Compare 6 chunking strategies side-by-side — and actually see why chunking matters.

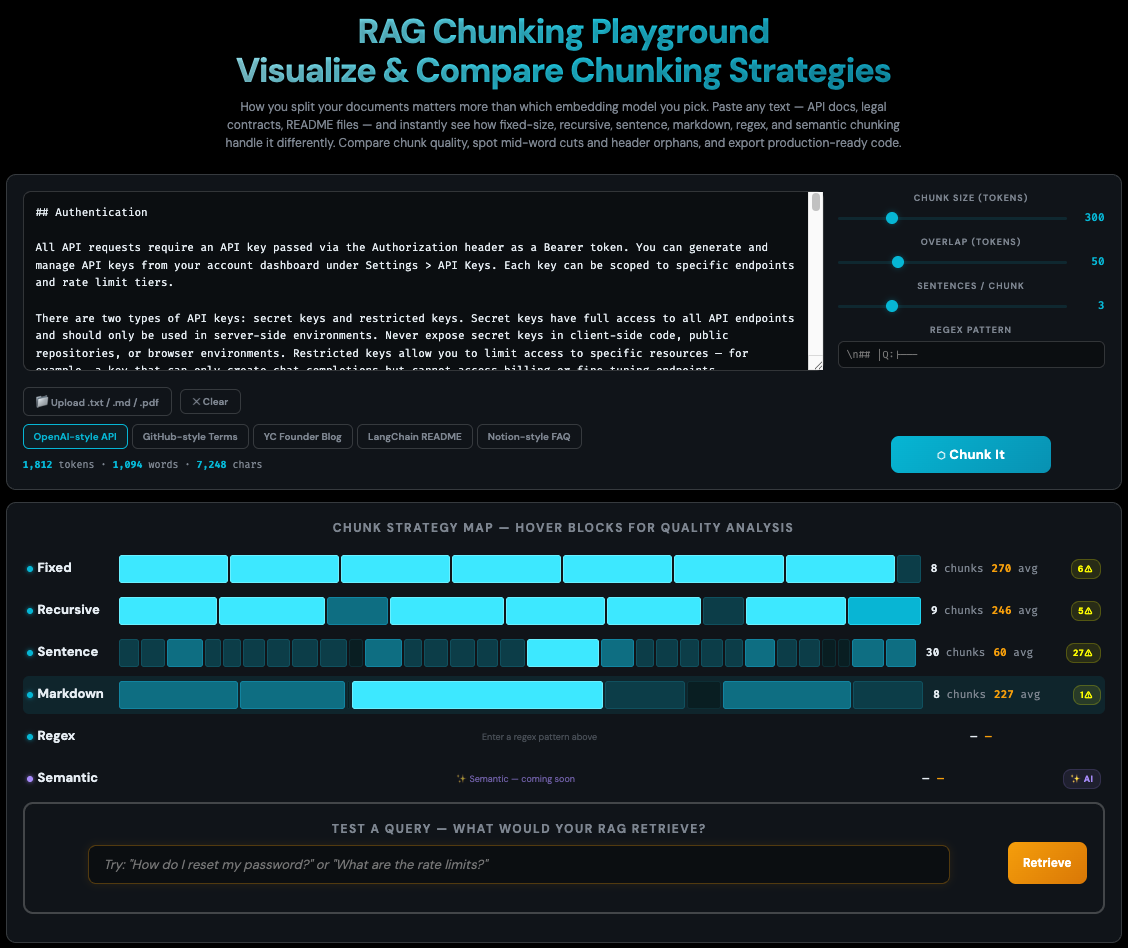
Most RAG tutorials skip chunking or say "just use 512 tokens." But chunking strategy matters!
We built this because:
- ❌ Fixed-size cuts words mid-sentence
- ❌ Recursive orphans headers from content
- ❌ Semantic costs 10x more and isn't always better
You need to SEE the difference, not guess.
- Chunking can change retrieval accuracy by 10–30%
- Most people use bad defaults
- This tool lets you see the difference instantly
✅ 6 strategies compared: Fixed, Recursive, Sentence, Markdown, Regex, Semantic (coming soon)
✅ Live quality grading: Green (clean), Yellow (warnings), Red (broken chunks)
✅ Visual diff view: Hover any chunk to highlight it in the doc
✅ Cost calculator: Embedding + context window costs for OpenAI/Cohere
✅ Export code: LangChain, LlamaIndex, Haystack snippets
✅ Zero backend: Runs 100% client-side (except semantic uses OpenAI API)
Visit aiagentsbuzz.com/tools/rag-chunking-playground
git clone https://github.com/ai-agents-buzz/rag-chunking-playground
cd rag-chunking-playground
open index.htmlNo build step. No dependencies. Just open index.html in your browser.
