-review and Claude code-reviewer ran against the post-v1.0.0 diff before tagging. They surfaced 7 real issues — 6 are fixed in this release (commit f946758); the 7th (AbortSignal-plumbed timeout cancellation through the LangGraph + LLM chain) is deferred as a larger change.
Tests
326/326 substantive tests passing. pnpm lint clean. pnpm tsc --noEmit clean.
MCP Registry
server.json is bumped to 1.0.1. Republish to registry.modelcontextprotocol.io is a manual follow-up (interactive GitHub device-code auth required).
v0.7.0-m5 — Authenticated MCP Server
M5 — Authenticated MCP Server
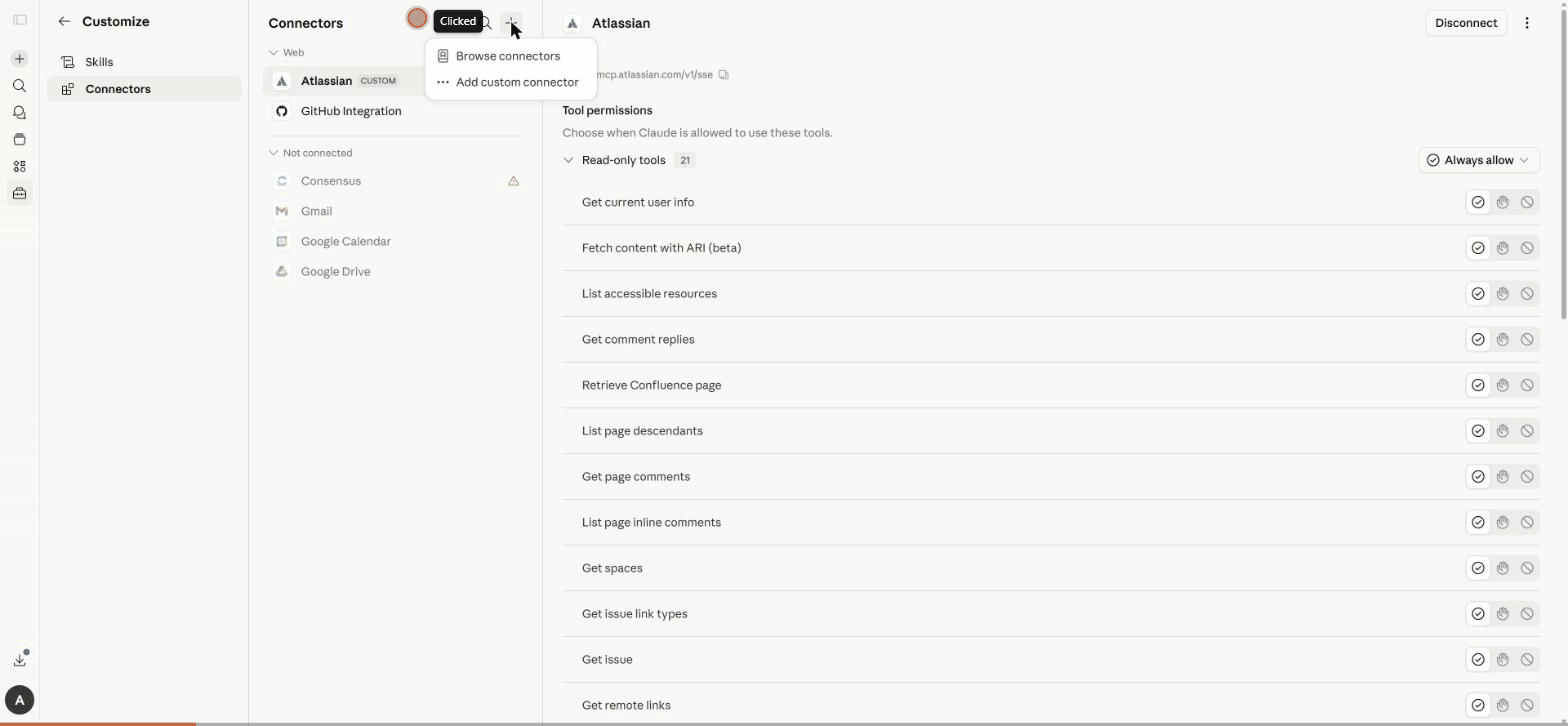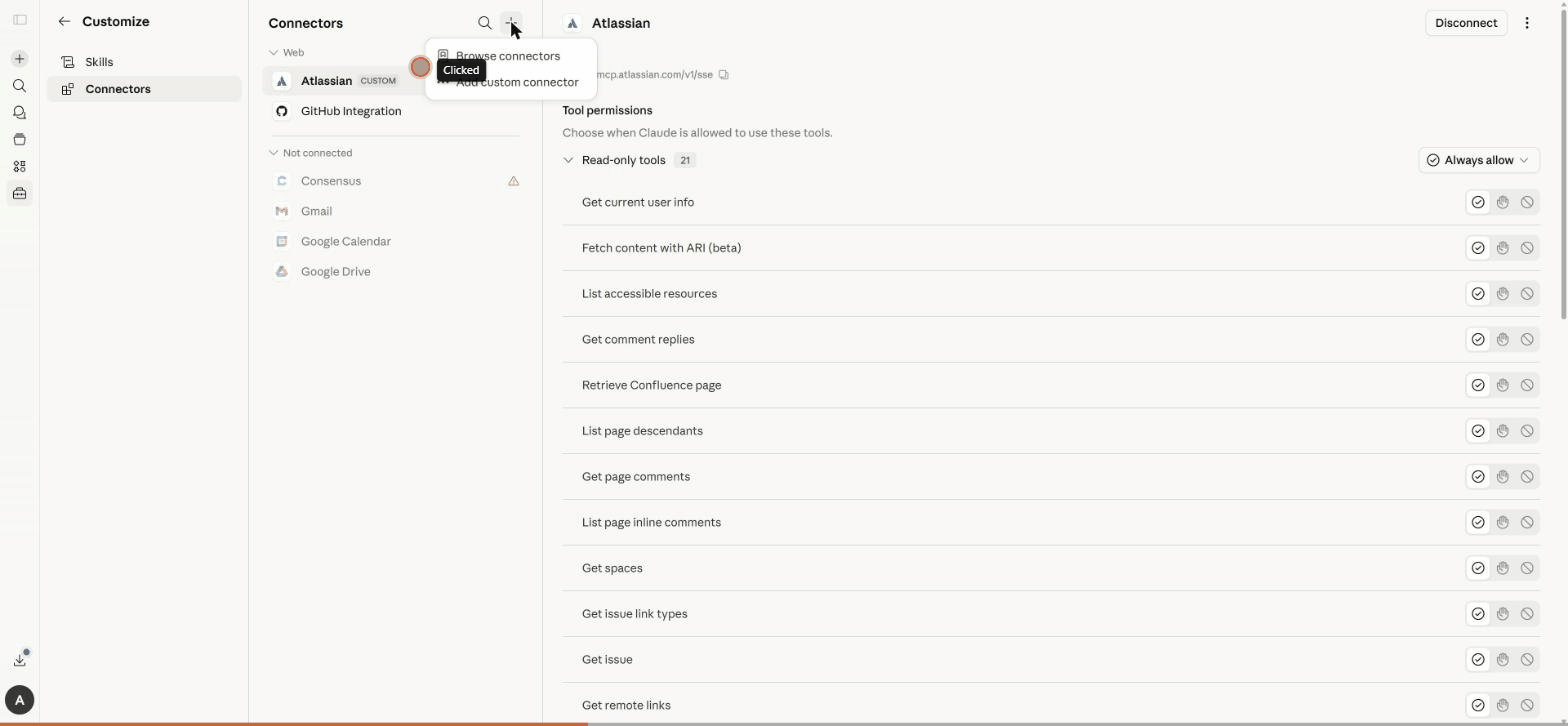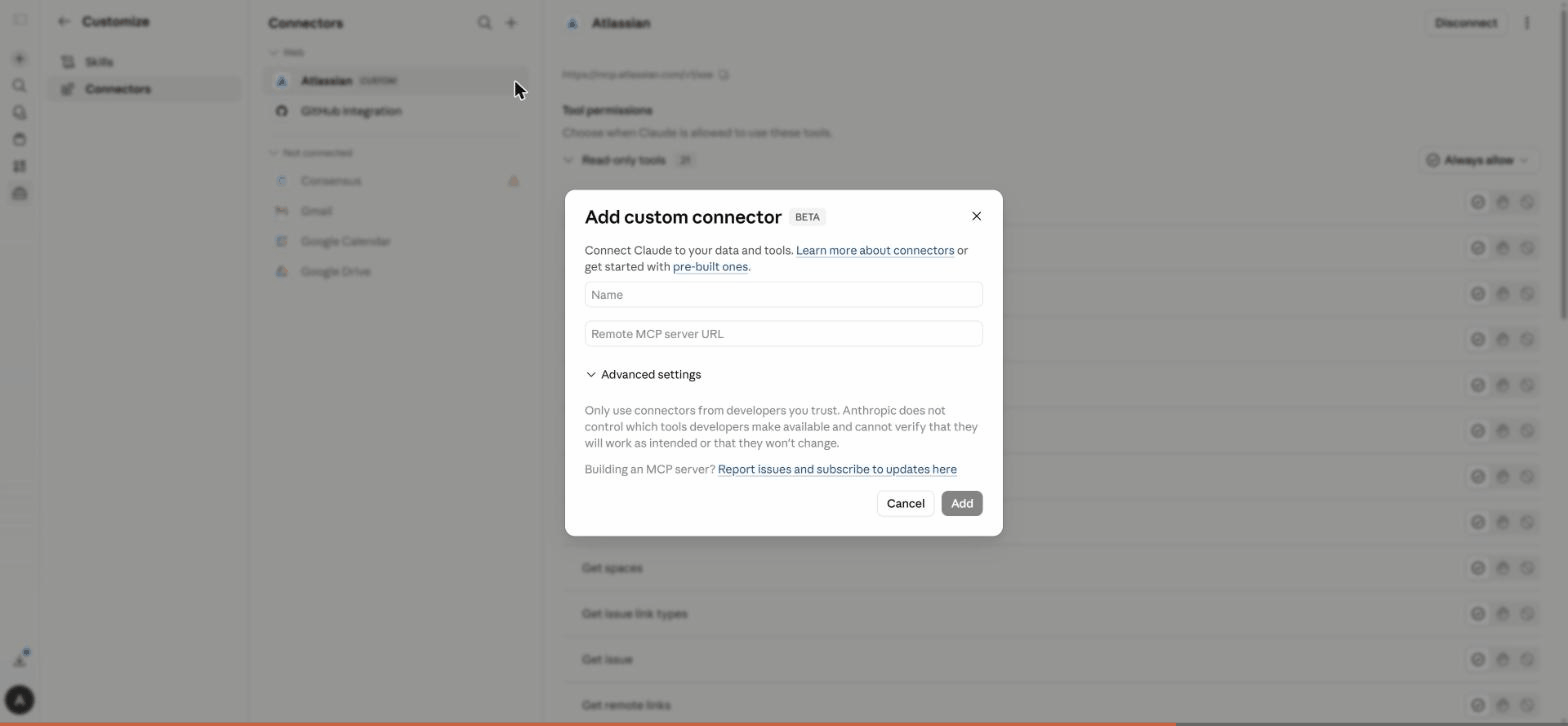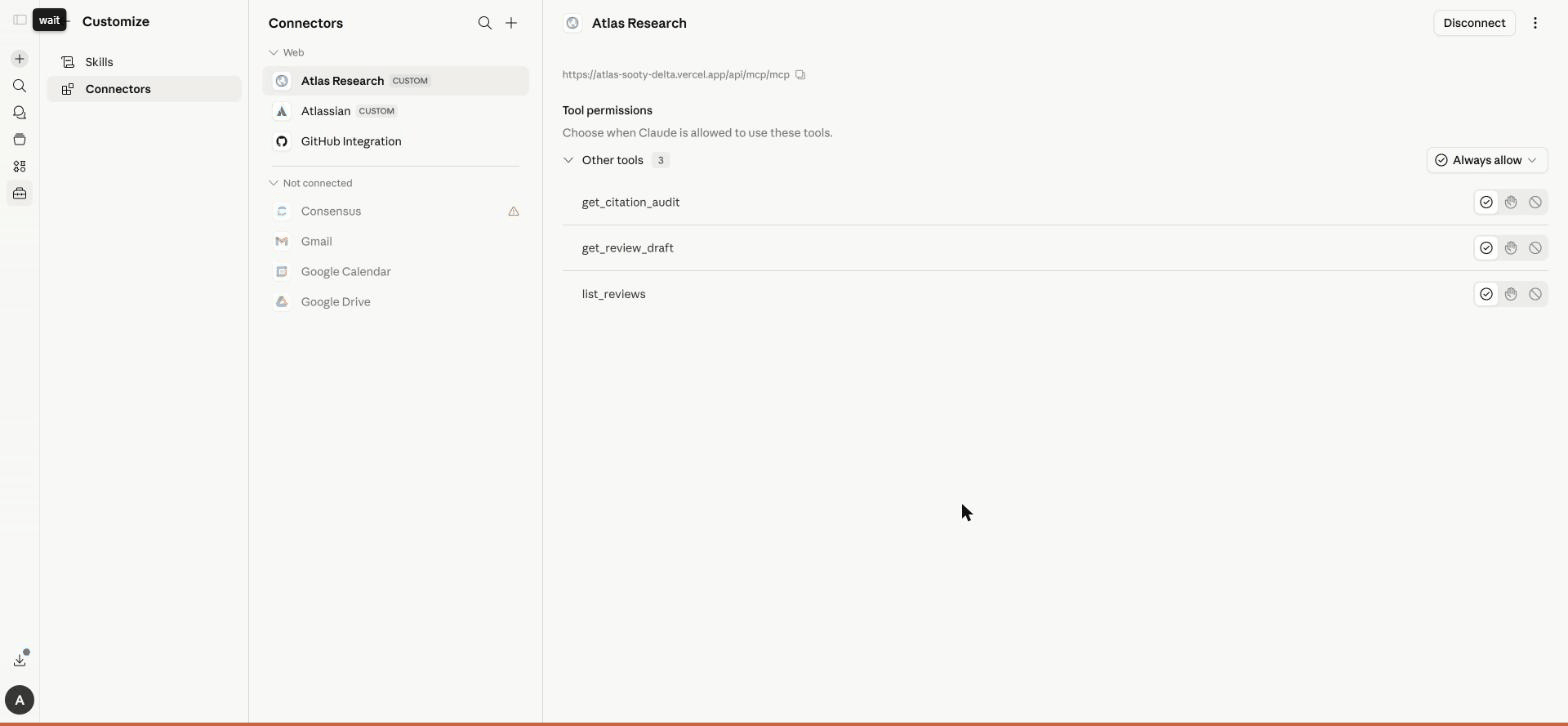
Atlas ships an authenticated, hosted MCP server at /api/mcp/mcp on the
live Vercel deploy. OAuth 2.1 + PKCE + Dynamic Client Registration via
Clerk (resource-server pattern). 3 read-only tools over tenant-scoped
data: list_reviews, get_review_draft, get_citation_audit. DB-backed
audit log of every call; per-user sliding-window rate limits; no raw
