For my capstone in the Udacity Machine Learning Nanodegree program, I applied machine learning techniques to a set of data regarding board games. My intent was two-fold:
- Fit a supervised learning model to a set of board game features, to predict game ratings.
- Use this model to provide insight into the characteristics of highly- and poorly-rated games.
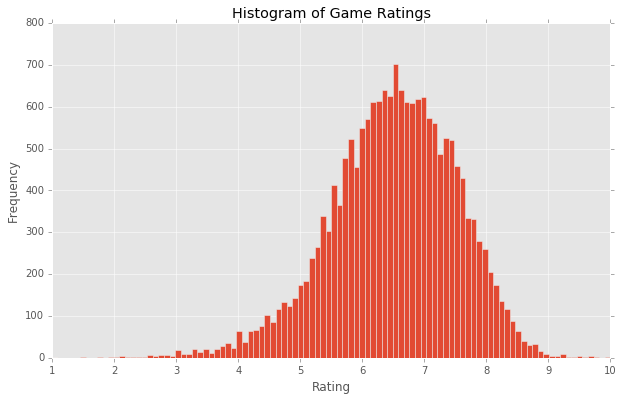
The data used in this project come from BoardGameGeek.com, and consist of 159 features for each of 84,593 games, each rated by the user community on a 1-10 scale. The ratings were distribued as follows:
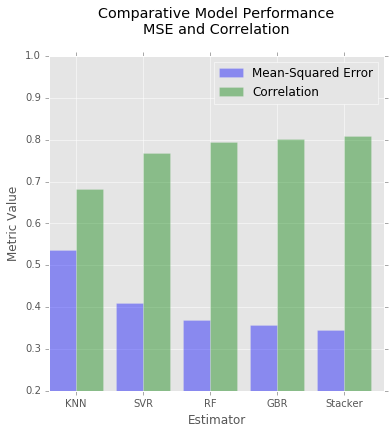
I created models using the following learners:
- Random Forest
- K-Nearest Neighbors
- Support Vector Regression
- Gradient Boosting Regression
I stacked the results of the above learners with the LassoCV estimator, and obtained a final model with a correlation of 0.809.
By creating artificial feature vectors, I could approximate 100,000 additional non-existent games, and predict their scores with this model. I then used this data in an attempt to draw some conclusions about highly- and poorly-rated games.
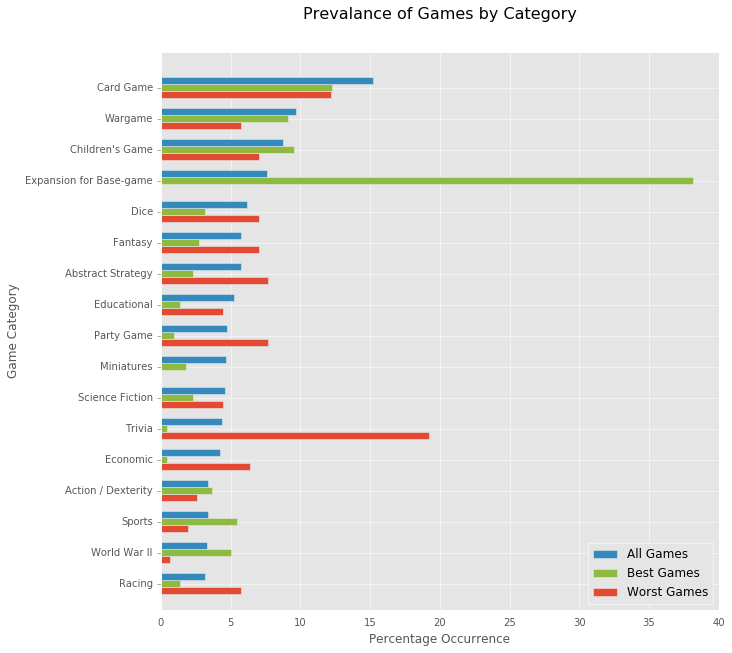
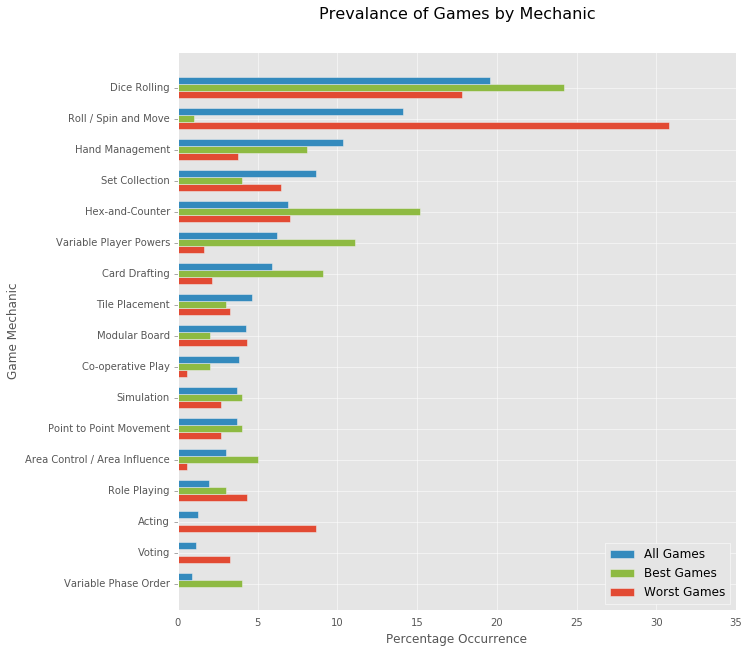
See the final report for more detail.