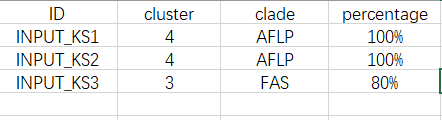
fast identify Animal FAS Like PKS (AFPK)s. It utilizes the t-Distributed Stochastic Neighbor Embedding (t-SNE) technique for dimensionality reduction, which is based on the alignment scores to a series of ketosynthase related Hidden Markov Model (HMM). The HDBSCAN clustering method is then employed to identify the possible AFPK clusters for each protein sequence input.
- Bash
- R >= 3.2
- R packages: ggplot2, Rtsne, getopt, dbscan
- To install R packages just run R environment and execute command: install.packages(c("ggplot2","Rtsne","getopt","dbscan"))
- HMMER 3.3.2
- prodigal (if input is DNA file)
AFPK_finder was tested on MacOs 11, Ubuntu 16.04 and Ubuntu 18.04.
no installation needed
At first, add the folder with executables to your PATH variable.
git clone https://github.com/linzhenjian/AFPK_finder.git
cd AFPK_finder
chmod 771 *
export PATH="/path_to_AFPK_FInder/":$PATH
then run "run_AFPK_finder.sh -p testing_data/ar-clade1.fa -o output -t 16 " or "run_AFPK_finder.sh -d DNA_KS.fa -o output -t 16 "
running time for a input with 100 seqence is about 5 min in a normal desktop computer
ideal inputs will be intact protein sequences of KS domain of iterative PKSs, they can be generated by antiSMASH, interpro..., keeping the input sequence number <100 will give better resolution in output ploting figure. we did find that truncated KS sequence input will cause misidentificaton.
this plot shows the INPUT_KSs (purple) are adjacent to AFPKs (light blue), so the INPUT_KSs are identified as AFPKs.
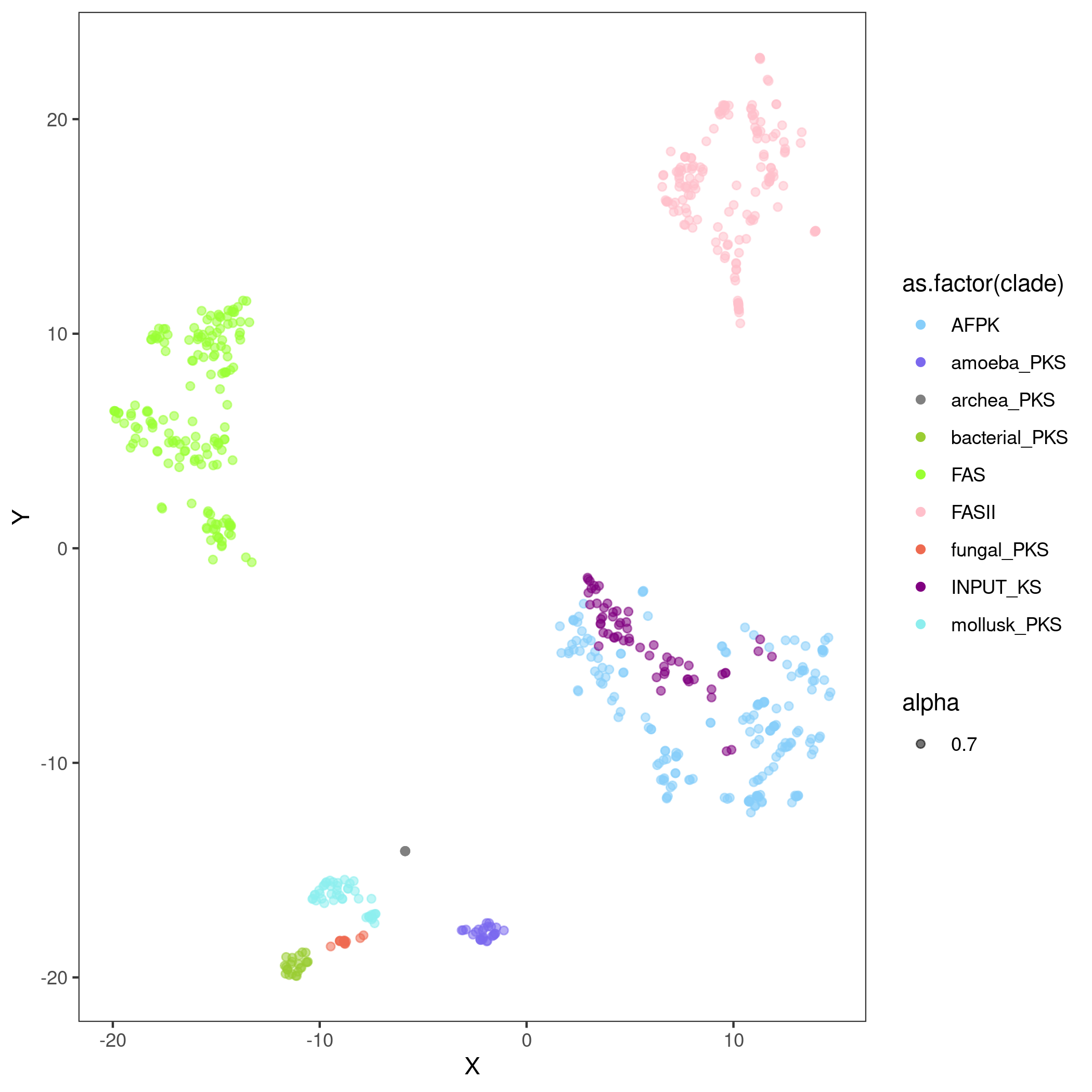
output table example: it tells that INPUT_KS1 is clustered in cluster 4, cluster 4 contains 100% of the training AFPKs