_ _ _ _ _ __ _
/ \ __ _ ___ _ __ | |_ / \ _ __ ___ _ __ | (_)/ _(_) ___ _ __
/ _ \ / _` |/ _ \ '_ \| __| / _ \ | '_ ` _ \| '_ \| | | |_| |/ _ \ '__|
/ ___ \ (_| | __/ | | | |_ / ___ \| | | | | | |_) | | | _| | __/ |
/_/ \_\__, |\___|_| |_|\__/_/ \_\_| |_| |_| .__/|_|_|_| |_|\___|_|
|___/ |_|
Sonnet + amp consistently outperforms Sonnet alone on real engineering. Same model. Higher effort. Verified.
Agent Amplifier is a runtime amplification layer for AI coding agents. It installs as five Claude Code hooks and makes your agent reason harder, drift less, and stop when it is actually done -- using deterministic Python, no extra LLM calls, no network.
▶ Watch the 78-second demo on YouTube — dashboard tour, persona picker, real telemetry from 1.71 billion tokens of dogfood sessions.

Every AI coding agent ships the same four failure modes:
- Wrong effort level. Simple prompt gets a 90-second ultrathink. Complex refactor gets a 5-second hot-take. No model auto-tunes effort.
- Goal drift. After ~50 tool calls the agent forgets the original ask and starts riffing on the latest sub-task.
- No convergence signal. The loop keeps "improving" until you kill it or the token budget runs out. Output frequently gets worse.
- Memory amnesia. Each conversation starts from zero. Memory files exist but nothing forces the agent to read them at turn start and write outcomes at turn end.
Agent Amplifier is a small local layer that sits between you and your AI coding agent and fixes all four. Think of it as a coach standing next to a brilliant-but-sloppy intern: same intern, much better output.
Three install paths. Same product, same agent-amp CLI either way — pick whichever fits your workflow.
# Option 1 — pip (recommended for Python-native workflows)
pip install agent-amplifier
# Option 2 — pipx (recommended; isolated venv, no dependency conflicts)
pipx install agent-amplifier
# Option 3 — npm (bootstraps the Python package via pipx under the hood)
npm install -g agent-amplifieragent-amp install claude-code # drops 5 hooks into ~/.claude/settings.json
# restart Claude Code -- doneVerify it works:
agent-amp doctor # environment diagnostics
agent-amp demo "Refactor auth to use JWT" # see before/after envelope
agent-amp report # real telemetry from your sessionsThe npm wrapper requires Python 3.11+ on
PATH(Agent Amplifier is a Python product). Onnpm install, a postinstall script runspipx install agent-amplifier==<version>and wiresagent-amponto your shell. SetAGENT_AMP_SKIP_POSTINSTALL=1to opt out (CI / Docker). All three install paths converge on the same on-disk binary.
| # | Feature | What it does | Source |
|---|---|---|---|
| 1 | Runtime Harness | Runs inside the agent's live loop -- not offline, not post-hoc | kernel.py |
| 2 | Dynamic Effort Router | Classifies prompt complexity into 5 tiers, picks the right thinking budget | effort_router.py |
| 3 | Goal Anchor Protocol | Re-injects your original request every N tool calls to prevent drift | goal_anchor.py |
| 4 | LTI Convergence Detection | Stops the loop when output stabilizes; mathematical termination guarantee | convergence.py |
| 5 | Semantic Modifier Injection | Picks from 97 validated keywords (L99, CRIT, FINISH, OODA, ...) based on task type | semantic_modifiers.py |
| 6 | Cross-Framework Adapters | One kernel, 7 host adapters at v1.0 (see table below) | adapter_base.py |
| 7 | Phase-Aware Prompting | EXPLORE on iteration 0, EXPLOIT mid-run, FINALIZE at the end | phase_prompts.py |
| 8 | Escalating Audit Personas + Custom | 4 built-in personas (senior → security → principal → distinguished AI-safety) with value taglines, plus user-defined personas via UI/CLI with prompt-injection defense | personas.py, custom_personas.py |
| 9 | Cross-Host Memory Plane | Every user gets memory recall at turn start + outcome write at turn end | recall_safety.py |
| 10 | Cost-Bounded Amplification | Hard token ceiling per turn; graceful finalize when budget approaches | token_budget.py |
| 11 | Intelligent Tool Selector | Shortlists relevant tools per turn (Vercel's "drop 80% of tools" finding, automated) | tool_selector.py |
All features are deterministic Python. Zero LLM calls. Zero network. Fail-open: if the amplifier crashes, your agent runs as if it is not installed.
