

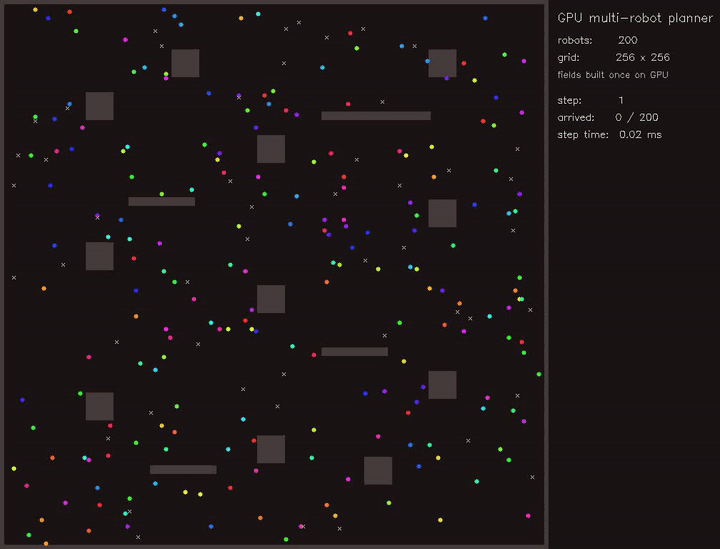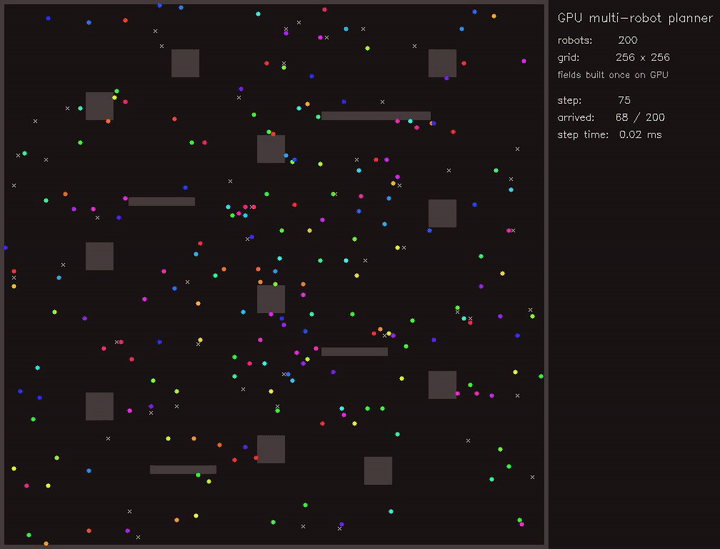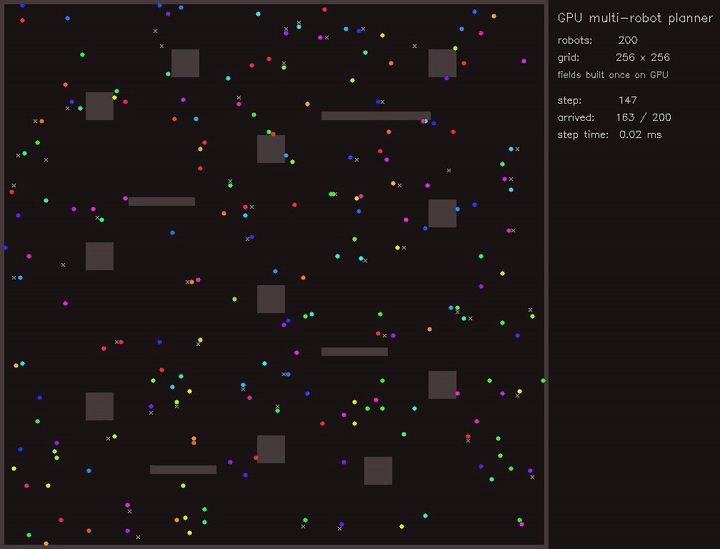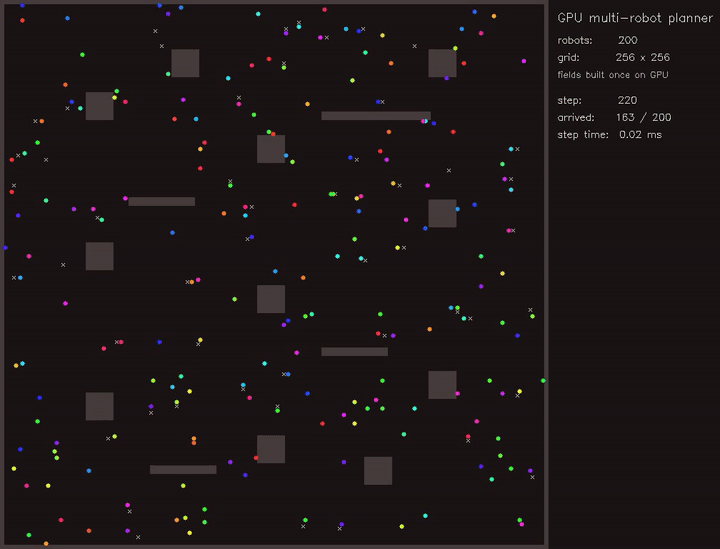


MPPI racing / Expansion-reset MCL / Multi-robot planner / Diffusion planner / Multi-robot place graph SLAM / Gaussian-Splatting SLAM / full gallery
CUDA Robotics is a GPU-first robotics playground and benchmark suite for SLAM, mapping, perception, planning, MPPI control, point-cloud registration, and learning demos in C++/CUDA.
Project goal: make this repo a reproducible OSS lab for GPU-accelerated robot planning, control, registration, and learning interfaces. New work should move at least one of those tracks from demo code toward runnable benchmarks, documented results, Python/ROS usability, or real-data validation.
If you are looking for a reason to star it: this repo turns robotics algorithms into small, runnable CUDA examples, then records both the speedups and the failure cases.
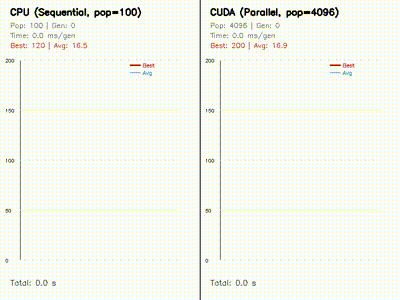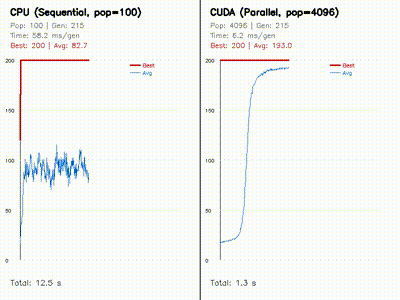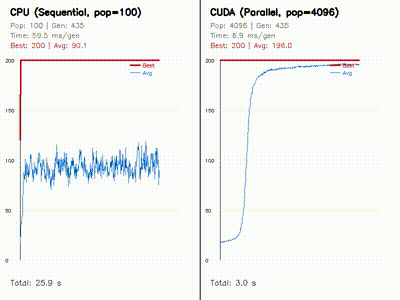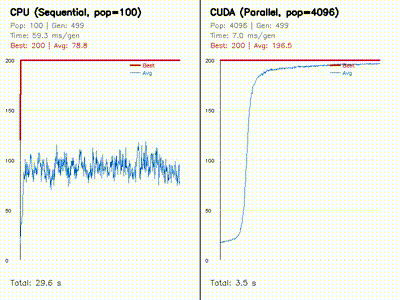
The core pattern is simple: keep a CPU reference or robotics baseline where it helps, then expose the parallel work as one CUDA thread per particle, ray, candidate pose, graph node, rollout, voxel, feature, or grid cell.
