



Forensic source-code comparison tool for IP litigation and code audit.
Diffinite compares two directories of source code and produces professional PDF/HTML reports with syntax-highlighted side-by-side diffs. It uses Winnowing fingerprints (Schleimer et al., 2003 — the algorithm behind Stanford MOSS) for N:M cross-matching to detect code reuse even across renamed, split, or merged files.
Design Principle: Diffinite reports how similar and where similar. It does not classify the type of copying — that is the expert witness's job.
The recommended way to use Diffinite on Windows is through the VS Code extension, which bundles an embedded Python runtime — no separate Python installation required. On macOS/Linux the extension runs against a system Python (pip install diffinite, then set diffinite.pythonPath) — see Platform Support.
- Visual directory picker — Select two directories and configure options via a GUI panel
- Real-time progress bar — Live percentage tracking during analysis
- Pre-analysis time estimation — Scans file sizes upfront and estimates Simple/Deep mode duration
- Dynamic CPU calibration — Benchmarks Phase 1 performance to refine Phase 2 time predictions
- OOM defense — Warns before analyzing file pairs exceeding 5MB
- Interactive tree viewer — Review matched pairs and selectively export
- One-click PDF/HTML export — With Bates numbering, page numbers, and filename annotations
cd vscode-extension
npm install
npm run compile
# Press F5 in VS Code to launch Extension Development Hostpip install diffiniteOr from source:
git clone https://github.com/nash-dir/diffinite.git
cd diffinite
pip install -e ".[dev]"Requirements: Python ≥ 3.10
Dependencies: RapidFuzz, Pygments, xhtml2pdf, pypdf, reportlab, charset-normalizer
| Component | Windows | Linux | macOS |
|---|---|---|---|
CLI (pip install diffinite) |
✅ supported | ✅ tested in CI | ◯ expected to work (pure Python; not in CI) |
| VS Code extension | ✅ bundles an embedded Python runtime; primary tested target | △ via system Python (pip install diffinite + diffinite.pythonPath); not officially tested |
△ same as Linux; not officially tested |
The published VS Code extension is packaged for Windows (win32-x64) and ships the embedded runtime. On macOS/Linux, use the CLI directly, or point the extension at your own interpreter via the diffinite.pythonPath setting. The CLI itself is pure Python and platform-independent.
# Compare two directories → PDF report
diffinite original/ suspect/ -o report.pdf
# With comment stripping and Bates numbering (forensic use)
diffinite original/ suspect/ -o report.pdf \
--strip-comments --bates-number --page-number --filename
# HTML report (single self-contained file, opens in browser)
diffinite original/ suspect/ --report-html report.htmlDiffinite runs a two-stage pipeline:
- Fuzzy name matching — Pairs files across
dir_aanddir_busing RapidFuzz string similarity (configurable threshold). - Comment stripping — Optionally removes comments using a 6-state finite state machine parser supporting 30+ file extensions.
- Side-by-side diff — Computes line-by-line (or word-by-word) diffs using Python's
difflib.SequenceMatcherwithautojunk=True, a heuristic that drops high-frequency lines to speed up matching on large files (SequenceMatcheritself remains worst-case quadratic). - Report generation — Renders syntax-highlighted HTML diffs via Pygments, then converts to PDF with xhtml2pdf.
- Winnowing fingerprint extraction — Extracts position-independent code fingerprints using the Winnowing algorithm (K-gram → rolling hash → window selection).
- Inverted index construction — Builds a hash-to-file mapping for all B-directory fingerprints.
- Jaccard similarity computation — For each A-file, queries the index to find all B-files sharing fingerprints, then computes Jaccard similarity
|A∩B| / |A∪B|. - Cross-match reporting — Appends an N:M similarity matrix to the report, showing which files from A are similar to which files in B.