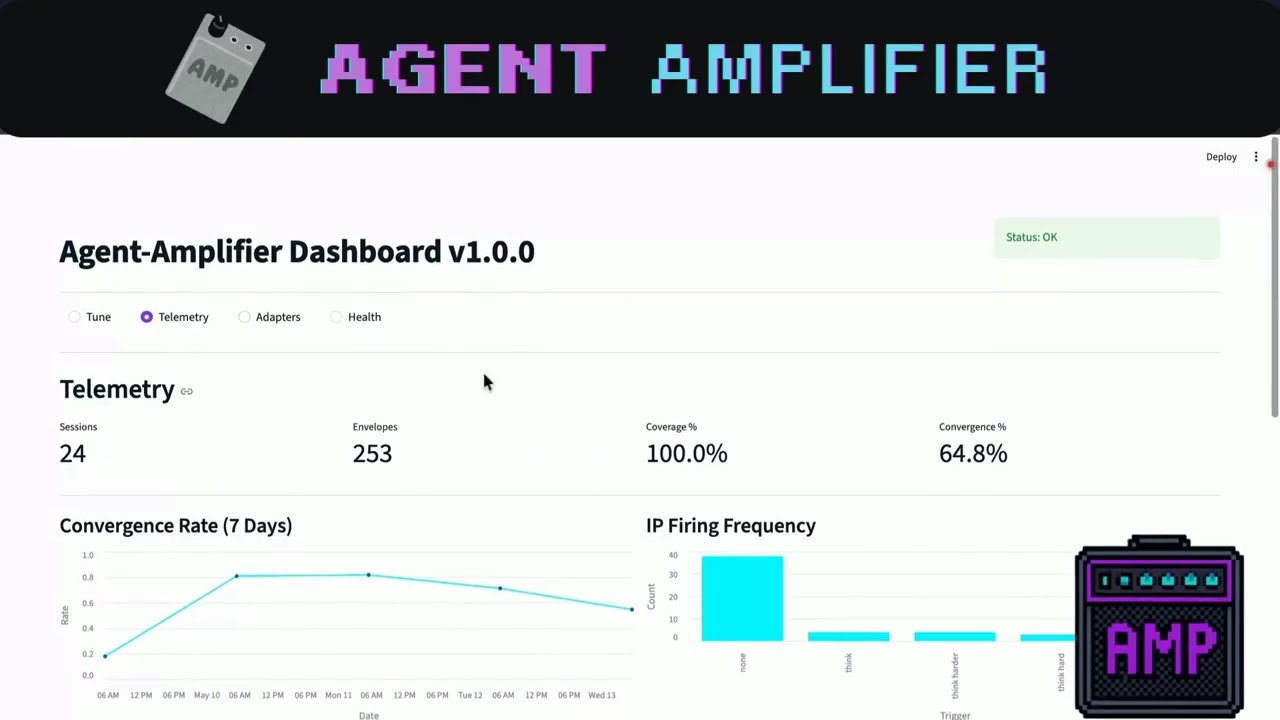
Numbers from the maintainer's machine, 3 days of dogfood on real Claude Code sessions (2026-05-09 to 2026-05-12). Not synthetic benchmarks.
Sessions: 18
Turns classified: 152
Events recorded: 1,607
Outcome coverage: 99.3% (151/152 turns)
Heavy turns (>=5 tool calls, real engineering work):
Count: 44
Convergence: 72.7% (32/44 stabilized within 4 iterations)
Avg duration: 4 min 46 sec
Max single turn: 957 sec, 57 tool calls
Hook latency (M-series MacBook Pro):
UserPromptSubmit P50 = 72ms P99 = 77ms
Stop hook P50 = 61ms
Sweep recovery: 29.1% of outcomes were abandoned envelopes -- all recovered
The hard cap is 4 iterations by default. On high-complexity turns, convergence within 4 is 24.4% -- because hard tasks genuinely need more loops. Power users can raise the cap: AGENT_AMP_MAX_ITERATIONS=8.
A single number lies. v1.1 captures a triple-signal per turn so the dashboard is honest about what's working and what isn't.
completed-- did the agent finish every tool call before stopping? Measures liveness, not quality. (v1.0 stored this underconverged; the old name stays for one minor and is removed in v1.2.)quality_score-- bounded[0, 1]. Three deterministic tiers compose into one number:- Tier 1 (always): Jaccard similarity between the envelope goal text and Claude's final assistant message (extracted from the session transcript JSONL). Re-uses the same keyword-set extractor as the convergence detector.