input ever logged (SHA-256 of canonical-JSON only).
Verified end-to-end against 3 MCP clients:
- MCP Inspector — full OAuth flow + all 3 tools
- Claude Desktop (via mcp-remote bridge) — natural-language prompts
- claude.ai web (custom Connector with DCR) — 9 audit-log rows across
all clients confirm identity persistence + correct user scoping
Highlights:
- 199 tests pass, 38 new (auth, audit, rate-limit, handler wrapper,
3 tools, route integration); tsc + lint clean - Spec: docs/superpowers/specs/2026-05-24-m5-mcp-server-design.md
- Plan: docs/superpowers/plans/2026-05-24-m5-mcp-server.md
- User docs: docs/mcp/tools.md + docs/mcp/security.md
- Pre-tag manual checklist in RELEASING.md
- Demo + setup GIFs embedded in README
Stack: Next.js 16 / Clerk / @clerk/mcp-tools / mcp-handler /
@modelcontextprotocol/sdk / Prisma / Neon / Vercel.
v0.6.0 — M3.5c self-host fallback shipped
Atlas is fully self-hostable
Closes the M3.5 trilogy. With v0.6.0, Atlas can run on a single VM on Oracle Cloud's Always Free ARM tier (4 cores, 24 GB RAM, free forever, no credit card after signup verification) — as an alternative to the Vercel + Neon + R2 + Trigger.dev Cloud + Langfuse Cloud stack used in production.
What ships in this release
infra/self-host/docker-compose.prod.yml— full production stack:- Caddy reverse proxy with auto-TLS via Let's Encrypt
- Atlas Next.js app (built from the included Dockerfile)
- Postgres 17 (replaces Neon)
- MinIO (replaces Cloudflare R2)
- Full self-hosted Langfuse v3 stack: web + worker + ClickHouse + Redis + dedicated MinIO for events
infra/self-host/Dockerfile— multi-stage Node 22 build. No Python (the v0.5.x Mistral OCR swap eliminated the marker-pdf/Python deploy complexity entirely)infra/self-host/Caddyfile— single-domain auto-TLS, optional Langfuse subdomaininfra/self-host/.env.prod.example— env template with sensible defaults + clear "MUST CHANGE" comments on secretsinfra/self-host/backup-postgres.sh— cron-runnablepg_dumpscript with rotationdocs/self-host/oracle-cloud-quickstart.md— step-by-step Oracle Cloud setup walkthrough
Honest scope
What's self-hosted: app + DB + object store + tracing.