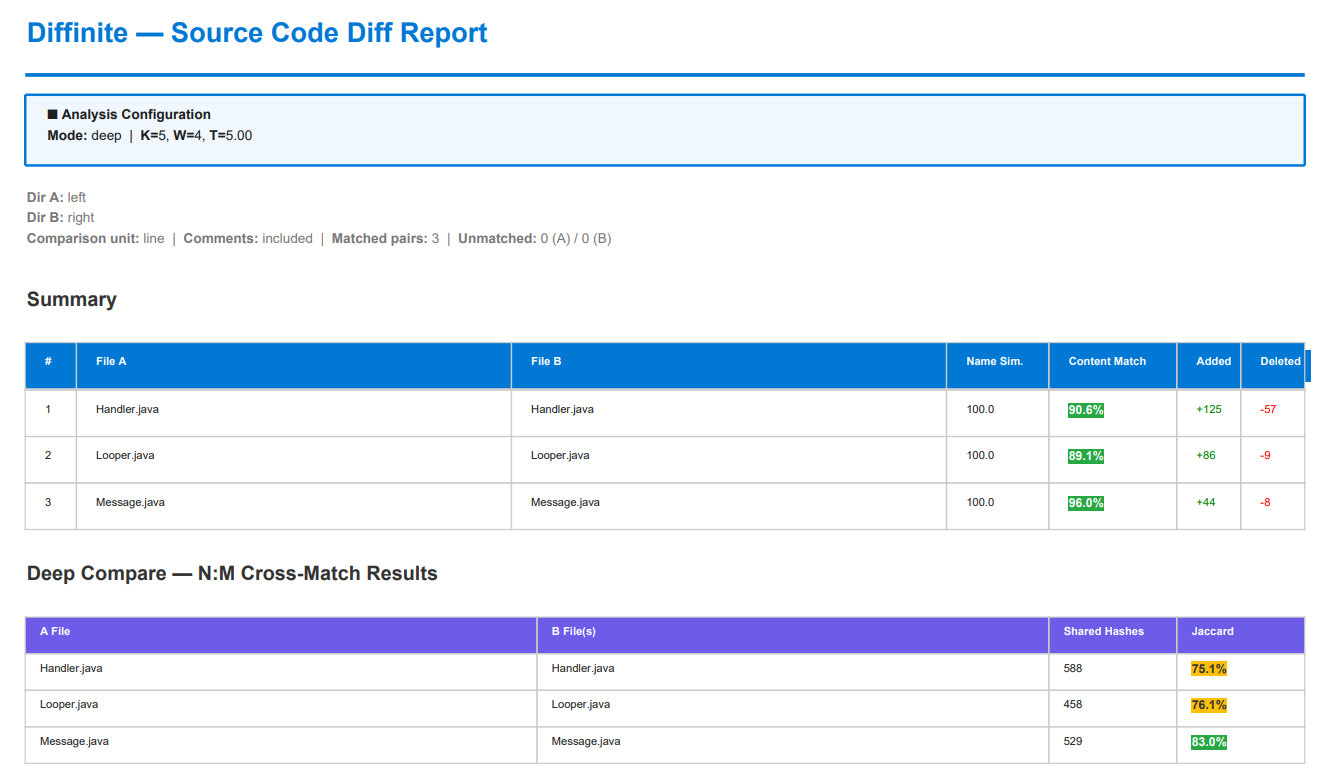
The cover page contains a summary table for each matched file pair:
| Column | Description |
|---|---|
| File A / File B | Matched file paths |
| Name Sim. | Fuzzy filename similarity score (0–100) |
| Content Match | difflib.SequenceMatcher.ratio() — proportion of matching content. 1.0 = identical. |
| Added / Deleted | Number of lines (or words) added to or deleted from File A to produce File B. |
Each matched pair gets a side-by-side diff page with:
- Green highlight — Lines present only in File B (additions)
- Red highlight — Lines present only in File A (deletions)
- Yellow highlight — Lines changed between A and B; in
--by-wordmode the changed words within are further marked (removed words struck through, added words bold) - Purple highlight — Lines moved from this position (