- Tier 2 (optional, ~40ms): local embedding via Ollama's
nomic-embed-textwhen Tier 1 lands in the ambiguous band (0.30-0.70). Cosine similarity is blended 30/70 with the lexical signal. Falls back to Tier 1 alone if Ollama is unreachable. - Tier 3 (always): trajectory delta. Penalises looping (3+ identical PreToolUse events) and missing reconnaissance (Edit/Write/MultiEdit on a path that was never Read). Up to -0.20.
convergence_state-- per-session trajectory enum:improving/stagnant/oscillating/converged. Derived from the rolling history ofquality_scorefor the session.
Synthetic / benchmark / demo sessions are tagged is_synthetic=1 and hidden from agent-amp report by default. Pass --include-synthetic to see them, --synthetic-only to inspect them alone. This prevents load-test data from poisoning the real-usage dashboard.
AA does no extra LLM calls on the Claude Code path. Tier 2 invokes a local Ollama embedding model (≈40ms on CPU); that is not an LLM call in the conventional sense and is opt-out via AGENT_AMP_EMBED_ENABLED=0. The kernel path (CrewAI / LangGraph / AgentScope / LangChain adapters) runs a multi-iteration loop with a real convergence detector -- opt-in per adapter.
Phase 4 benchmarks (raw model vs amplified) use AgentAssay's published verdict framework -- Wilson confidence intervals, Fisher exact test on completion rates, Mann-Whitney U on quality_score distributions, and a 3-valued PASS / FAIL / INCONCLUSIVE verdict that honestly says "not enough samples" instead of overclaiming. Install with pip install 'agent-amplifier[bench]'.
AgentAssay is the AI Reliability Engineering category's stochastic test framework -- Agent Amplifier composes with it the same way it composes with SuperLocalMemory.
Agent Amplifier owns execution quality (effort, drift, convergence). SuperLocalMemory owns memory (recall, write, decay, entity graph). They never compete; they always compose.
Both products install their own hooks. Claude Code merges all additionalContext into the prompt. SLM injects recall; amp injects amplification. Neither knows the other exists.
amp detects SLM, shells out to slm session-context, feeds chunks to the kernel's memory plane. The effort router sees prior task patterns, not just prompt text. Classifier accuracy goes up measurably.
amp's Stop hook writes per-turn outcomes to SLM. Tomorrow's amplification inherits today's results. Tasks that converged train the classifier. Tasks you abandoned get flagged as drift.
Without SLM: amp reads CLAUDE.md / MEMORY.md and writes a ## Amplifier note block to ./MEMORY.md at session end. Every user gets all 11 features regardless of memory provider. SLM is optional — amp works standalone, zero dependencies on any memory system.
Cloud memory (Claude.ai memory, OpenAI Memory, Mem0): already "adjacent" — the model sees cloud-injected context in its prompt, and amp's classifier reads that prompt. No extra wiring needed. Deep composition (Modes 2-3) requires a programmatic write contract that cloud providers don't expose to third parties today. Community adapters welcome via docs/adapter-spec.md.
# Install both (optional -- amp works standalone)
pip install superlocalmemory
slm install
pip install agent-amplifier
agent-amp install claude-code"Why not system prompts?" -- System prompts are static. amp is dynamic: different effort tier, different phase framing, different persona per iteration depth. A static system prompt cannot do convergence detection or budget enforcement.
"Why not fine-tune?" -- Fine-tuning changes the model. amp changes what the model sees and when the loop ends. No training, no GPU, no weeks of iteration. pip install and restart.
"Why not a bigger model?" -- A bigger model is still sloppy without effort routing. Opus still drifts. Opus still lacks convergence detection. amp makes any model work harder within its existing capability.
"Why not DSPy / LMQL / Guidance?" -- Those are prompt compilers that optimize prompt templates offline. amp is a runtime layer that operates inside the live agent loop. Different layer, different problem. You can use both.
"Is this the same as Microsoft Amplifier?" -- No. Microsoft Amplifier adds expert agents and a knowledge graph on top of Claude Code -- it is a workflow extension. Agent Amplifier intercepts reasoning quality at the hook layer. Different layers; they can coexist.
