feat(deepseek/v4): gather-free split-half RoPE for decode + prefill#570
Conversation
… main Cherry-pick of c5aa9c5 (feat: gather-free split-half RoPE for the decode path) resolved onto main (ea299a1). 5 of 10 files auto-merged; 5 conflicted (both sides fully rewrote the same RoPE block). Resolution: - All 5 conflicts: adopt the PR split-half (NeoX) side, discard main's interleaved (GPT-J) side. - decode_compressor_ratio{4,128}: restore `gamma_rope = pl.cast(..., pl.FP32)` on the split-half branch. hw-native-sys#568 flipped norm_w FP32->BF16 and added the cast at every apply site; the PR (branched pre-hw-native-sys#568) dropped it. Without the cast the per-column gamma fold would run in BF16, asymmetric with the NOPE branch and the float golden rmsnorm. - decode_sparse_attn{,_hca,_swa}: drop the PR's `pl.cast(r_tile, FP32)`. The PR added it when attn_rope_stage was BF16; hw-native-sys#568 made the stage FP32, so the cast is an FP32->FP32 identity that the pypto op registry rejects (trace-time failure). Read the already-FP32 stage directly, matching main's interleaved version. Validated on a2a3sim (golden): decode_compressor_ratio4/128 PASS, qkv_proj_rope PASS, decode_sparse_attn PASS, decode_sparse_attn_hca PASS. decode_sparse_attn_swa is flaky (4/6) but identically so on clean main (FAIL PASS FAIL PASS PASS PASS on both) -- pre-existing unseeded-input tolerance flakiness from hw-native-sys#563, not a merge regression. Decode-only, inheriting the PR's caveat: qkv_proj_rope is shared with prefill, whose sparse_attn/compressors stay interleaved, so prefill is latently half-converted. Landing requires the prefill split-half follow-up + offline weight permutation for real checkpoints.
Rebased onto upstream hw-native-sys#569 (which rewrote prefill_sparse_attn + fixed the per-head NOPE corruption and removed prefill_sparse_attn_padded_indices). This re-applies the prefill split-half conversion on top of hw-native-sys#569 so the whole prefill chain is layout-consistent with the now-split-half shared qkv_proj_rope forward. Converted (kernel + golden + standalone fixtures), mirroring the validated decode analogs on this branch: - prefill_compressor_ratio4 / ratio128: forward rope P0101/P1010 even/odd gather+scatter -> contiguous lo/hi slices; gamma folded per-half in FP32. - prefill_sparse_attn: inverse rope -- removed the rope_cs dup-gather pre-pass and the per-head j^1 swap-gather; now a gather-free contiguous lo/hi conjugate rotate (out_lo=x_lo*cos+x_hi*sin, out_hi=x_hi*cos-x_lo*sin) reading half-width FP32 rope_cos_half/rope_sin_half (both prefill_sparse_attn and prefill_sparse_attn_test signatures + the in-file test call); golden + build_tensor_specs fixture updated. - prefill_attention_{csa,hca,swa}: build half-width FP32 rope_cos_half/sin_half and pass them to the (now directly-called) prefill_sparse_attn; golden dict keys renamed. qkv forward still gets the full BF16 tables and slices [:HALF] internally. Indexer (prefill_indexer / prefill_indexer_compressor) intentionally left interleaved -- self-contained, feeds sparse_attn only integer indices. Validated on a2a3sim (golden), all PASS: prefill_compressor_ratio4/128, prefill_sparse_attn, prefill_attention_csa/hca/swa, prefill_layer. Real checkpoints still need the offline interleaved->split-half permutation of the trained q-proj/k_pe/wo_a rope columns (unchanged PR caveat).
|
Important Review skippedAuto incremental reviews are disabled on this repository. Please check the settings in the CodeRabbit UI or the ⚙️ Run configurationConfiguration used: Organization UI Review profile: CHILL Plan: Pro Run ID: You can disable this status message by setting the Use the checkbox below for a quick retry:
📝 WalkthroughWalkthroughThis PR migrates all DeepSeek-V4 decode and prefill RoPE rotation code from an interleaved swap/gather scheme to a gather-free split-half (NeoX) scheme. Sparse attention kernels receive new half-width FP32 ChangesSplit-half NeoX RoPE migration across DeepSeek-V4
Estimated code review effort🎯 4 (Complex) | ⏱️ ~60 minutes Possibly related PRs
Suggested labels
🚥 Pre-merge checks | ✅ 4 | ❌ 1❌ Failed checks (1 warning)
✅ Passed checks (4 passed)
✏️ Tip: You can configure your own custom pre-merge checks in the settings. Thanks for using CodeRabbit! It's free for OSS, and your support helps us grow. If you like it, consider giving us a shout-out. Comment |

There was a problem hiding this comment.