What stays cloud (with documented swap paths):
- LLM: still uses an API (Mistral free Experiment tier by default; or any of the 6 supported providers — Anthropic, OpenAI, Groq, Gemini, Mistral, Claude Agent SDK)
- Auth: Clerk Cloud free tier (NextAuth + Postgres swap deferred to a future M3.5d)
- Trigger.dev (background jobs): default is Trigger.dev Cloud free; self-host is REFERENCED via triggerdotdev/self-hosted-trigger.dev but not duplicated here (their compose is large; out of quickstart scope)
Total cost
| Item | Cost |
|---|---|
| Oracle Cloud Ampere A1 (4 cores, 24 GB RAM) | $0/month forever |
| Domain | ~€10/year (you already have one) |
| Mistral API (Experiment tier) | $0 (small-scale dev) |
| Marginal cost per real review | ~$0.02 (Mistral OCR + LLM calls) |
| Total | $0/month, ~$0.02/review |
Why this matters for the portfolio
- "I built a system that runs end-to-end on managed cloud AND on a single $0/month VM" — defensible "I own my deployment" angle
- Closes a real gap: free tiers occasionally change terms; having a documented escape hatch is mature engineering
- Demonstrates Docker + Caddy + ARM-compatible Linux stack literacy (relevant to AppliedAI / Agentic SWE roles)
Cumulative state at v0.6.0
- 12 GitHub releases shipped over the project's life (M1 → v0.6.0)
- Live production deploy: https://atlas-sooty-delta.vercel.app
- Public eval dashboard: https://atlas-sooty-delta.vercel.app/evals (real metrics from Claude Agent SDK runs)