"Is this the same as Sourcegraph Amp?" -- No. Sourcegraph Amp is an AI coding agent (a product you use instead of Claude Code). Agent Amplifier makes your existing Claude Code better. That is why the CLI is agent-amp, never amp.
| # | Host | Adapter | Status |
|---|---|---|---|
| 1 | Claude Code | adapters/claude_code/ |
v1.0 flagship -- hook installer + stop bridge |
| 2 | Cursor | adapters/cursor.py |
v1.0 |
| 3 | GitHub Copilot | adapters/github_copilot.py |
v1.0 |
| 4 | LangGraph | adapters/langgraph.py |
v1.0 |
| 5 | CrewAI | adapters/crewai.py |
v1.0 |
| 6 | AgentScope | adapters/agentscope.py |
v1.0 |
| 7 | LangChain | adapters/langchain.py |
v1.0 |
Third-party adapter spec: docs/adapter-spec.md. Semantic Kernel adapter ships in v1.0.1.
agent-amp install <host> # install hooks (claude-code, cursor, github-copilot)
agent-amp uninstall <host> # remove hooks cleanly
agent-amp status # current config + active adapters
agent-amp status --watch # live token-usage bar
agent-amp doctor # environment diagnostics
agent-amp demo "<prompt>" # preview the amplified envelope for a single prompt
agent-amp bench # run baseline vs amplified comparison
agent-amp report # read-only dashboard over your local telemetry
agent-amp dashboard # launch FastAPI backend + Streamlit web UI
agent-amp config show # print active configuration
agent-amp persona list # list built-in + custom personas (with value tagline + when-to-use)
agent-amp persona show <slug> # full persona details
agent-amp persona add --name <slug> --label <label> --description <text> \
[--review-focus a,b,c]
# add a custom persona (description is sanitized)
agent-amp persona remove --name <slug>
# remove a custom persona (built-ins protected)
Agent Amplifier ships with 4 built-in audit personas, each with a value tagline ("what this catches") and a when-to-use hint:
| Slug | Use it for |
|---|---|
senior-engineer |
First-pass review of routine work |
security-paranoid-engineer |
Auth, payment, or anything across a trust boundary |
principal-oss-maintainer |
Pre-v1.0 freeze, API design, DX review |
distinguished-ai-safety-reviewer |
Pre-launch gate, migrations, expensive-to-roll-back deploys |
Custom personas live at ~/.config/agent-amplifier/personas.toml and can be
managed via the CLI (above), the dashboard Tune tab, or directly editing the
TOML. Every custom description passes through the same recall_safety
neutralizer the memory plane uses — <system-reminder>, <tool_use>,
zero-width chars, and lookalike Unicode are all rewritten before reaching
the LLM. See docs/features.md
for the full architecture, schema, and threat model.
Optional tokenizer extra for real BPE token counting:
pip install agent-amplifier[tokenizer] # o200k_base for modern models, cl100k_base for legacy{
"@context": "https://schema.org",
"@type": "SoftwareApplication",
"name": "Agent Amplifier",
"alternateName": ["agent-amp"],
"applicationCategory": "DeveloperApplication",
"applicationSubCategory": "AI Coding Agent Runtime Layer",
"operatingSystem": "macOS, Linux, Windows",
"description": "Runtime amplification layer for AI coding agents. Installs as 5 Claude Code hooks. Applies dynamic effort routing, goal anchoring, convergence detection, and tokenizer-aware budget control.",
"url": "https://github.com/qualixar/agent-amplifier",
"softwareVersion": "1.0.0",
"license": "https://www.gnu.org/licenses/agpl-3.0.html",
"publisher": {
"@type": "Organization",
"name": "Qualixar",
"url": "https://qualixar.com"
},
"offers": {
"@type": "Offer",
"price": "0",
"priceCurrency": "USD"
},
"keywords": "claude code hooks, agent reliability engineering, claude code plugin, agent runtime",
"softwareRequirements": "Python 3.10+"
}- Docs: qualixar.github.io/agent-amplifier
- PyPI: pypi.org/project/agent-amplifier
- Qualixar: qualixar.com -- AI Reliability Engineering
- Author: Varun Pratap Bhardwaj (@varunPbhardwaj)
- License: AGPL-3.0-or-later
Zero telemetry. All state lives on your machine at ~/.claude/agent-amp/state.db. Local-first by design. Built as part of the AI Reliability Engineering practice at Qualixar.