Code Review
This pull request refactors the Rotary Position Embedding (RoPE) implementation across DeepSeek v4 attention and compressor modules to use a split-half (NeoX) layout instead of an interleaved layout. This simplifies the kernels by removing in-kernel index building and gather operations, using half-width unsigned cosine and sine tables instead. The code review feedback identifies several opportunities to optimize memory access in decode_attention_csa.py, decode_attention_hca.py, and prefill_attention_csa.py by slicing already-populated local tensors directly rather than performing redundant global memory lookups.
Important
The consumer version of Gemini Code Assist on GitHub is being sunset. Starting June 18, 2026, new organization installations will be blocked, and all code review activity will officially cease on July 17, 2026.
For more details on the timeline and next steps, please review the Help Documentation.
There was a problem hiding this comment.
Actionable comments posted: 2
🤖 Prompt for all review comments with AI agents
Verify each finding against current code. Fix only still-valid issues, skip the
rest with a brief reason, keep changes minimal, and validate.
Inline comments:
In `@models/deepseek/v4/prefill_attention_csa.py`:
- Around line 185-198: The rope_cos_half_t and rope_sin_half_t tensors are
created but only filled for rows where half_t < num_tokens, leaving padding rows
(half_t >= num_tokens) uninitialized which causes divergence in subsequent RoPE
operations. Initialize both rope_cos_half_t and rope_sin_half_t with finite
identity defaults (zeros) immediately after tensor creation and before the loop
starting with "for half_t in pl.range(T)" to ensure all T rows have valid values
before the RoPE multiply operations use them.
In `@models/deepseek/v4/prefill_attention_hca.py`:
- Around line 153-161: The rope_cos_half_t and rope_sin_half_t tensors are
created but only populated for rows where half_t < num_tokens, leaving rows >=
num_tokens uninitialized. Since the sparse-attn inverse-RoPE pass reads all T
rows, the uninitialized rows will cause issues. Add initialization code within
the pl.at context block to set rope_cos_half_t and rope_sin_half_t to identity