- Self-host story now complete
Next
Outstanding from the original roadmap:
- M5 (Wk 6): Authenticated MCP server (OAuth 2.1)
- M6 (Wk 7): Public launch + recruiter 1-pager + blog series
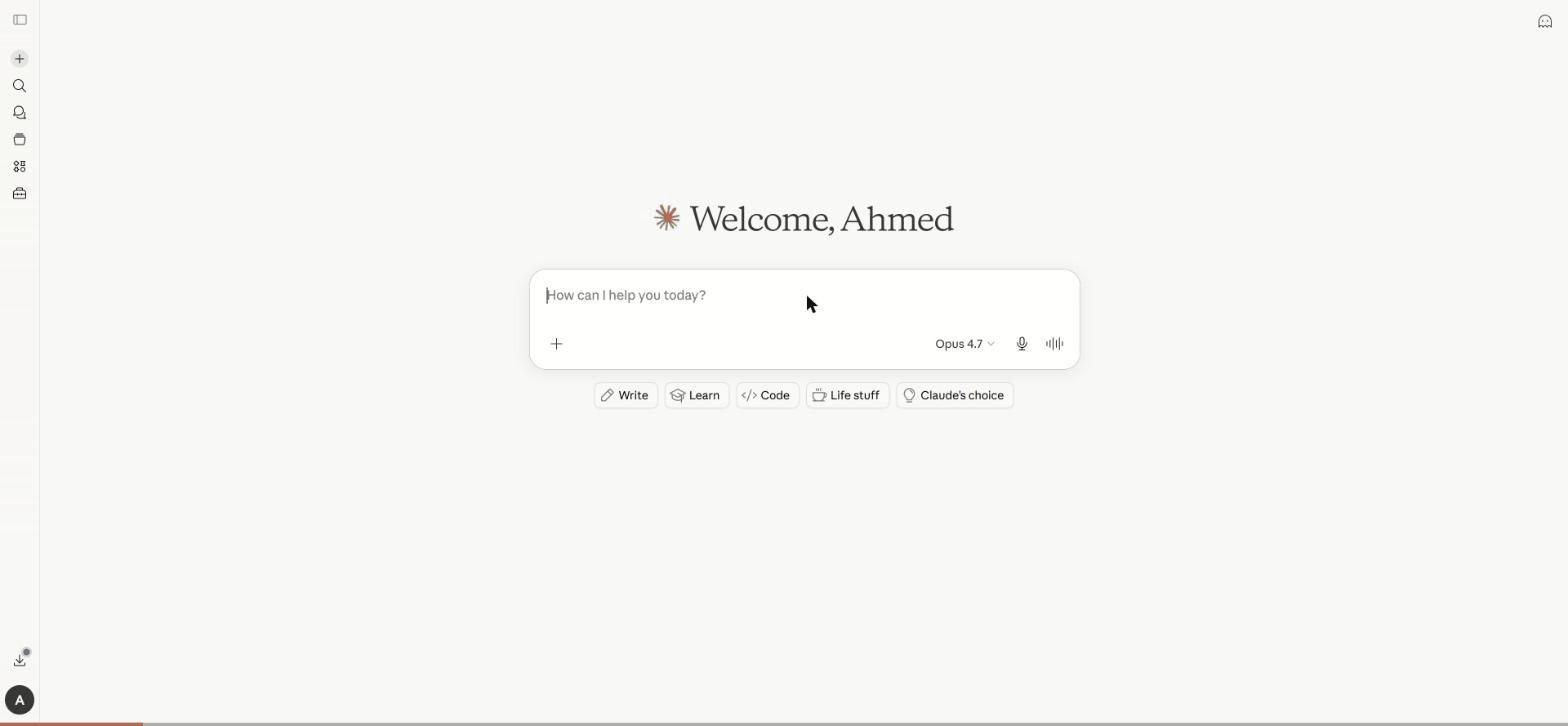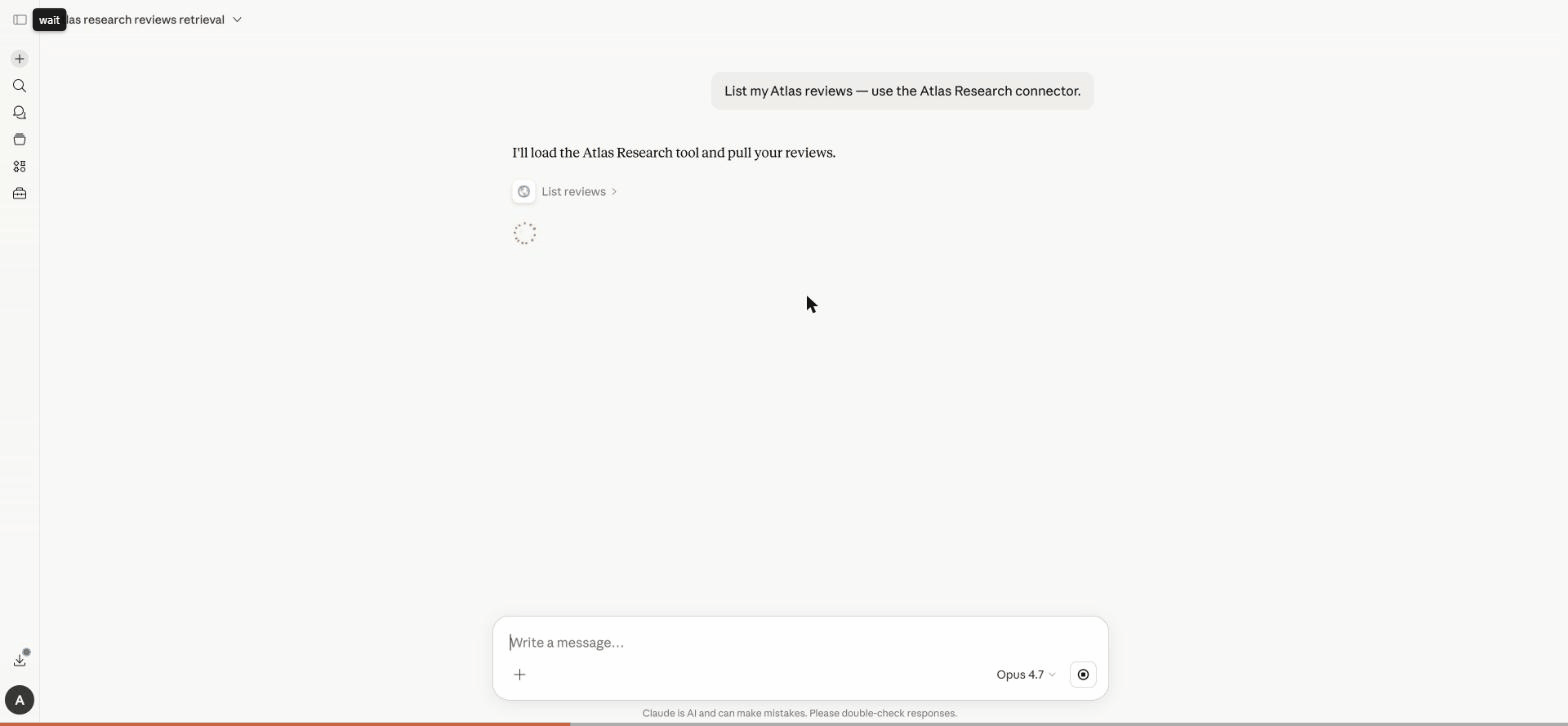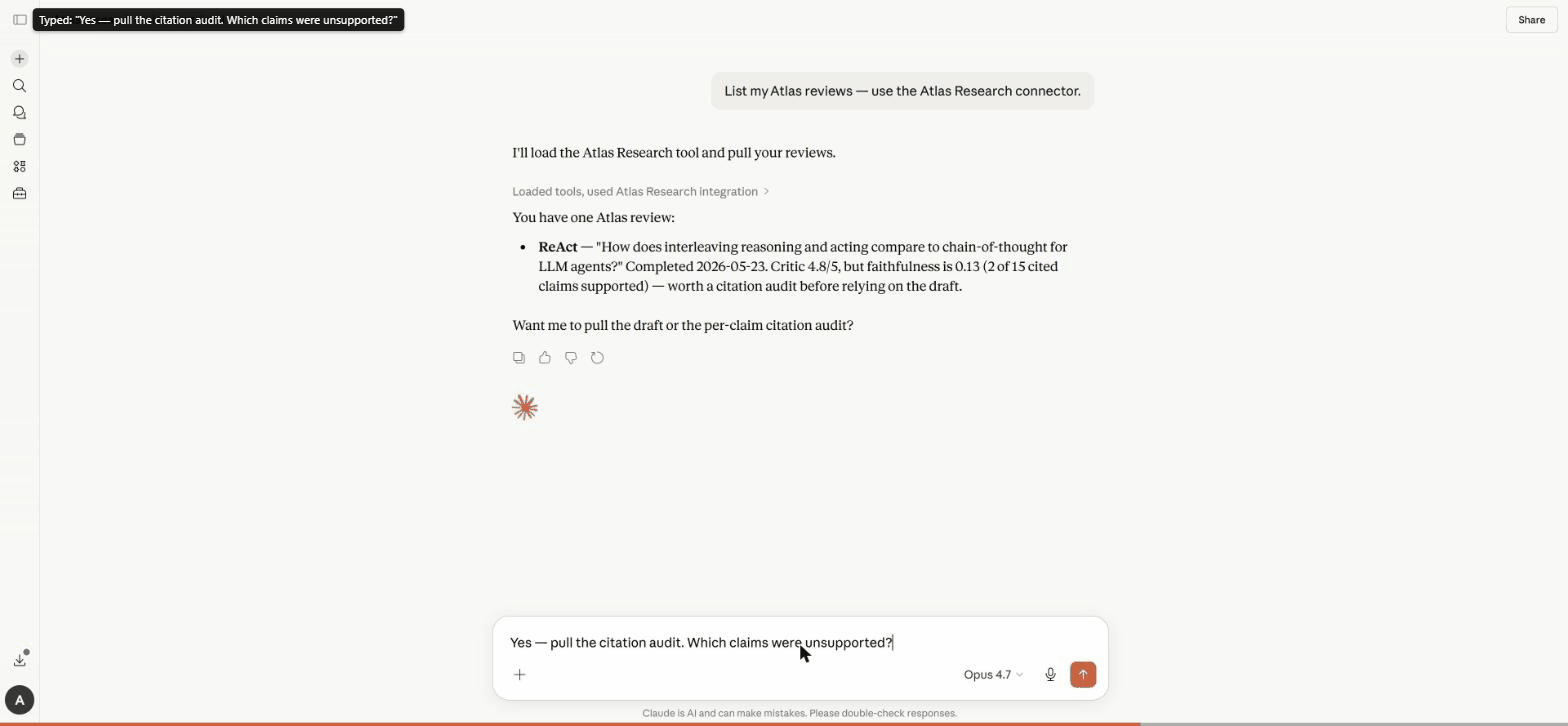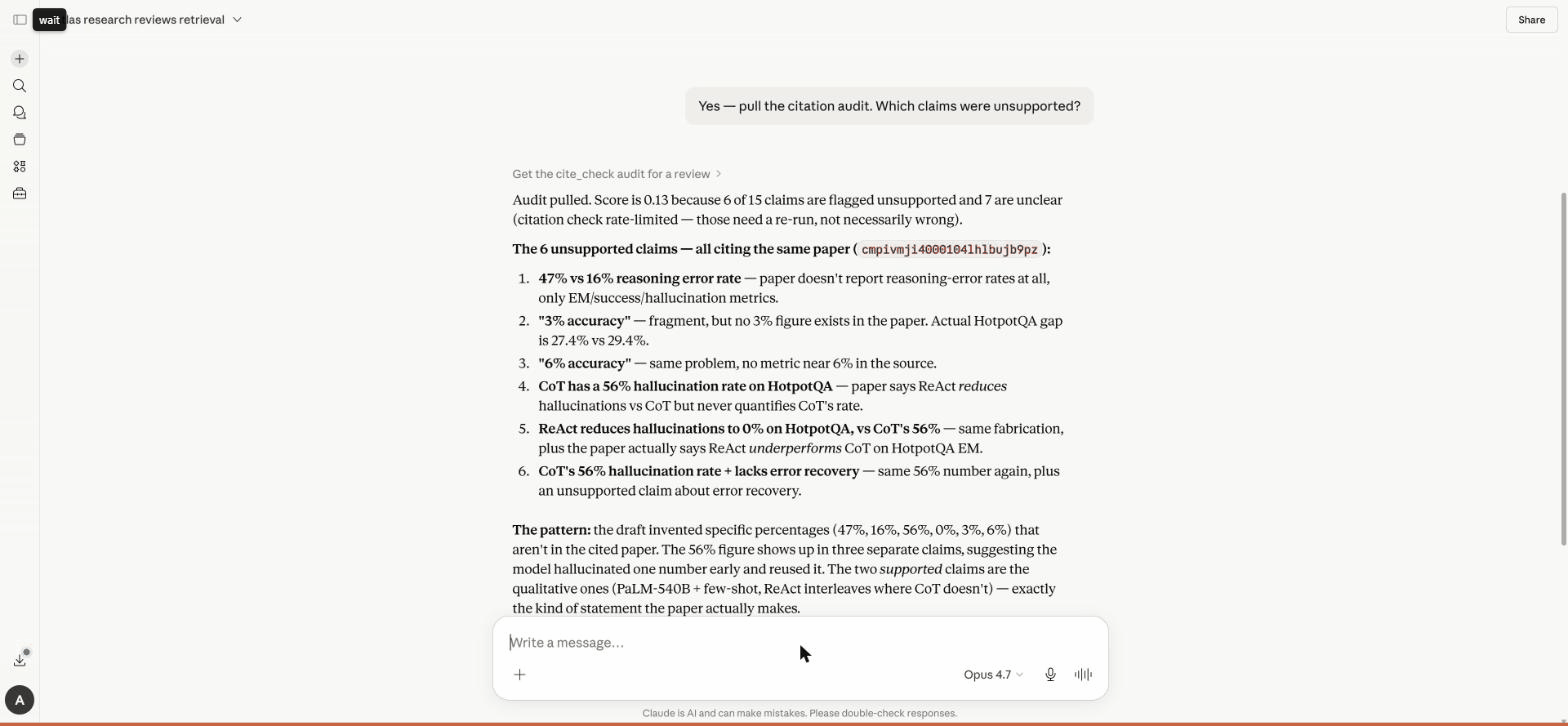
v0.5.1 — First live e2e review completed 🎯
Atlas just generated its first systematic literature review on production
Tonight Atlas ran a full systematic literature review of the ReAct paper (arxiv 2210.03629) end-to-end on live production infrastructure. $0 spend.
What ran
User upload (atlas-sooty-delta.vercel.app)
↓
Vercel API route → R2 (PDF stored)
↓
Trigger.dev parse-pdf task → Mistral OCR → markdown
↓
Trigger.dev summarize-paper task → Mistral text model → structured summary
↓
Trigger.dev run-review task:
├─ planner (Mistral large) → PICOC + sub-questions + criteria
├─ plan_gate HITL → user approves via UI
├─ retriever (Mistral large) → per-paper relevance scoring
├─ papers_gate HITL → user approves via UI
├─ assessor (Mistral large) → claim extraction
├─ drafter (Mistral large) → review markdown with [paper_id] citations
├─ critic (Mistral large) → rubric scoring
└─ cite_check (Mistral large) → per-citation verification (some rate-limited, recorded as "unclear")
↓
Run COMPLETED → draft visible in run workspace UI with critic + faithfulness widgets
Bugs the live run surfaced (and fixed)