Full animated gallery: https://rsasaki0109.github.io/CudaRobotics/
The reusable GPU MPPI core is available as an experimental Python package. Build requirements: Linux x86_64, CUDA Toolkit >= 12.0, CMake >= 3.18.
No local GPU? Run the Colab quickstart notebook — it builds the package on a free Colab GPU and runs the MPPI + registration demos in your browser.
Development install (uses repo-root CUDA sources directly):
pip install -e python/
pip install -e 'python/[examples]' # optional: GIF rendering dependencies
python examples/python/mppi_quickstart.py
python examples/python/mppi_dlpack_costmap.py # optional: CUDA PyTorch or CuPy costmapInstall from source distribution (self-contained sdist; compiles against local CUDA):
./scripts/sync_python_core.sh # maintainers: refresh bundled core before release
cd python && python -m pip install build && python -m build
pip install python/dist/cudarobotics-*.tar.gz
pip install 'python/dist/cudarobotics-*.tar.gz[test]'
pytest python/testsCI attaches linux_x86_64 wheels for Python 3.10/3.12 as workflow artifacts.
On pushes to master, a separate cibuildwheel job also builds manylinux
wheels (see .github/workflows/python-package.yml). They require a compatible
NVIDIA driver at runtime.
Minimal use:
import numpy as np
import cudarobotics as cr
planner = cr.MppiPlanner(batch_size=2048, time_steps=56, model_dt=0.05)
costmap = np.zeros((200, 200), dtype=np.uint8)
path = np.array([[x, 5.0] for x in np.arange(1.0, 9.1, 0.1)], dtype=np.float32)
v, vy, w, info = planner.compute(
(1.0, 5.0, 0.0), costmap, path, (9.0, 5.0, 0.0), resolution=0.05
)For learning stacks, costmap may also be a CUDA DLPack producer such as a
PyTorch or CuPy tensor. In that case the MPPI core consumes the device pointer
directly instead of staging the costmap through host memory.
See examples/python/mppi_dlpack_costmap.py
for a runnable torch/CuPy example and info diagnostics readout.
Rigid and non-rigid registration live under cudarobotics.registration:
pip install -e python/
# or from sdist: pip install python/dist/cudarobotics-*.tar.gz
python examples/python/registration_quickstart.pyimport cudarobotics as cr
robust = cr.registration.RobustP2Plane() # Student's-t + point-to-plane
rotation, translation, info = robust.register(target_xyz, source_xyz)
sinkhorn = cr.registration.SinkhornReg()
rotation, translation, info = sinkhorn.register(target_xyz, source_xyz)FilterReg, FGR, BCPD, and RobustTreg are also available (see
examples/python/registration_quickstart.py).
The checked-in MPPI zoo suite was generated on 2026-06-10 with five navigation
scenarios, ten curated planners (including soppi / soppi_fast), K=64,128,
and 3 seeds per scenario/planner/K cell. It is a fixed-seed benchmark, not a
paper-faithful claim, but it adds stress scenes beyond the earlier smoke pair
and keeps the failures visible.

Side-by-side rollout on dynamic_crossing (K=128): vanilla mppi stalls short
of the goal while step_mppi_smooth reaches it.
| Scenario | Signal in this suite |
|---|---|
dynamic_crossing |
Vanilla mppi fails; curated zoo variants solve all cells. |
model_mismatch_crossing |
Vanilla mppi fails; step_mppi_smooth / tsallis_mppi_smooth reach 1.00 at K=128. |
dynamic_pincer |
Vanilla mppi fails with large final distance; zoo variants succeed. |
uncertain_crossing |
Same pattern as dynamic crossing: vanilla mppi fails, zoo variants succeed. |
narrow_passage |
All smooth zoo planners succeed; soppi also clears both K cells here. |
Full report and CSV:
docs/results/mppi_zoo_suite_2026-06-10.md
and
docs/results/mppi_zoo_suite_2026-06-10.csv.
Suite leaders (5 scenarios × 2 K values, 3 seeds per cell):
| Planner | Solved | Success | Avg ms | Notes |
|---|---|---|---|---|
step_mppi_smooth |
9/10 | 0.97 | 0.116 | Fastest curated planner in the suite |
tsallis_mppi_smooth |
9/10 | 0.97 | 0.175 | Tied for best solve rate |
sc_mppi_smooth |
9/10 | 0.97 | 0.198 | Strong safety-controlled baseline |
soppi / soppi_fast |
2/10 | 0.20 | 0.30 / 0.25 | Navigation negative control; wins only on narrow_passage |
mppi |
2/10 | 0.20 | 0.126 | Baseline negative control |
The eight-planner suite from 2026-06-09 remains at
docs/results/mppi_zoo_suite_2026-06-09.md.
The smaller two-scenario smoke artifact from 2026-06-05 remains at
docs/results/mppi_zoo_smoke_2026-06-05.md.
Requires NVIDIA Container Toolkit and a CUDA-capable GPU.
Quick smoke:
docker compose build cudarobotics
docker compose run --rm cudarobotics bash -lc 'python3 scripts/run_mppi_zoo_smoke.py --bin ./bin/benchmark_diff_mppi --out-dir build/mppi_zoo'Expanded fixed-seed suite:
docker compose build cudarobotics
docker compose run --rm cudarobotics bash -lc 'python3 scripts/run_mppi_zoo_suite.py --bin ./bin/benchmark_diff_mppi && python3 scripts/render_mppi_zoo_suite_chart.py'Comparison GIF (dynamic_crossing, vanilla mppi vs step_mppi_smooth):
cmake --build build --target benchmark_diff_mppi -j$(nproc)
python3 scripts/render_mppi_zoo_gif.py --bin bin/benchmark_diff_mppi- Self-contained C++/CUDA demos instead of framework-heavy examples.
- GPU kernels are shaped around robotics workloads: rollouts, particles, rays, voxels, grid cells, graph nodes, feature matches, and candidate poses.
- Reproduction docs include negative results and limitations, not only wins.
- The MPPI stack includes a growing benchmarked zoo of paper-inspired variants.