--detect-moved) - Blue highlight — Lines moved to this position (
--detect-moved) - No highlight — Identical lines (with configurable context folding)
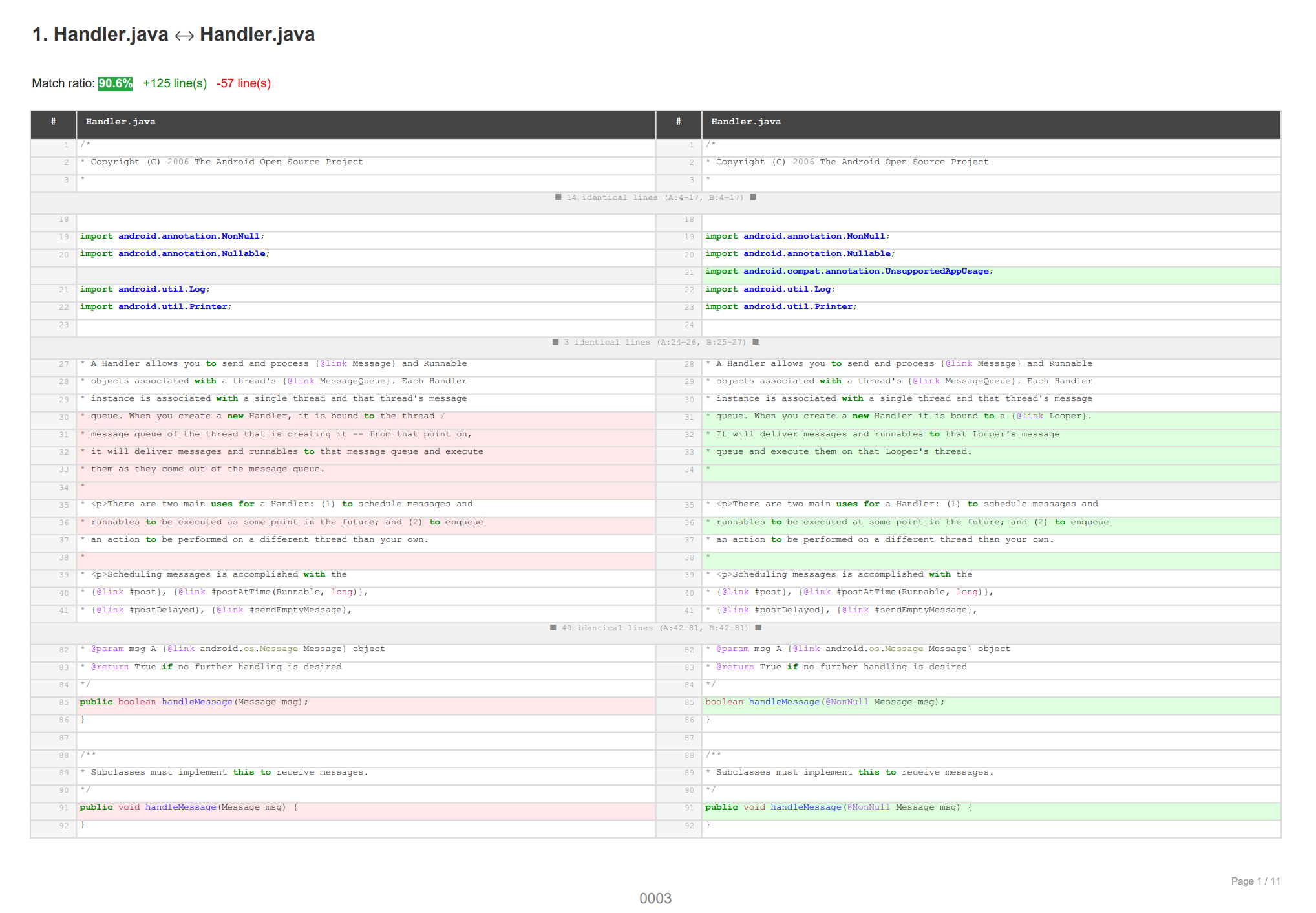
When running in deep mode (default), the report includes an N:M cross-matching table:
| Column | Description |
|---|---|
| File A | Source file from directory A |
| Matched Files (B) | All files from directory B that share fingerprints above the Jaccard threshold |
| Shared Hashes | Count of Winnowing fingerprints the file pair has in common |
| Jaccard | ` |
Jaccard similarity is a well-defined set metric. Its interpretation depends on the domain, code size, and language. Diffinite reports the raw value without attaching qualitative labels.