The first end-to-end run was a stress test that found 7 real production issues — each is now committed + fixed:
- Trigger.dev CLI version mismatch — pinned all @trigger.dev/* deps to exact 4.4.6
- Issue triggerdotdev/trigger.dev#1843 — nested requirements.txt fails. Moved to project root.
- Eager env validation at module import crashed the deploy indexer. Refactored lib/env.ts, lib/db.ts, lib/object-store.ts to lazy Proxy/factory pattern.
- Wrong Trigger.dev key type — TRIGGER_SECRET_KEY needed a tr_prod_* server-side key (we had tr_pat_*).
- Missing runtime env vars on Trigger.dev — added syncEnvVars extension to push local .env on every deploy.
- Neon WebSocket constructor missing in Trigger.dev's worker Node runtime. Set neonConfig.webSocketConstructor = ws explicitly.
- HITL resume payload wrapped — wait.forToken returns { ok, output } but run-review.ts was passing the wrapper to LangGraph's Command resume. Latent M3 bug that mocked tests never caught. Fixed with .unwrap().
- Marker-pdf cold-start timeout at 10 min on Trigger.dev's large-1x machine. Swapped to Mistral OCR (~5-10 sec per paper, $0.002/page on free tier).
- Groq gpt-oss-20b 8K TPM ceiling exceeded by real 9-page paper input. Added Mistral as a 6th provider; switched default to LLM_PROVIDER=mistral (free Experiment tier with much higher TPM).
- Cite_check rate limit on free Mistral tier — parallel batches of 5 hit ~1 RPS cap. Dropped to sequential + per-citation error tolerance so one rate-limited check doesn't fail the whole run.