The MPPI work is now indexed as a reproducible research backlog. Each entry is a lightweight CUDA implementation plus notes on where the result works, where it does not, and what would be required for a paper-faithful reproduction.
| Family | Suite signal (2026-06-09) | What to open first |
|---|---|---|
| Tsallis-MPPI | 10/10 solved; best overall | docs/tsallis_mppi_reproduction.md |
| Step-MPPI | 9/10 solved; fastest curated planner | docs/step_mppi_reproduction.md |
| SC-MPPI | 9/10 solved; safety-controlled baseline | docs/sc_mppi_reproduction.md |
| DRA-MPPI | 8/10 solved; strong on dynamic_pincer |
docs/dra_mppi_reproduction.md |
| C2U-MPPI | 8/10 solved | docs/c2u_mppi_reproduction.md |
| DUCCT-MPPI | 8/10 solved | docs/ducct_mppi_reproduction.md |
| LP-MPPI | 8/10 solved | docs/lp_mppi_reproduction.md |
| DBaS-Log-MPPI | not in suite; smoke benchmark only | docs/dbas_log_mppi_reproduction.md |
| PA-MPPI | not in suite; narrow-passage smoke | docs/pa_mppi_reproduction.md |
| SOPPI | 2/10 nav; box_swivel 1.00; box_align_contact_arc 1.00; strict box_align_contact_loss soppi_fast 1.00 vs MPPI 0.00 |
docs/soppi_reproduction.md |
| Full index + CSV | docs/results/mppi_zoo_suite_2026-06-10.csv |
docs/mppi_reproduction_zoo.md |
| Demo | What it shows |
|---|---|
cuda_mppi_controller |
Drop-in GPU MPPI for Nav2 — 65k rollouts in ~10 ms; DiffDrive / Ackermann / Omni motion models verified. |
gpu_multi_robot_place_graph_slam |
Multi-robot place recognition scores 60,516 descriptor pairs on the GPU, adds inter-robot loop edges, and cuts pose-graph RMSE from 7.59 m to 3.33 m. |
gpu_bnb_loop_closure_slam |
Branch-and-bound loop search scores about 957x fewer candidates than brute force while returning the same relpose on 51/51 attempts. |