| Option | Annotation | Position |
|---|---|---|
--page-number |
Page 3 / 47 |
Bottom-right |
--file-number |
File 2 / 12 |
Bottom-left |
--bates-number |
TEST-000003-CONF |
Bottom-center |
--filename |
com/example/Foo.java |
Top-right |
dir_a Path to the original source directory (A)
dir_b Path to the comparison source directory (B)
| Option | Default | Description |
|---|---|---|
--mode {simple,deep} |
deep |
simple = 1:1 file matching only. deep = 1:1 + N:M Winnowing cross-matching. |
| Option | Description |
|---|---|
--report-pdf PATH (alias -o) |
Generate a merged PDF report. Defaults to report.pdf when no --report-* flag is given. |
--report-html PATH |
Generate standalone HTML report (single file, no external deps) |
--report-md PATH |
Generate Markdown summary report |
--report-json PATH |
Generate machine-readable JSON report (used by VS Code extension) |
--no-merge |
Generate individual PDFs per file instead of one merged PDF |
--preserve-tree / --no-preserve-tree |
Preserve directory tree structure in individual output (default: on) |
| Option | Default | Description |
|---|---|---|
--strip-comments |
off | Strip comments before comparison (6-state FSM parser, 30+ extensions) |
--by-word |
off | Compare by word instead of by line |
--squash-blanks |
off | Collapse runs of 3+ blank lines. |
--threshold N |
60 |
Fuzzy file-name matching threshold (0–100). Lower = more aggressive matching. |
--collapse-identical |
off | Fold unchanged code blocks (3 context lines around each change) |
--detect-moved |
off | Detect moved code blocks and highlight with distinct colors |
--encoding ENC |
auto |
Force file encoding (e.g. euc-kr, utf-8). Default: auto-detect via charset-normalizer. |
| Option | Default | Description |
|---|---|---|
--k-gram N |
5 |
K-gram size for Winnowing. Larger K = fewer but more specific fingerprints. (Schleimer 2003, §4.2) |
--window N |
4 |
Winnowing window size. Guarantees detection of any shared sequence ≥ K+W−1 = 8 tokens. |
--threshold-deep N |
5 |
Minimum Jaccard similarity (percent, on a 0–100 scale) to include in results. Below 5% is considered noise. |
--normalize |
off | Normalize identifiers → ID, literals → LIT before fingerprinting. Improves Type-2 clone detection (renamed variables). |
--workers N |
4 |
Number of parallel worker processes for diff rendering and fingerprint extraction. |
| Option | Default | Description |
|---|---|---|
--no-autojunk |
off | Disable SequenceMatcher's autojunk heuristic. Treats all tokens equally — slower but more precise for forensic analysis. |
--max-index-entries N |
10,000,000 |
Memory cap for inverted index. Prevents OOM on large corpora. ~800MB at 10M entries. |
--max-file-size N |
10.0 |
Files larger than this (MB) bypass the in-memory text decode and fall back to a SHA-256 hash comparison (reported as match/no-match rather than a line diff). Prevents OOM/CPU lock on large binary/generated files. |
--hash |
off | Embed SHA-256 evidence integrity hashes for all analyzed files in the report. |
--uncompared-files {inline,separate,none} |
inline |
Control how unmatched files are displayed: inline in the main report, written to a separate *_uncompared.txt file, or omitted. |
| Option | Description |
|---|---|
--page-number |
Show Page n / N at the bottom-right |
--file-number |
Show File n / N at the bottom-left |
--bates-number |
Stamp sequential Bates numbers at the bottom-center |
--bates-prefix TEXT |
Bates number prefix (e.g. PLAINTIFF-). Combined as: {prefix}{number}{suffix} |
--bates-suffix TEXT |
Bates number suffix (e.g. -CONFIDENTIAL) |
--bates-start N |
Starting Bates number (default: 1). Useful for continuing numbering across reports. |
--filename |
Show filename at the top-right |
# Full forensic report with all annotations
diffinite plaintiff_code/ defendant_code/ -o exhibit_A.pdf \
--strip-comments \
--bates-number --bates-prefix=CASE2026- --bates-suffix=-CONFIDENTIAL \
--bates-start 1 --page-number --file-number --filename \
--collapse-identical --detect-moved --hash# HTML report for browser viewing (no PDF dependency issues)
diffinite vendor_v1/ vendor_v2/ --report-html audit.html --strip-comments# Detect renamed-variable copies
diffinite original/ suspect/ -o report.pdf \
--normalize --no-autojunk --strip-comments# 1:1 matching only — faster for quick comparisons
diffinite dir_a/ dir_b/ --mode simple -o quick_report.pdf# Generate all formats at once
diffinite dir_a/ dir_b/ \
--report-pdf report.pdf \
--report-html report.html \
--report-md report.md \
--report-json report.json# Larger K-gram = fewer false positives, may miss short matches
diffinite dir_a/ dir_b/ --k-gram 7 --window 5
# Lower Jaccard threshold = show weaker matches (0–100 scale; default 5)
diffinite dir_a/ dir_b/ --threshold-deep 2
# Stricter file name matching
diffinite dir_a/ dir_b/ --threshold 80The --strip-comments flag removes comments using a 6-state finite state machine parser:
| Extensions | Comment Styles |
|---|---|
.py |
# line comments |
.js, .ts, .jsx, .tsx |
// line, /* block */ |
.java, .c, .cpp, .h, .cs, .go, .rs, .kt, .scala |
// line, /* block */ |
.html, .xml, .svg, .htm |
<!-- block --> |
.css, .scss, .less |
/* block */ |
.sql |
-- line, /* block */ |
.rb |
# line |
.sh, .bash, .zsh |
# line |
.lua |
-- line, --[[ block ]] |
.r |
# line |
String and triple-quoted literals (including Python docstrings), template literals, and regex literals are deliberately preserved, not stripped — they are recognized only so that comment markers appearing inside them (e.g.