Architecture:
- Pure vanilla JavaScript (no frameworks)
- Tokenization via GPT-3 estimation (1 token ≈ 4 chars)
- All processing happens client-side
- Coming Soon: Semantic chunking via OpenAI Embeddings API
Strategy Comparison:
| Strategy | Quality | Speed | Cost | Best Use Case |
|---|---|---|---|---|
| Fixed-size | 🟡 54% | ⚡⚡⚡⚡ | 💲 | Simple docs |
| Recursive | 🟢 69% | ⚡⚡⚡ | 💲 | Code + markdown |
| Sentence | 🟢 72% | ⚡⚡ | 💲 | Clean text |
| Markdown | 🟢 76% | ⚡⚡⚡ | 💲 | Structured docs |
| Semantic | 🟢 87% | ⚡ | 💲💲💲 | High-accuracy RAG |
Full strategy guide with benchmarks →
See exactly where each strategy cuts your text, with hover tooltips
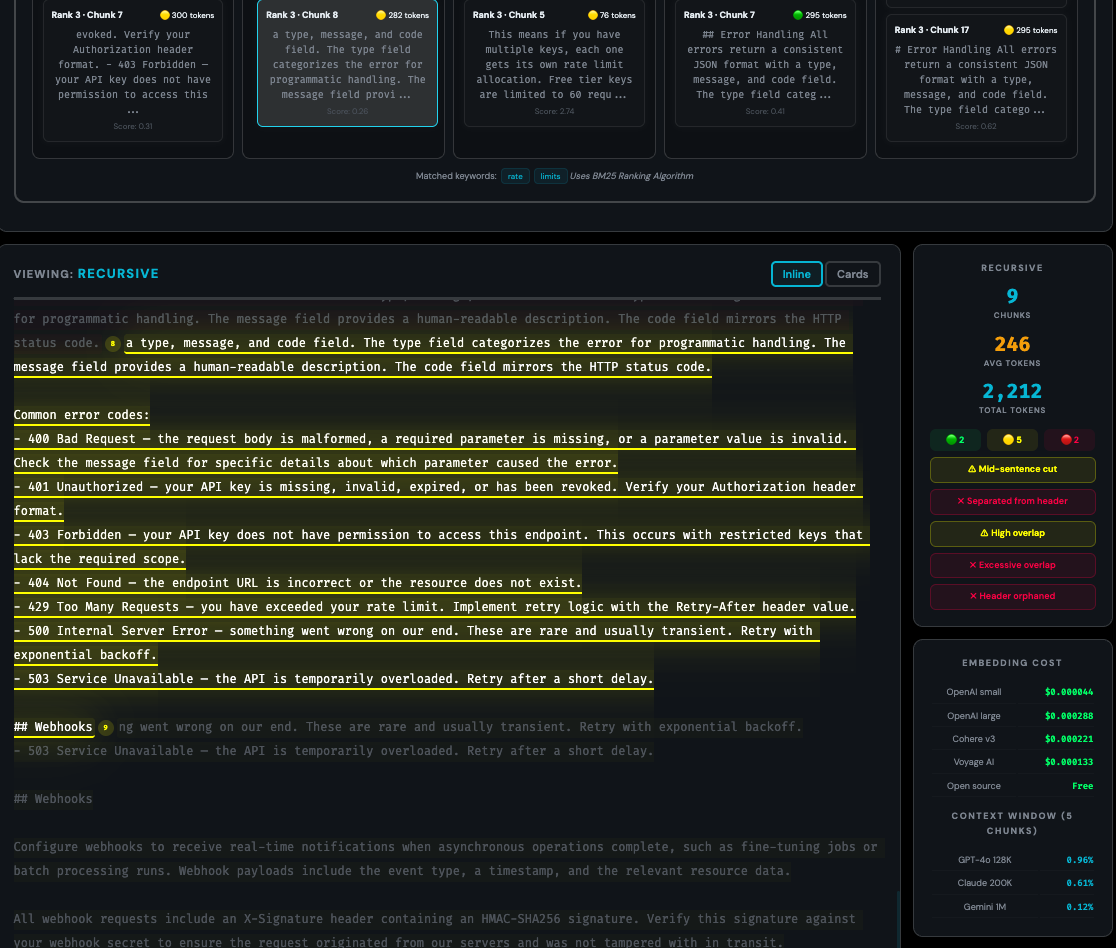
Test which chunks get retrieved for a sample query using BM25 ranking
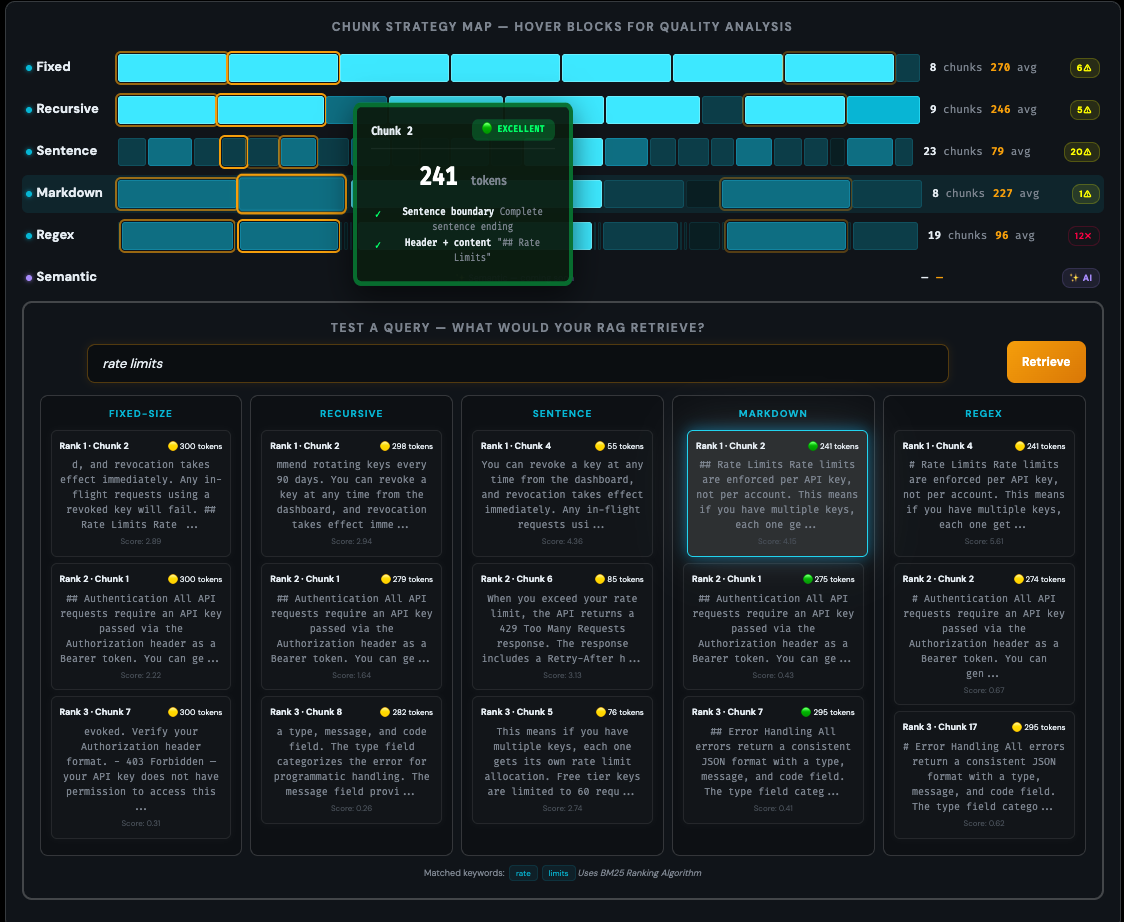
1. Debug why your RAG returns garbage
Paste your actual docs → see if chunks break mid-thought
2. Choose the right strategy for your content
Compare on your real data, not synthetic examples
3. Estimate costs before building
See embedding + context costs for 1M docs
4. Teach/learn RAG fundamentals
Visual, interactive beats reading theory
- Frontend: Vanilla JavaScript (no frameworks)
- Styling: Custom CSS
- Fonts: DM Sans, Fira Code, Caveat
- Query: Uses BM25 for query selection
- PDF Support: PDF.js
- Token Counting: GPT-3 estimation (1 token ≈ 4 chars)
- Coming Soon: OpenAI API for semantic chunking
Found a bug? Have a new strategy idea? PRs welcome!
Ideas for contributions:
- Add Anthropic Claude token counting
- Support PDF/DOCX upload
- Add "hybrid" strategy (semantic + recursive)
- Multilingual support
MIT License - Created by AI Agents Buzz • March 2026
Attribution: Keep the footer attribution and link back to the original tool.
Full RAG Chunking Strategy Guide - 4000+ words with benchmarks, decision framework, and real data
Buy vs. Build Calculator - Should you build a custom agent or buy one off the shelf?
AI Agents Directory - 300+ AI agents reviewed
⭐ Star this repo if it helped you build better RAG systems!
Report issues in the GitHub Issues tab
**Built with ❤️ **