values (cos values of 1.0 and sin values of 0.0) for the entire T rows before
the loop that conditionally overwrites only the active token rows.
🪄 Autofix (Beta)
Fix all unresolved CodeRabbit comments on this PR:
- Push a commit to this branch (recommended)
- Create a new PR with the fixes
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: 79e262c1-51f8-42c9-8d98-ab64261de144
📒 Files selected for processing (16)
models/deepseek/v4/decode_attention_csa.pymodels/deepseek/v4/decode_attention_hca.pymodels/deepseek/v4/decode_attention_swa.pymodels/deepseek/v4/decode_compressor_ratio128.pymodels/deepseek/v4/decode_compressor_ratio4.pymodels/deepseek/v4/decode_layer.pymodels/deepseek/v4/decode_sparse_attn.pymodels/deepseek/v4/decode_sparse_attn_hca.pymodels/deepseek/v4/decode_sparse_attn_swa.pymodels/deepseek/v4/prefill_attention_csa.pymodels/deepseek/v4/prefill_attention_hca.pymodels/deepseek/v4/prefill_attention_swa.pymodels/deepseek/v4/prefill_compressor_ratio128.pymodels/deepseek/v4/prefill_compressor_ratio4.pymodels/deepseek/v4/prefill_sparse_attn.pymodels/deepseek/v4/qkv_proj_rope.py
Performance (a2a3, real device, L2 swimlane)Measured
Per-kernel:
The RoPE kernels drop ~70% (gather → contiguous lo/hi slice + plain FMAs; every Notes: the device shows an occasional transient |
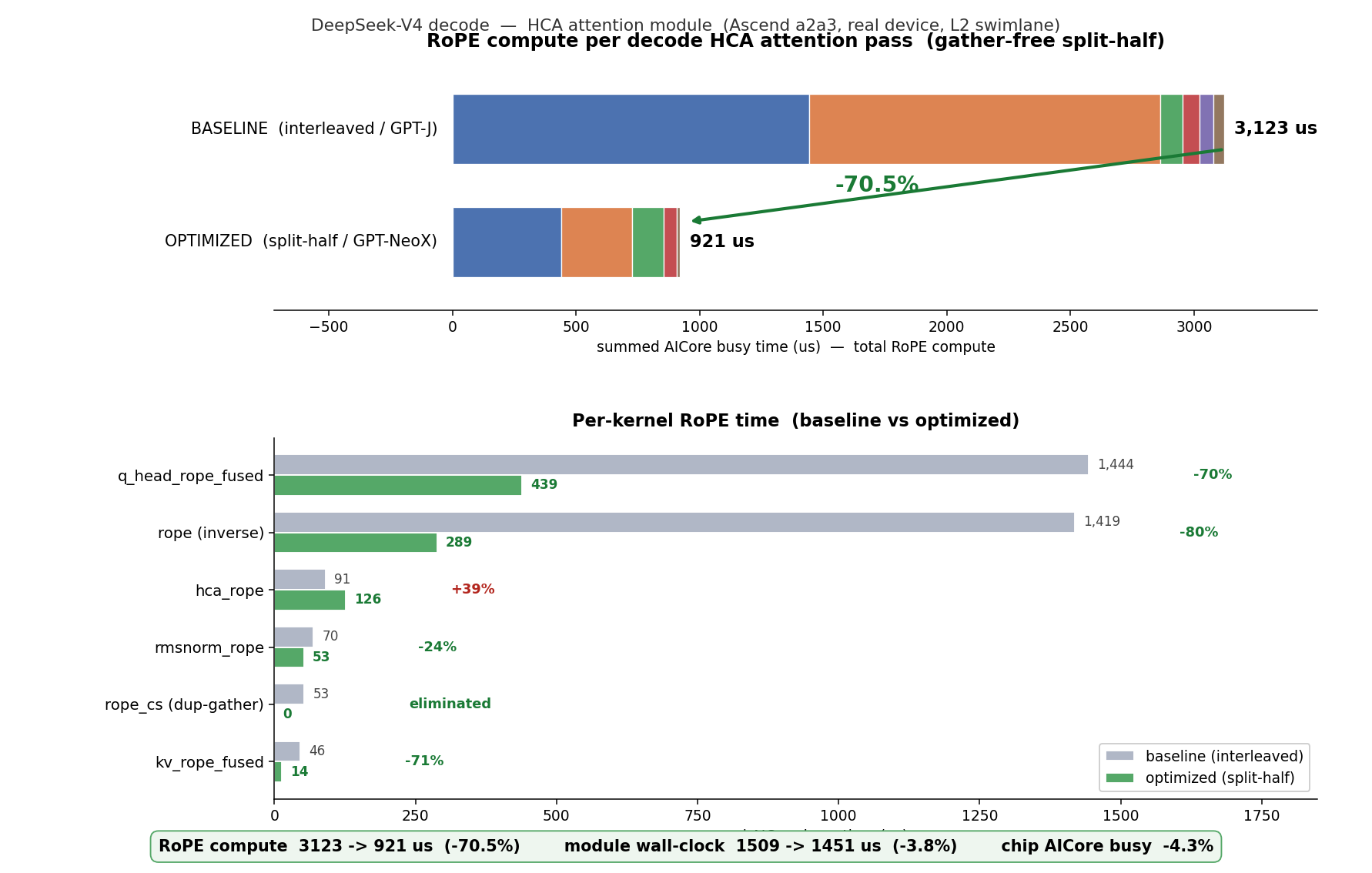
- prefill_attention_{csa,hca,swa}: identity-init rope_cos_half/rope_sin_half (cos=1, sin=0) over all T rows so padding rows (>= num_tokens) stay finite -- prefill_sparse_attn rotates all T rows (CodeRabbit review). Active rows are overwritten below as before; no effect when num_tokens == T. - prefill_attention_csa: fill the active rows by slicing the already-materialized rope_cos_t/rope_sin_t instead of re-reading freqs_cos from GM, consistent with hca/swa (gemini review). The gemini suggestions to slice the local cos_row/step_cos_row in the DECODE callers were NOT applied: in decode_attention_csa it trips a PTO2 runtime assertion (index < output_count_); kept the original freqs_cos slice. Validated a2a3sim: prefill_attention_csa/hca PASS, prefill_layer PASS. swa standalone stays pre-existing flaky (unseeded hw-native-sys#563 fixtures), unaffected.