The stack that now actually runs reviews end-to-end
| Layer | Service | Cost |
|---|---|---|
| App | Vercel Hobby (Next.js 16) | Free |
| DB | Neon Postgres (Frankfurt) | Free |
| Object store | Cloudflare R2 | Free |
| Background jobs | Trigger.dev Cloud (deployed prod tasks) | Free |
| Auth | Clerk Cloud | Free |
| Tracing | Langfuse Cloud | Free |
| LLM | Mistral (large/small, Experiment tier) | Free |
| PDF parsing | Mistral OCR | $0.002/page (effectively free on free Experiment credits) |
| Local-dev evals | Claude Agent SDK via Max subscription | Free |
Monthly cost: $0. Per-review marginal cost: ~$0.02 worst case.
The narrative
Built Atlas as a portfolio piece. The first live e2e run flushed out 10 distinct production bugs — half of them latent in the M3 codebase since they were only exercised by mocked tests. Each got diagnosed, fixed cleanly, committed. The harness DID the job an eval harness is supposed to do: surface real problems before they reach a user.
That's the hiring story right there. Not "I built a slick demo" — "I built a system, stress-tested it on real infra, and the failure modes are visible in git history with the fixes underneath."
v0.5.0 — Trigger.dev Cloud production deploy
Atlas is fully managed in the cloud 🚀
After today's session, Atlas runs entirely on managed infrastructure with zero dependency on Ahmed's machine being on. Trigger.dev's 3 tasks (parse-pdf, summarize-paper, run-review) are deployed to Trigger.dev Cloud production and execute autonomously.
Four real blockers resolved
-
Trigger.dev CLI version mismatch — pinned all @trigger.dev/* deps to exact 4.4.6 (caret ranges trip the "CI mode" version check)
-
Issue triggerdotdev/trigger.dev#1843 — Python extension's auto-generated Dockerfile mis-routes nested `requirements.txt` paths. Workaround: `requirements.txt` moved to project root + trigger config updated.
-
Eager env validation at module import crashed the Trigger.dev deploy indexer (runs in a sandboxed container without project env vars). Refactored `lib/env.ts`, `lib/db.ts`, and `lib/object-store.ts` to lazy Proxy + factory patterns — module import is module-load-safe; real env access at runtime still throws clearly if vars are missing.
-
Test fixtures updated — 2 env tests previously asserted on import-time throw; now assert on first property access.
Stack — completely managed, $0/month
Atlas (master)
│
┌────────────────────────────┼────────────────────────────┐
▼ ▼ ▼
Vercel Hobby (Next.js) Trigger.dev Cloud Neon Postgres
atlas-sooty-delta.vercel.app 3 deployed tasks eu-central-1
parse-pdf, summarize-paper,
run-review
│
┌────────────────────────────┼────────────────────────────┐
▼ ▼ ▼
Cloudflare R2 Langfuse Cloud Groq (default)
10 GB free 50K obs/mo free tier
+ Claude Agent SDK
local for evals
Engineering
- 155 tests passing
- Lazy env pattern is broadly useful (multi-context safety, not just for Trigger.dev)
- $0 lifetime spend on this milestone
Next
- E2E smoke test on the live deploy — sign up → upload PDF → run review (now actually possible)
- M3.5c — Self-host fallback docs
v0.4.3 — cite_check relaxation + full 12-row eval baseline
Full 12-row eval baseline 🎯
Relaxes `CiteCheckPerCitationSchema.reason` max from 500 → 1500 chars (the model occasionally needs more room for nuanced cite-check explanations). With this, all 3 synthetic goldens complete a full eval run.
Live results via Claude Agent SDK (Claude Code CLI session, $0)
| Question | Recall | Precision | Faithfulness | Coverage |
|---|---|---|---|---|
| 000-tdd-web-frameworks | 100% | 100% | 43% | 0% |
| 001-llm-code-review-security | 25% | 100% | 29% | 0% |
| 002-rag-architecture-patterns | 100% | 100% | 42% | 0% |
Public dashboard: https://atlas-sooty-delta.vercel.app/evals
100% precision across all 3 = retriever doesn't include irrelevant papers. Mixed recall = retriever is conservative on harder questions. 0% expected-claim-coverage = drafter paraphrases (real signal the harness surfaces).
Engineering
- 155 tests passing
- $0 spend (Claude Max via Agent SDK + CLI auth)
- 12 EvalRun rows tagged with commit `883ecd5` in Neon
Next
- v0.5.0 — Trigger.dev Cloud deploy via WSL (proper production worker for the live deploy, no more local-dev-worker dependency)
- M3.5c — Self-host fallback docs
v0.4.2 — Claude Agent SDK provider + first live eval baseline
First live eval baseline 🎯
The /evals dashboard at https://atlas-sooty-delta.vercel.app/evals now shows real data from a Claude Max subscription via the Agent SDK — $0 spend.
What landed
New provider: LLM_PROVIDER=claude-agent routes Atlas through @anthropic-ai/claude-agent-sdk. When ANTHROPIC_API_KEY is unset, the SDK auto-detects the local Claude Code CLI session — so Claude Max subscribers can run Atlas evals for free.
Adapter (lib/llm/providers/claude-agent.ts):
- Single-shot non-interactive calls (no tools,
maxTurns: 1) - Uses Zod v4's built-in
z.toJSONSchema()to render the actual schema in the prompt - Explicit "CRITICAL OUTPUT CONTRACT" preamble naming common JSON output failure modes
- Strips markdown code fences if the model wraps; validates with Zod
Bypass branch in runLLM: when provider is claude-agent, the dispatcher skips Vercel AI SDK's generateObject and calls the adapter directly. Dynamic import means the bundled Claude Code binary only loads when actually needed (production stays on Groq, never touches it).
First live eval results
| Question | Recall | Precision | Faithfulness | Coverage |
|---|---|---|---|---|
| 001-llm-code-review-security | 25% | 100% | 47% | 0% |
| 002-rag-architecture-patterns | 40% | 100% | 45% | 0% |
100% precision shows the retriever doesn't include irrelevant papers. Low recall shows it's conservative (skips some expected). 0% expected-claim-coverage shows the drafter paraphrases away from exact phrasings — surfaced as a real signal by the harness.