gpu_gaussian_splatting_slam |
RGB-D Gaussian-Splatting SLAM with GPU ray-cast sensor, point-to-plane ICP tracking, and incremental Gaussian map fusion. |
gpu_nerf_volume |
NeRF volume rendering with GPU ray marching. |
gpu_ndt_3d_multires |
Multi-resolution NDT 3D scan matching on the GPU. |
gpu_gicp_3d |
GICP 3D point-cloud registration with GPU parallel correspondence search. |
gpu_hungarian_assignment |
GPU Hungarian assignment for multi-target data association. |
gpu_mppi_racing |
MPPI autonomous racing with 2048 x 40 rollouts per control step on the GPU. |
gpu_kdtree_nn |
Exact KD-tree nearest-neighbour search for 40k queries, matching brute force while running much faster. |
gpu_sgm_stereo |
Semi-Global Matching stereo with CUDA census and path aggregation. |
gpu_wavefront_planner |
Bellman-Ford-style cost-to-go relaxation over a 384x384 planning grid. |
gpu_pcg_solver |
GPU preconditioned conjugate-gradient linear solver benchmark. |
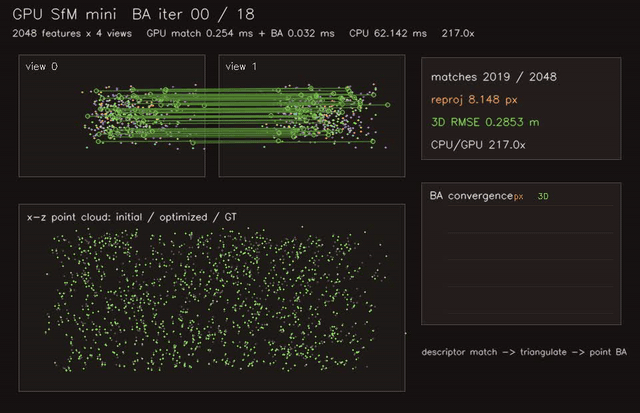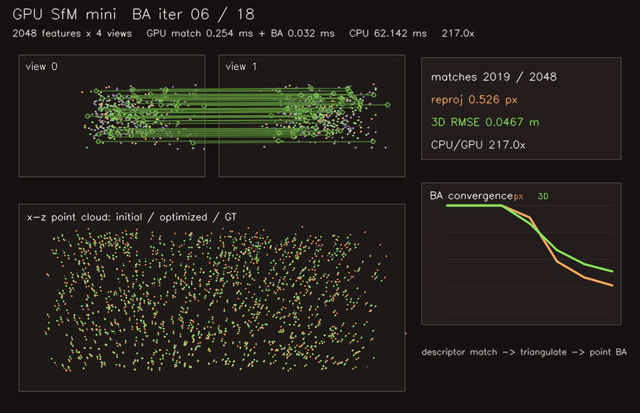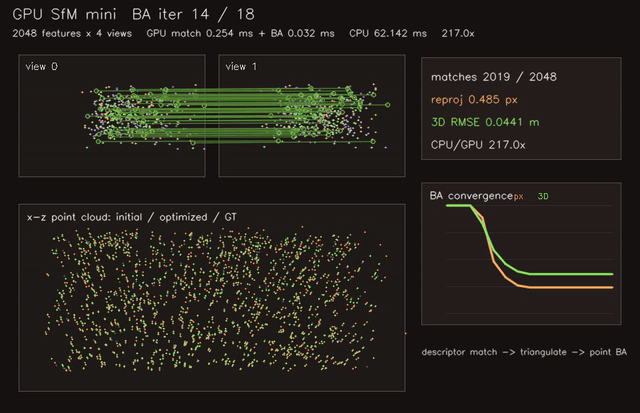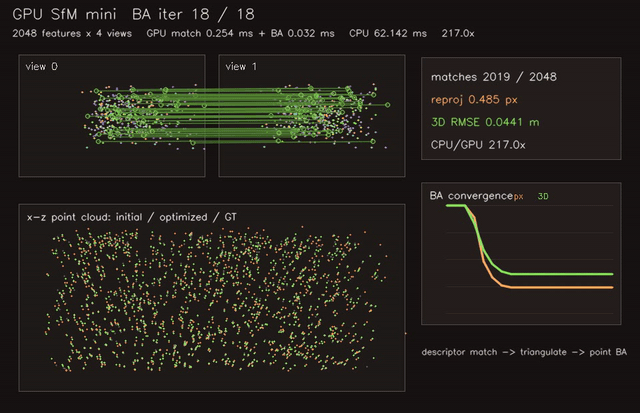
gpu_sfm_mini |
Structure-from-motion mini pipeline with GPU triangulation. |
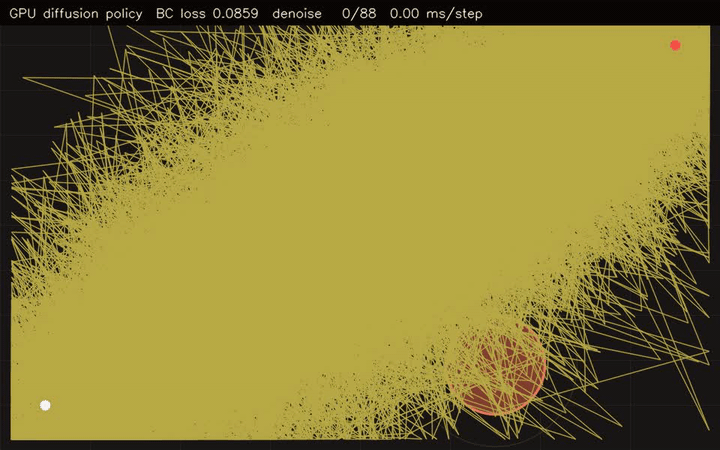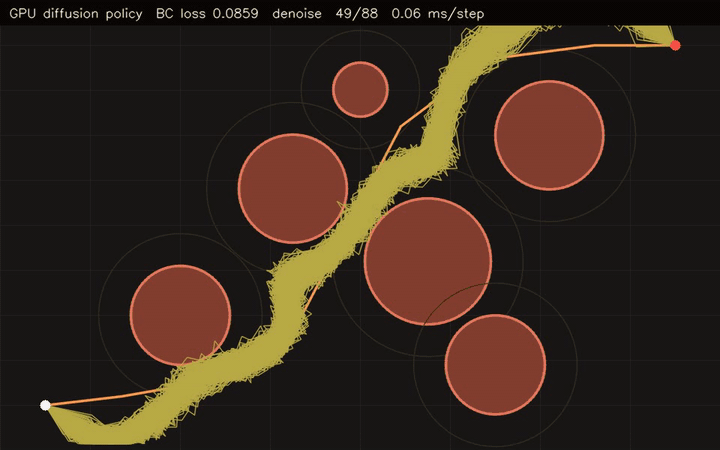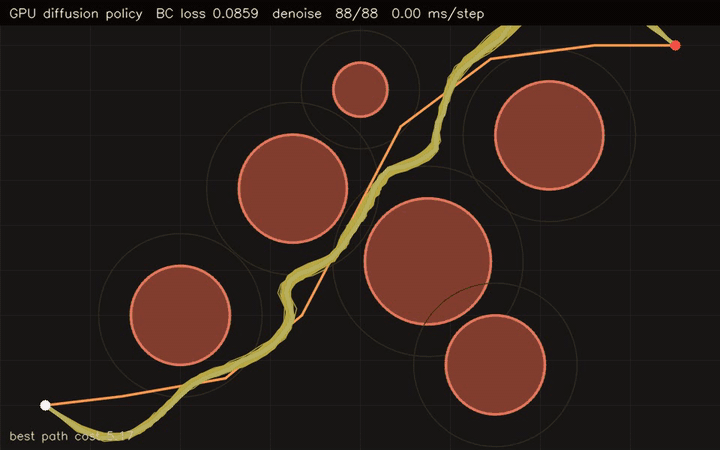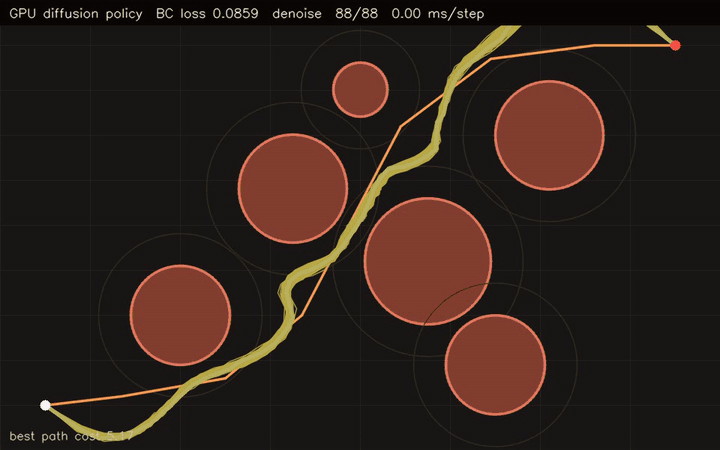
gpu_diffusion_planner |
Diffusion-based motion planner with GPU rollout scoring. |
gpu_assignment_tracking |
GPU assignment + multi-object tracking pipeline. |
gpu_frontier_exploration |
GPU frontier exploration with parallel ray casting over an occupancy grid. |
gpu_diff_contact_push |
Differentiable contact pushing with GPU rollout scoring. |
gpu_constrained_mpc |
Constrained nonlinear MPC (AL-iLQR) for multi-robot obstacle avoidance. |