//inside a string) are not mistaken for comments.
diffinite/
├── src/diffinite/
│ ├── cli.py # CLI entry point & argument parsing
│ ├── pipeline.py # Orchestration (simple/deep modes, parallel rendering)
│ ├── collector.py # File collection & fuzzy name matching
│ ├── parser.py # 6-state comment stripping FSM
│ ├── differ.py # Diff computation, moved-block detection & HTML rendering
│ ├── fingerprint.py # Winnowing fingerprint extraction
│ ├── deep_compare.py # N:M cross-matching (inverted index + Jaccard)
│ ├── evidence.py # SHA-256 integrity hashing & manifest generation
│ ├── models.py # Data classes (DiffResult, DeepMatchResult, etc.)
│ ├── pdf_gen.py # PDF/HTML report generation (xhtml2pdf)
│ └── languages/ # Per-language comment specs (30+ extensions)
├── vscode-extension/
│ ├── src/ # TypeScript extension source
│ │ ├── extension.ts # Extension activation & command registration
│ │ ├── compareCommand.ts # Directory selection, time estimation, pipeline orchestration
│ │ ├── dirScanner.ts # Pre-analysis file scanning & OOM heuristic
│ │ ├── runner.ts # Python backend spawner with progress bar integration
│ │ ├── optionsPanel.ts # GUI options webview (mode, comments, Bates, etc.)
│ │ ├── treeViewer.ts # Interactive matched-pair tree for selective export
│ │ └── resultViewer.ts # HTML report preview inside VS Code
│ ├── bin/python/ # Embedded Python 3.12 runtime (gitignored)
│ └── package.json
├── example/ # Benchmark datasets (see below)
├── pyproject.toml
├── LICENSE # Apache 2.0
└── NOTICE
Download the example datasets first, then run the benchmarks yourself:
python example/download_examples.py # download all datasets
python example/download_examples.py --dataset aosp # or download onePre-generated benchmark reports (Markdown) are in example/benchmark/.
Why this dataset: The Oracle v. Google case is the landmark SSO (Structure, Sequence, Organization) copyright dispute. Google's Android reimplemented Java API declarations. The code bodies are independently written, but the API signatures are necessarily similar.
diffinite example/Case-Oracle/AOSP_Google example/Case-Oracle/OpenJDK_Oracle \
--strip-comments --report-md example/benchmark/case_oracle.md| File | Match (difflib) | Deep Cross-Match (Jaccard) |
|---|---|---|
ArrayList.java |
9.0% | 7.9% |
Collections.java |
4.5% | 23.1% |
List.java |
6.3% | 11.6% |
Math.java |
5.2% | 6.3% |
String.java |
3.3% | 6.8% |
Observation: The line-level Match (difflib) scores stay under 10%, confirming the bodies are independently written. Deep Compare still surfaces shared Winnowing fingerprints — Jaccard 6–23% (highest on Collections.java) — because the API signatures and declarations are necessarily similar. High structural similarity alongside low line-level Match is precisely the SSO pattern at issue in the case: the same interface, independently implemented. Diffinite reports both numbers; interpreting them is the expert's job.