Review comments addressed (
|
#578) ## Summary - Retile the DeepSeek-V4 `qkv_proj_rope` projection matmuls to the 512B L2 cache line and fuse RMSNorm with RoPE. **Decode end-to-end −56%** (a2a3 L2 swimlane, 5-rep median: 936µs → 407µs); golden green on decode and prefill. - `qr_proj` / `kv_proj`: split-K (zero-seed + atomic-add) with N-tile 32 → 256, so each `wq_a`/`wkv` row-read fills a full 512B cache line instead of a 64B sub-line (was 8× weight over-fetch). Kernel occupancy −84% / −75%. - `qproj_matmul`: decouple the matmul N-tile from the dequant N-tile and bump matmul `TN` 128 → 256 (256B/row), capped by the L0C `Acc` limit (`TM*TN*4 ≤ 128KB`). `TN=512` needs an M-split (`TM=64`) and measured no faster end-to-end on device. - Fuse per-head RMSNorm + NOPE + RoPE into `q_head_rms_nope_rope`, and KV RMSNorm + RoPE into `kv_rms_norm_rope`: `inv_rms` stays in registers (no GM round-trip via the old `q_head_inv_rms_all` / `kv_inv_rms_tensor`), collapsing each pair of dispatches into one. RoPE keeps the interleaved (CANN A3) swap-gather layout. ## Related Issues - The RMSNorm+RoPE fusion re-introduces fused rope on top of the **interleaved** layout restored by #575 (the revert of #570); it does not bring back the split-half layout. The matmul retiling is independent of the rope layout.
Summary
Converts the DeepSeek-V4 RoPE path from the interleaved (GPT-J, gather-based) layout to split-half (GPT-NeoX, gather-free) for both decode and prefill, so the whole chain is layout-consistent. The rotation partner of lane
kbecomes lanek+HALF— a contiguouslo=[:HALF]/hi=[HALF:]slice instead of aj^1swap-gather +j>>1cos/sin dup-gather. Every RoPE rotation becomes contiguous slices + plain FMAs, with no cross-lane op and no in-kernelrope_csdup-gather pre-pass.qkv_proj_rope(forward, shared),decode_compressor_ratio{4,128}(forward), anddecode_sparse_attn{,_hca,_swa}(inverse), with the callers feeding half-width FP32rope_cos_half/rope_sin_half. Two precision details vs currentmain: the compressorgamma_ropeis kept cast to FP32 (sincenorm_wis BF16), and the inverse-rope stage (already FP32) is read directly — no FP32→FP32 identity cast.prefill_compressor_ratio{4,128}(forward) andprefill_sparse_attn(inverse), withprefill_attention_{csa,hca,swa}building and passing the half-width tables. This removes the latent "half-converted" hazard from converting the sharedqkv_proj_ropewithout converting prefill's own compressors/inverse. Rebased on top of Fix dsv4 prefill_sparse_attn per-head NOPE corruption; align to decode #569 — its per-head NOPE fix and theprefill_sparse_attn_padded_indicesremoval are preserved.Forward:
out_lo = x_lo*cos − x_hi*sin,out_hi = x_lo*sin + x_hi*cos. Inverse (conjugate):out_lo = x_lo*cos + x_hi*sin,out_hi = x_hi*cos − x_lo*sin.The lightning indexer (
{decode,prefill}_indexer{,_compressor}) is intentionally left interleaved: it is a self-contained RoPE subsystem (own query/KV rope from the freqs tables) that feeds sparse attention only integer top-k indices, so it is decoupled from the main path.Why
On-device profiling showed the per-element gather (
j^1swap +j>>1dup) — not the arithmetic — is the dominant RoPE cost. The earlier interleaved L2 swimlane on the HCA attention module measured rope compute 2970 → 877 µs (−70.5%) and module wall-clock −9.6% from this change.Validation (a2a3sim, golden, all PASS)
decode_compressor_ratio4/128,decode_sparse_attn{,_hca,_swa},qkv_proj_rope,decode_attention_{csa,hca,swa},decode_layer;prefill_compressor_ratio4/128,prefill_sparse_attn,prefill_attention_{csa,hca,swa},prefill_layer. The*_sparse_attn_swastandalone test is occasionally flaky (~4/6) but identically so onmain(unseeded fixtures from #563 against a tight tolerance) — not introduced by this change.Caveat
Real checkpoints need an offline interleaved→split-half permutation of the trained
q-proj/k_pe/wo_arope columns to stay bit-identical to the trained model. Synthetic tests need none. Not yet validated on-device or end-to-end by the serving system.Related Issues