gpu_kiss_icp |
KISS-ICP-style LiDAR odometry with GPU nearest-neighbour correspondences. |
|
 |
|
 |
 |
 |
A representative slice per category. The full animated gallery has the rest.
The most visually striking GPU demos, where massive parallelism really shows.
|
 |
| RGB-D Gaussian-Splatting SLAM | NeRF volume rendering |
 |
 |
| Structure-from-motion (mini) | TSDF fusion |
|
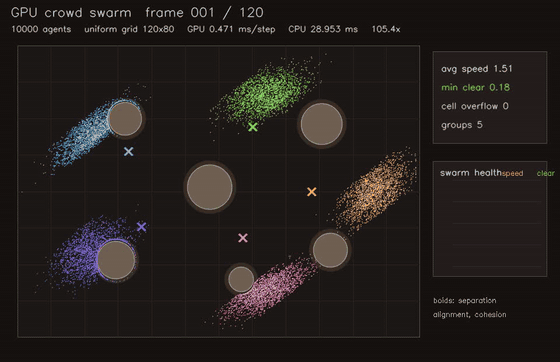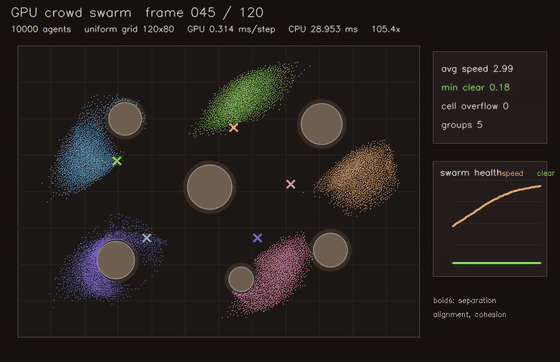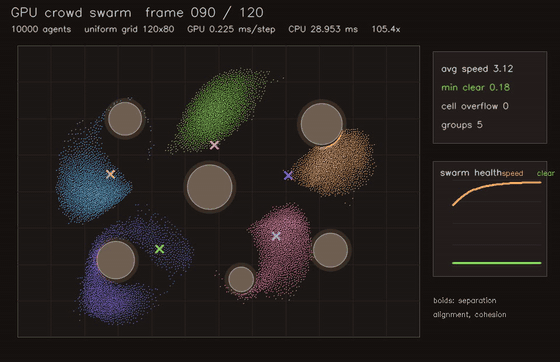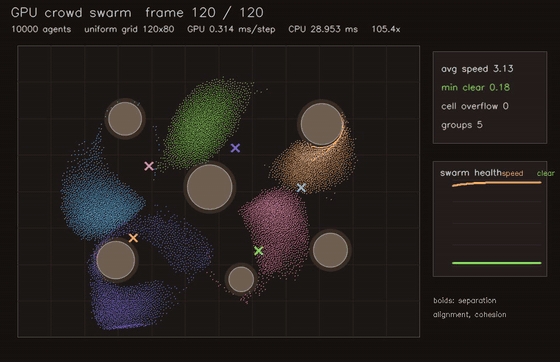 |
| MPPI autonomous racing (2048 x 40 rollouts) | Crowd / swarm simulation |
 |
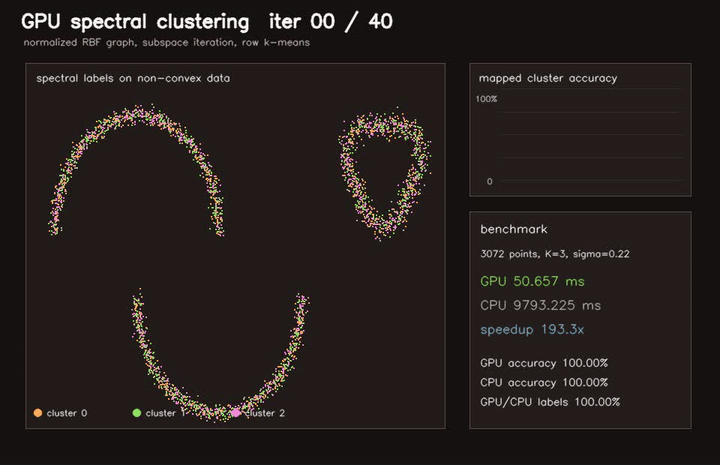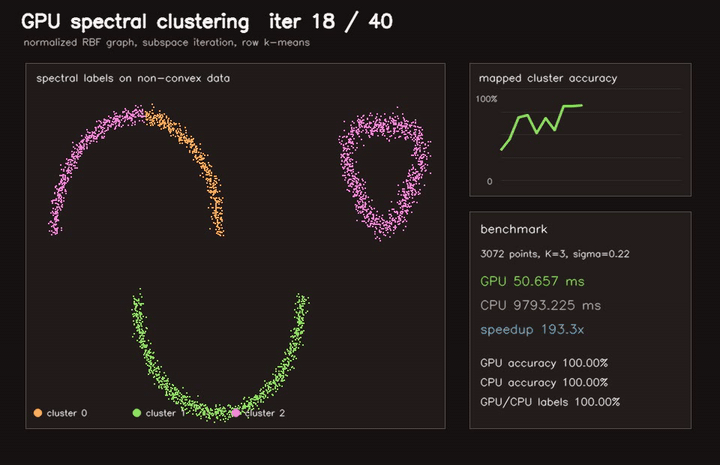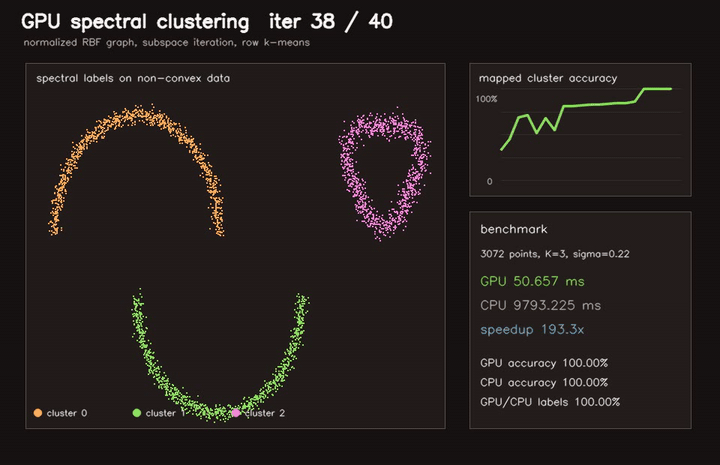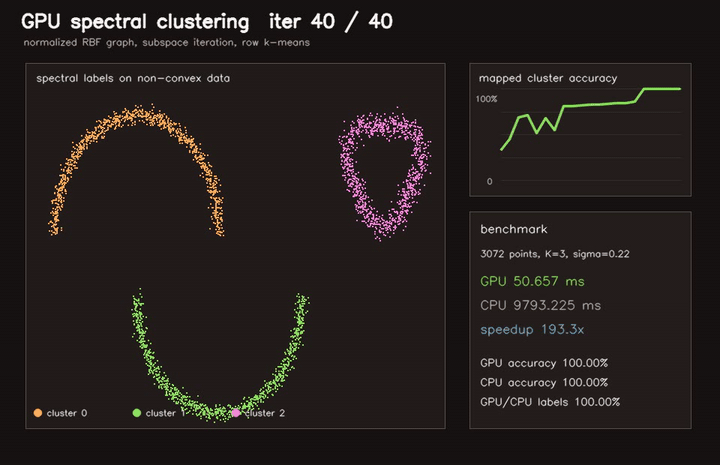 |
| Marching Cubes | Spectral clustering |
|
|
| Multi-robot place graph SLAM | Gaussian-Splatting SLAM (RGB-D) |