Why this dataset: Eclipse Collections and OpenJDK solve similar problems (collection frameworks) but are developed by different teams with no code sharing. This is the expected baseline for independent work in the same domain.
diffinite example/Case-NegativeControl/Eclipse_Collections example/Case-NegativeControl/OpenJDK \
--strip-comments --report-md example/benchmark/case_negative.md| File A | File B | Match | Deep Cross-Match |
|---|---|---|---|
StringIterate.java |
String.java |
2.4% | — |
FastList.java |
ArrayList.java |
1.5% | — |
Observation: No cross-matches above the 5% Jaccard threshold. This is the correct result — independent projects should show near-zero similarity.
Why this dataset: IR-Plag is a publicly available plagiarism corpus with labeled modification levels (L1=verbatim copy through L6=heavy restructuring).
diffinite example/plagiarism/case-01/original example/plagiarism/case-01/plagiarized \
--normalize --strip-comments --report-md example/benchmark/plagiarism_case01.md| Original | Plagiarized | Jaccard |
|---|---|---|
T1.java |
L2/04/hellow.java |
100.0% |
T1.java |
L1/04/T1.java |
100.0% |
T1.java |
L1/05/HelloWorld.java |
100.0% |
T1.java |
L4/05/hellow.java |
56.2% |
T1.java |
L5/02/Main.java |
38.1% |
T1.java |
L6/07/PrintJava.java |
36.4% |
T1.java |
L6/01/L6.java |
25.0% |
T1.java |
L6/05/HelloWorld.java |
15.4% |
Observation: Jaccard decreases as the plagiarism level increases (L1→L6). Verbatim and lightly-edited copies (L1–L3) score 100%. Heavily restructured copies (L5, L6) still show 15–38% shared fingerprints — well above the negative control baseline.
Why this dataset: Two versions of Android's Handler/Looper/Message framework. Small evolutionary changes between versions.
# Default run, comments included (the configuration shown in the sample image above)
diffinite example/aosp/left example/aosp/right
# With comment stripping (reproduces example/benchmark/aosp.md)
diffinite example/aosp/left example/aosp/right \
--strip-comments --report-md example/benchmark/aosp.md| File | Match — comments included | Match — comments stripped |
|---|---|---|
Handler.java |
90.6% | 88.6% |
Looper.java |
89.1% | 90.0% |
Message.java |
96.0% | 96.3% |
Observation: High Match scores correctly reflect that these are minor revisions of the same codebase — and the scores stay high whether comments are included (the default) or stripped, showing the measurement is robust to that choice. The sample report image at the top of this README uses this dataset with comments included.
Diffinite uses the Winnowing algorithm (Schleimer, Wilkerson, Aiken. "Winnowing: Local Algorithms for Document Fingerprinting." SIGMOD 2003), which also forms the basis of Stanford MOSS.
Pipeline: source → tokenize → K-gram → rolling hash → winnow → fingerprint set
The algorithm provides a density guarantee: any shared token sequence of length ≥ K + W − 1 (default: 8) will always be detected, regardless of its position in the file.
Parameters:
| Parameter | Default | Rationale |
|---|---|---|
K (k-gram) |
5 |
Schleimer 2003 §4.2 recommended range. 5 consecutive tokens per fingerprint unit. |
W (window) |
4 |
Window of 4 fingerprints → minimum detectable sequence = 8 tokens. |
HASH_BASE |
257 |
Standard Rabin hash base (prime). |
HASH_MOD |
2⁶¹ − 1 |
Mersenne prime — efficient modular arithmetic, minimal collision probability. |
- General-purpose tokenizer: Uses a single regex tokenizer for all languages, not language-specific parsers. Accuracy may vary across languages.
- Position-independent: Winnowing fingerprints are order-independent within a window. Code with reordered functions may produce higher similarity than expected.
- No corpus-based analysis: Each comparison is pairwise. There is no built-in corpus-wide frequency weighting (e.g., TF-IDF) to down-weight common idioms.
- Binary and obfuscated code: Not supported. Diffinite operates on source code text only.
- Not a legal opinion: Similarity scores are mathematical measurements, not legal conclusions. Professional review is required before use in any legal proceeding.
See NOTICE for attribution.