Architecture Principle: Kubernetes is an eventual-consistency engine, not a hierarchy of virtual machines. Day 2 outages are rarely single-component failures; they are the result of intersecting control loops (Identity, Compute, Network, Storage) grinding against each other.
This repository contains the diagnostic frameworks, failure signatures, and CLI triage protocols for debugging complex Kubernetes outages across AWS, Azure, and GCP.
New: 5 Real-World Failure Signatures & The Metrics That Predict Them 👉 https://www.rack2cloud.com/kubernetes-day-2-failures/
Want the full diagnostic theory and Azure-native checklists? 👉 Download the formatted PDF Playbook here
The continuously maintained master index lives here: 👉 https://www.rack2cloud.com/kubernetes-day-2-operations-guide/
Most engineering teams treat Kubernetes incidents as isolated bugs and debug the symptom (e.g., staring at a 502 error or a Pending pod) rather than the system.
When a storage placement decision creates a cross-zone network bottleneck, teams waste hours debugging the CNI or Ingress controller when the root cause was a CSI binding mode. True Day 2 reliability requires diagnosing the intersections of the cluster's control loops.
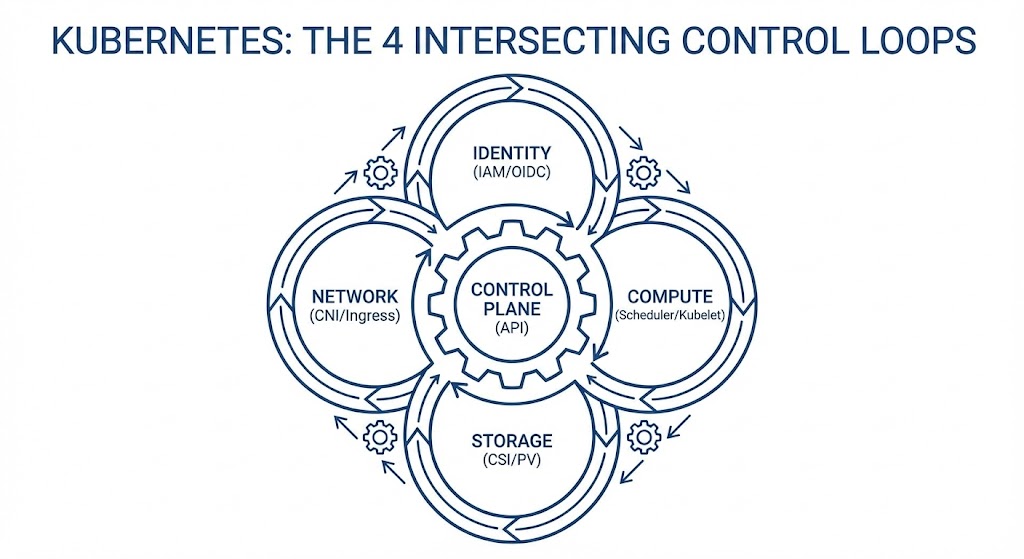
The 4 Intersecting Loops:
- Identity Loop: Authenticates the request (ServiceAccount → Cloud IAM/Entra ID).
- Compute Loop: Places the workload (Scheduler → Kubelet & Budgets).
- Network Loop: Routes the packet (CNI → IP Tables → Ingress).
- Storage Loop: Provisions the physics (CSI → EBS/Azure Disk/PD).
| Symptom / Error | Failing Loop | Root Cause Physics | Key Metric | Mitigation Strategy |
|---|---|---|---|---|
ImagePullBackOff / CrashLoopBackOff |
Identity | The registry is up, but the Node's STS/OIDC token expired or clock drifted. Auth fails silently — container crashes before writing useful logs. | kube_pod_container_status_restarts_total + exit code from kubectl describe pod |
Ephemeral workload identity; remove static secrets; monitor IMDS reachability. |
| Pending Pods (<50% CPU) | Compute | Scheduler bin-packing fragmentation — allocatable headroom exhausted even when utilisation looks low. maxUnavailable: 0 PDB deadlocks compound this. |
kube_node_status_allocatable vs kube_pod_resource_requests_cpu_cores sum by node |
Soften affinity rules (ScheduleAnyway); audit strict Requests/Limits ratio. |
502/504 Gateway Timeout |
Network | MTU mismatch between overlay (VXLAN/Geneve) and underlying NIC. Large packets silently dropped — no ICMP response in cloud provider networks. Presents as DNS until proven otherwise. | node_network_receive_drop_total + node_network_transmit_drop_total per overlay interface |
Lower CNI MTU to account for overlay headers; spoof Host headers to test paths. |
PVC Stuck / Pod in ContainerCreating |
Storage | Block storage is zonal. Pod rescheduled across AZ after node failure — volume can't follow. Default storage classes don't use WaitForFirstConsumer. |
kube_persistentvolumeclaim_status_phase{phase="Pending"} correlated with volume attach events |
Enforce volumeBindingMode: WaitForFirstConsumer on all StatefulSets. |
| API Server Timeouts / Controller Flapping | Control Plane | etcd I/O-bound — write-ahead log hits disk IOPS ceiling under burst. etcd heartbeat latency increases, API server queues requests, controllers lose sync. Workload layer looks healthy while control plane drowns. | etcd_disk_wal_fsync_duration_seconds_bucket p99 > 10ms = warning, > 100ms = critical. apiserver_request_duration_seconds_bucket p99 climbing with no traffic increase = control-plane problem. |
Dedicated low-latency disk for etcd (gp3 minimum, io2 preferred); separate etcd nodes from workload nodes; monitor WAL fsync p99 continuously. On managed K8s (EKS/AKS/GKE): monitor API server latency as the proxy metric. |
To guarantee cluster stability under load, the architecture must enforce these loop rules:
- Identity is Ephemeral: Cloud credentials must never be hardcoded as Kubernetes Secrets. Map IAM roles directly to ServiceAccounts.
- Compute is Budgeted: A pod without CPU/Memory requests is a rogue process. Unbudgeted pods will be evicted first during node pressure.
- Data Has Gravity: Storage provisioning must be deferred until the Compute scheduler has definitively selected an Availability Zone.
- Loop-to-Loop Observability: Logs are useless without context. Every structured log line must contain
trace_id,namespace,pod,node, andzone.
- Day 0 Cluster Installation guides
- CI/CD pipeline tutorials
- Application code debugging
This is a systems engineering and infrastructure diagnostic framework.
If this framework helped you survive a Day 2 outage, please star the repository.
Architectural frameworks maintained by Rack2Cloud.