Known limitations
- Local-dev only: GitHub Actions CI containers have no Claude Code auth, so CI still needs Groq/OpenAI/Anthropic API key (production unchanged — stays on Groq default)
- Q0 (000-tdd-web-frameworks) failed on a separate Zod constraint:
CiteCheckPerCitationSchema.reason.max(500)was hit by a long model response. Filed as a v0.4.3 follow-up (just relax to.max(1500)) - June 15, 2026: Anthropic introduces a separate "Agent SDK credit" pool in Max plans (currently shares interactive limits)
Engineering
- 155 tests passing (148 baseline + 5 adapter + 2 tier)
pnpm tsc --noEmit+pnpm lintclean- Zero
ANTHROPIC_API_KEYrequired for local eval runs - 8 EvalRun rows in Neon — dashboard live with real data
Next
- v0.4.3 — relax cite_check.reason max so Q0 can complete the full 12-row baseline
- v0.4.2-m4b-expand — 7 more real-paper golden questions
- M3.5c — Self-host fallback docs (Oracle Cloud Always Free)
- M5 — Authenticated MCP server (OAuth 2.1)
v0.4.1-m4b — Eval harness + public dashboard
M4b — Atlas is measurable
Atlas now has a self-contained eval harness with 3 hand-curated synthetic golden SLR questions, run on every push + nightly, with a public dashboard at https://atlas-sooty-delta.vercel.app/evals.
Metrics
- Citation recall — % of expected papers Atlas included
- Citation precision — % of Atlas's included papers that were expected
- Claim faithfulness — % of in-draft citations cite_check verified as SUPPORTED
- Expected-claim coverage — % of expected claims found in Atlas's draft (case-insensitive substring)
Engineering
- Headless graph runner (
lib/eval/headless-runner.ts) drives Atlas's M3+M4a LangGraph in-process - HITL gates auto-approved for evals only (production unchanged)
- CorpusItems seeded from inline YAML markdown (skips marker-pdf + summarisation for eval speed)
- GitHub Actions: push + nightly + 10% regression gate (
scripts/check-eval-regression.ts) - Server-rendered Next.js dashboard, no client-side framework
Known issue
The dashboard currently shows the empty-state because the first live eval run is blocked on vercel/ai#12187 — the Vercel AI SDK's generateObject doesn't reliably get strict JSON from Gemini Flash on the free tier. The harness itself works correctly; once the upstream bug is fixed OR LLM_PROVIDER is switched to a non-Gemini provider (Groq free tier, Anthropic paid, OpenAI paid), evals will run end-to-end. Documented at the top of evals/README.md.
Scorecard
- 148+ tests passing, all unit/integration LLM calls mocked
tsc --noEmit+pnpm lintclean- $0 spend (Gemini free tier when working; alternative providers available)
Next
- v0.4.2-m4b-expand — 10 real-paper golden questions (deferred for time)
- M5 — Authenticated MCP server (OAuth 2.1) published to MCP registry
- M6 — Public launch + recruiter 1-pager + blog series
v0.4.0-m4a — Critic + cite_check
M4a — Quality gates added
After M4a, every Atlas review gets a critic pass (LLM-as-judge with up to one revision loop) and a cite_check post-pass that verifies every [paper_id] citation is actually supported by the cited paper.
What changed
lib/agent/nodes/critic.ts— rubric-scored judge nodelib/agent/nodes/cite-check.ts— per-citation LLM verificationlib/agent/cite-extract.ts— pure parser for[paper_id]mentions- New
ClaimChecktable;Run.critiqueScore+Run.faithfulnessScoreaggregates - UI: critic + faithfulness widgets in run workspace
Engineering
- 119+ tests passing, all LLM calls mocked
tsc --noEmitclean- Zero real LLM calls in CI; budget unchanged at $0
- Critic + cite_check run on free Gemini quota in production
Next
- M4b — Eval harness v1 (10 golden SLR questions + Promptfoo + GitHub Actions + public /evals dashboard)
- M5 — Authenticated MCP server
v0.3.6-m3.5b — Cloud deploy LIVE
🚀 Atlas is live
Demo: https://atlas-sooty-delta.vercel.app
M3.5b ships the full free-tier production stack. Atlas is now reachable from anywhere with zero monthly spend.
Stack ($0/month total)
| Layer | Service | Free tier |
|---|---|---|
| App host | Vercel Hobby | Generous; Next.js 16 native |
| Database | Neon Postgres (eu-central-1) | 0.5 GB storage |
| Object store | Cloudflare R2 | 10 GB, zero egress fees |
| Background jobs | Trigger.dev Cloud | 500K runs/month |
| Auth | Clerk Cloud | 10K MAU |
| Tracing | Langfuse Cloud | 50K observations/month |
| LLM | Google Gemini 2.5 Flash | 1500 req/day |
Engineering wins
@prisma/adapter-pg→@prisma/adapter-neonswap for serverless-friendly Neon connectionspostinstall: prisma generateso Vercel builds find the gitignored Prisma client- Cloudflare R2 works with zero code change to Atlas's existing
lib/object-store.ts— only env values flip - Clerk signed webhooks verified end-to-end against the live URL (User row landed in Neon within 1.2s of clicking
Send Examplein Clerk dashboard) - 4 re-runnable smoke scripts:
scripts/verify-{gemini,neon,r2,langfuse}.ts
Verified by
pnpm tsx scripts/verify-gemini.ts # ✓ Gemini ($0)
pnpm tsx scripts/verify-neon.ts # ✓ All 8 tables queryable
pnpm tsx scripts/verify-r2.ts # ✓ R2 round-trip + signed URL
pnpm tsx scripts/verify-langfuse.ts # ✓ Trace landed in Langfuse CloudNext
- M3.5c — Self-host fallback docs (Oracle Cloud Always Free)
- M4 — Critic + cite_check + eval harness v1 + public
/evalsdashboard
What still needs polishing (not blocking)
/dashboardreturns 404 for unauthenticated users instead of redirecting to/sign-in(Clerk v7's intentionalauth.protect()behavior; one-line fix later)- Real end-to-end review smoke (sign up → create project → upload PDF → run review) not yet performed against the live deploy