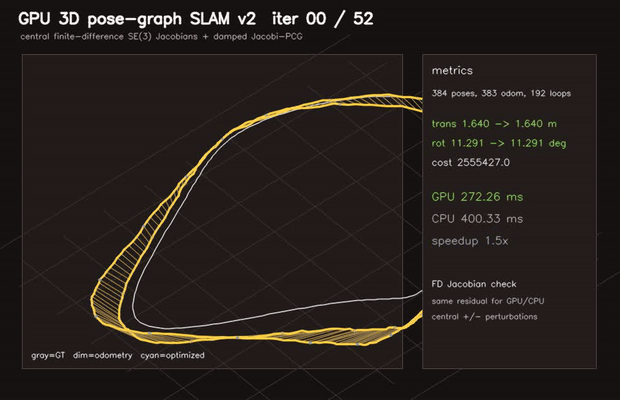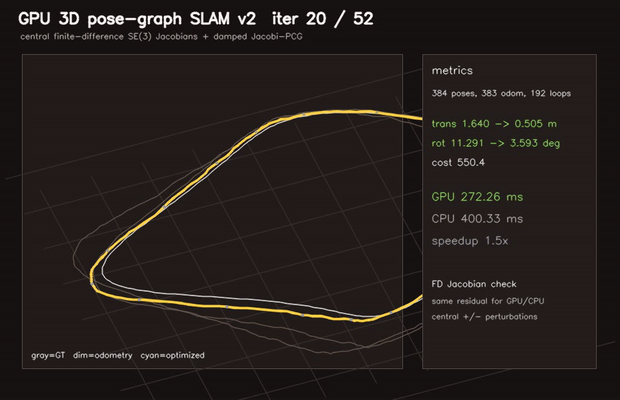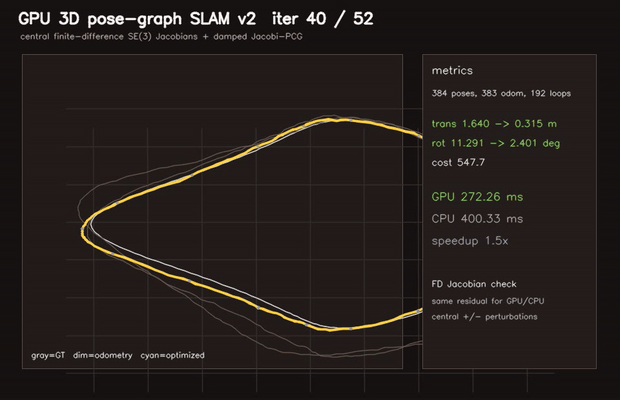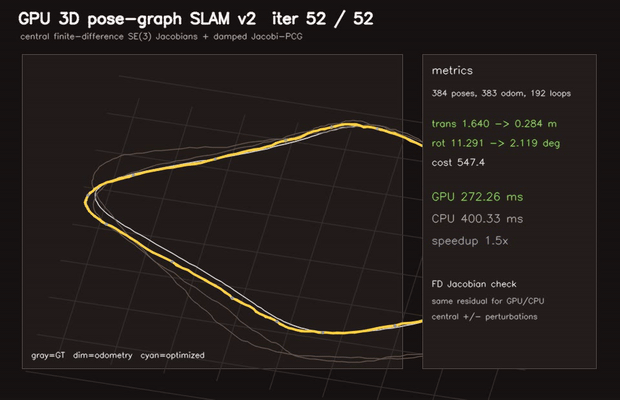 |
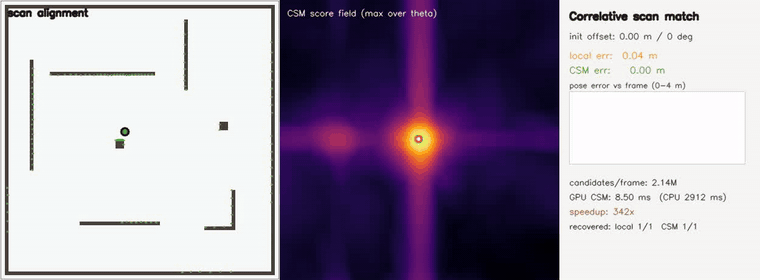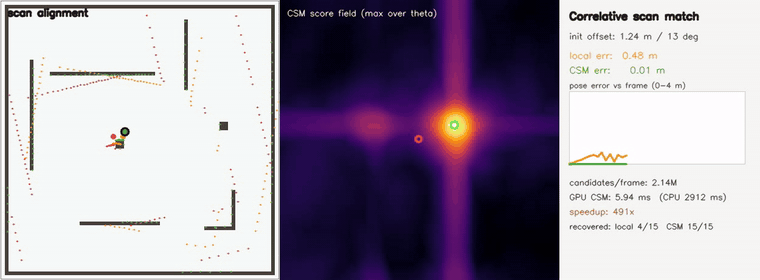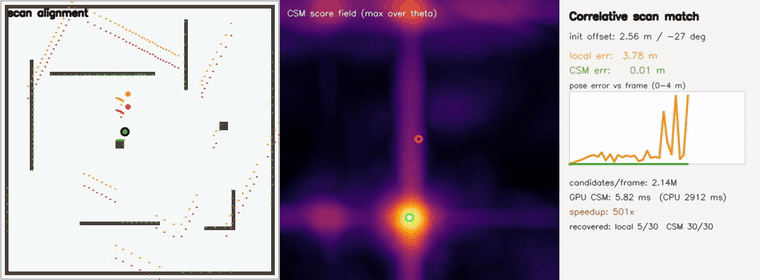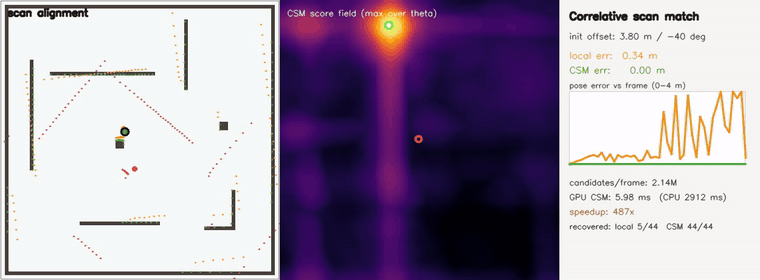 |
| 3D pose-graph SLAM | Correlative scan matching |
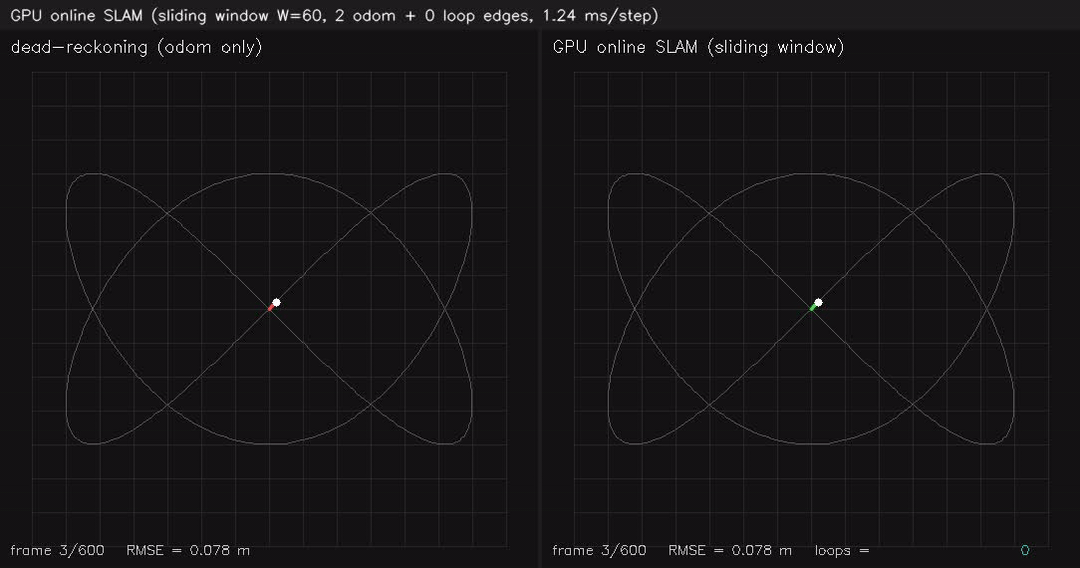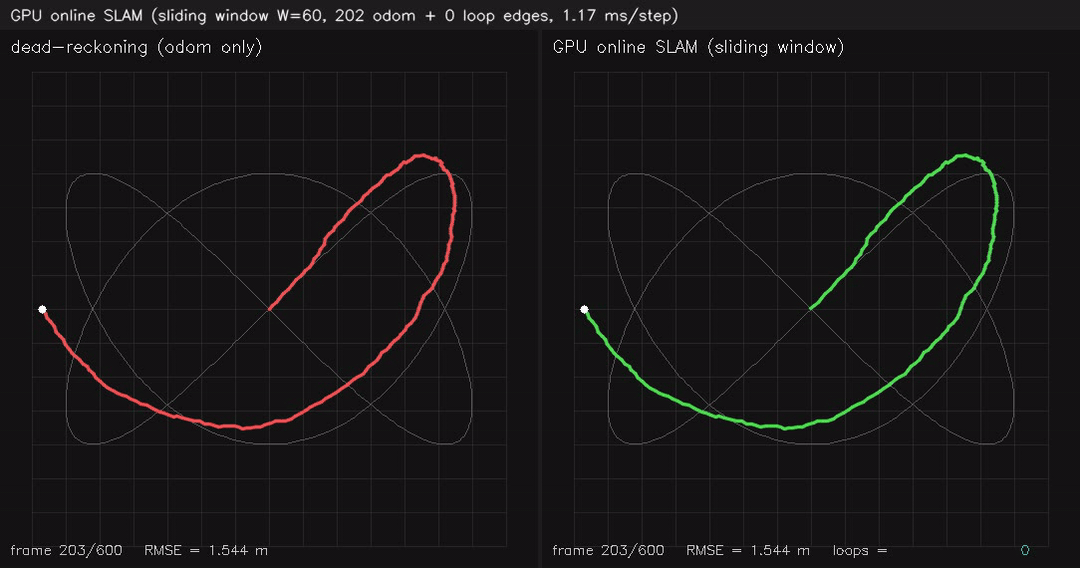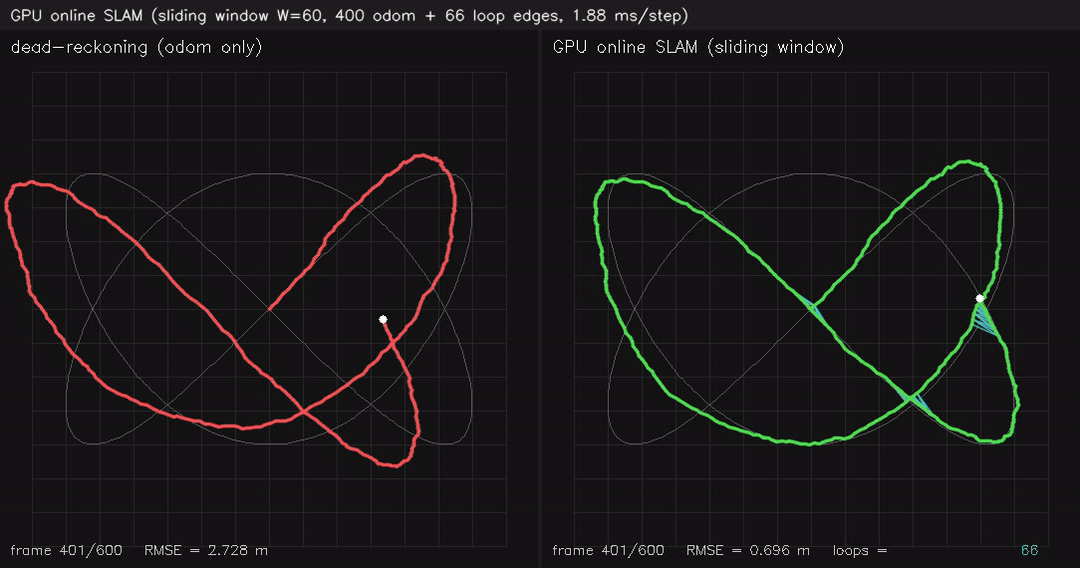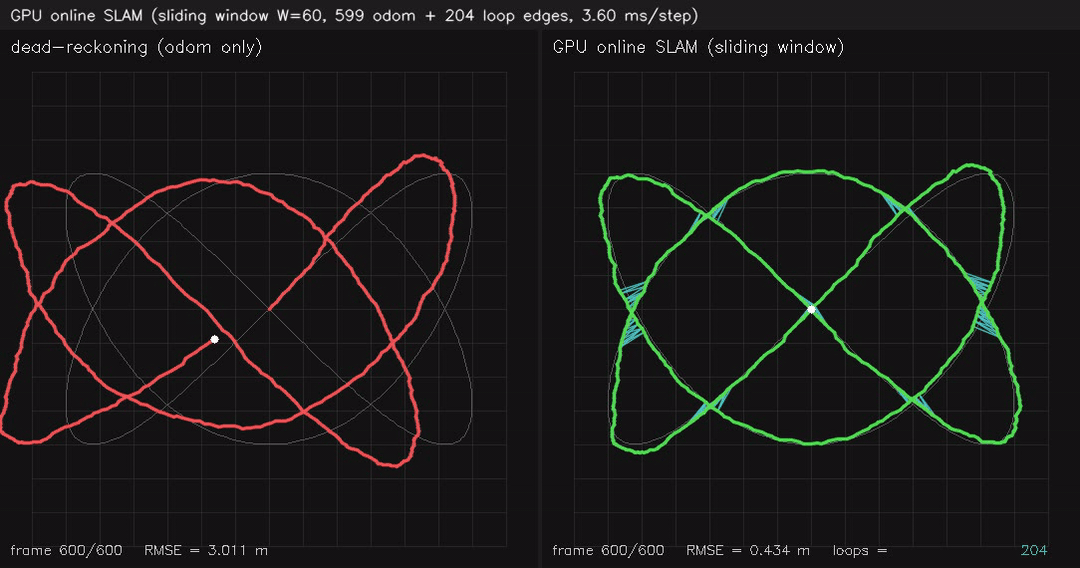 |
 |
| Online SLAM | Submap loop-closure SLAM |
 |
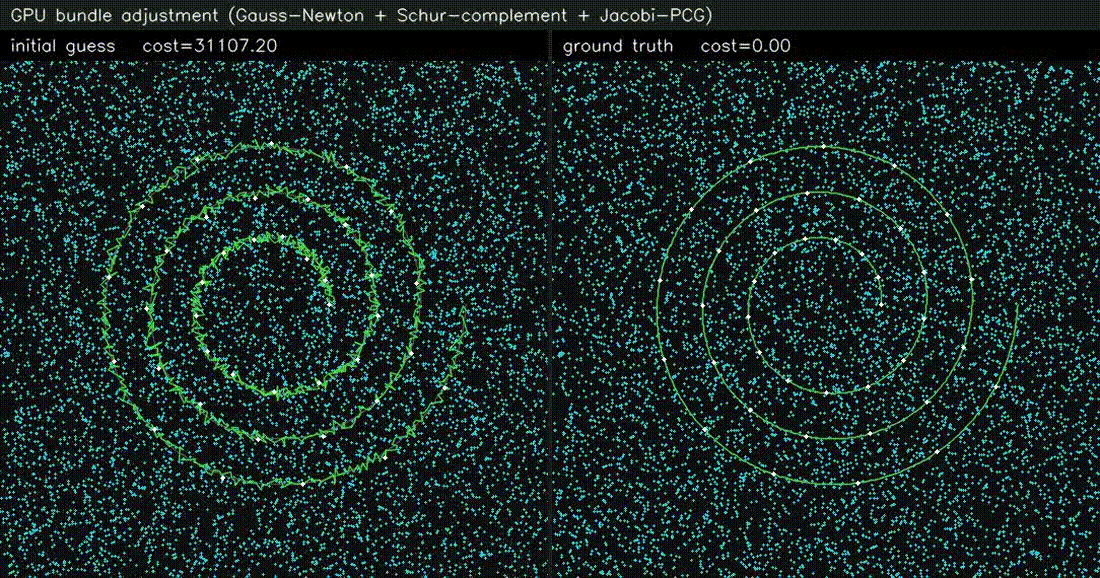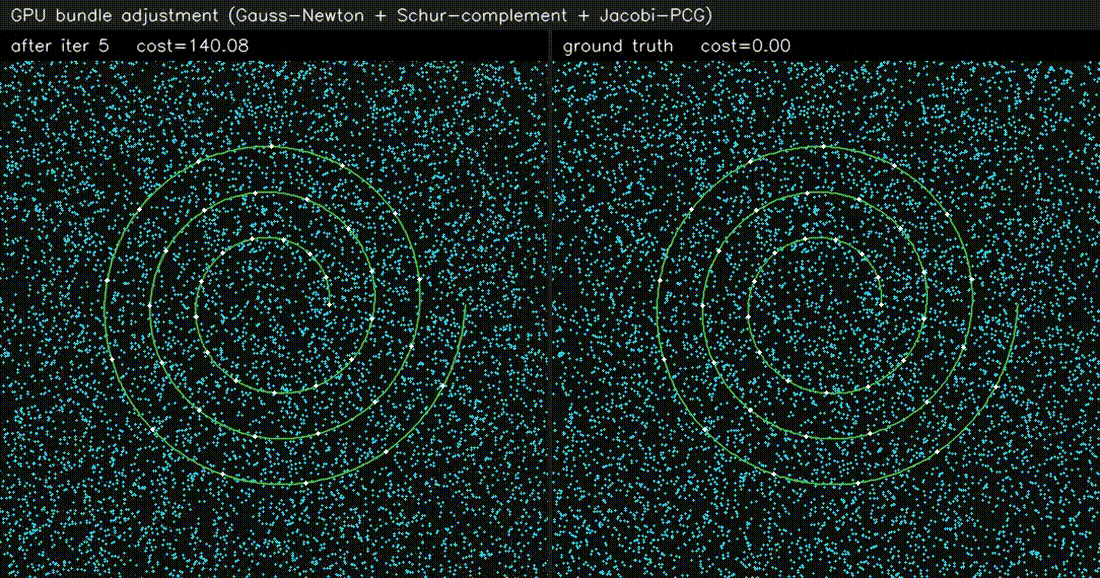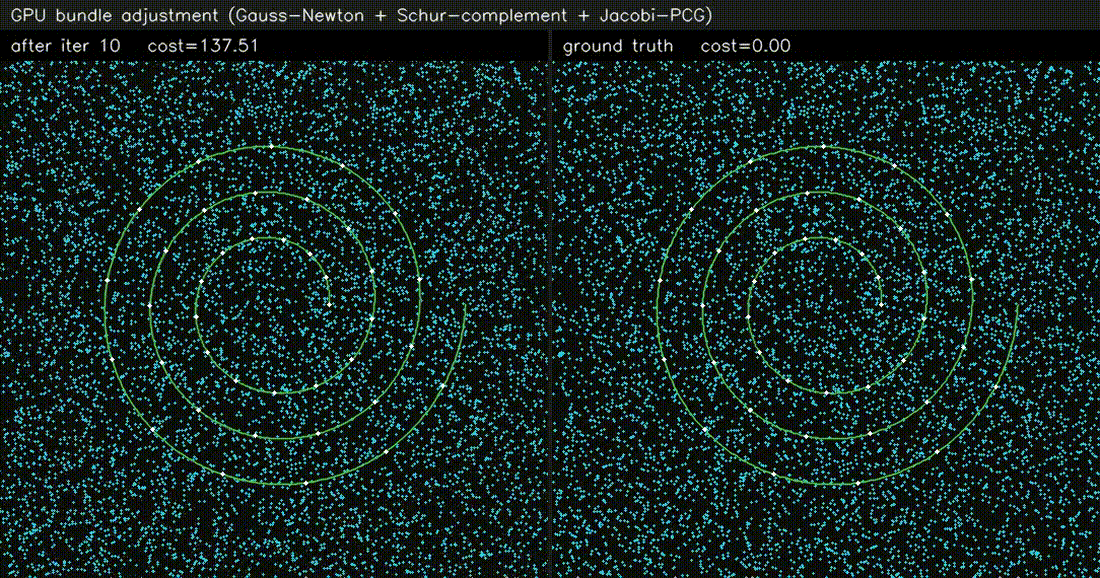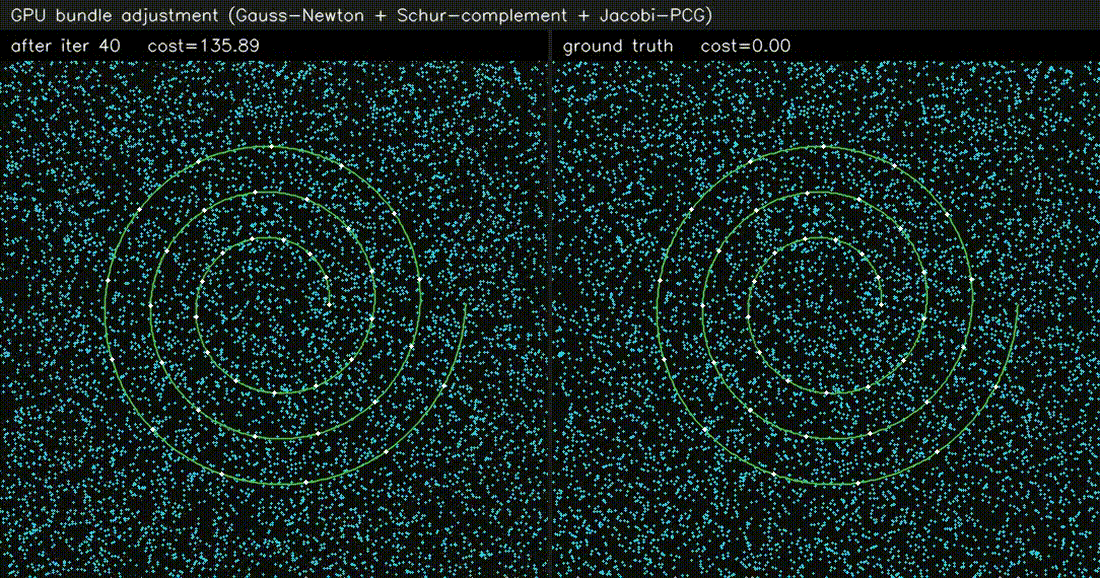 |
| LiDAR SLAM | Bundle adjustment |
 |
|
| KISS-ICP-style LiDAR odometry (0.02% drift from scans alone) |
 |
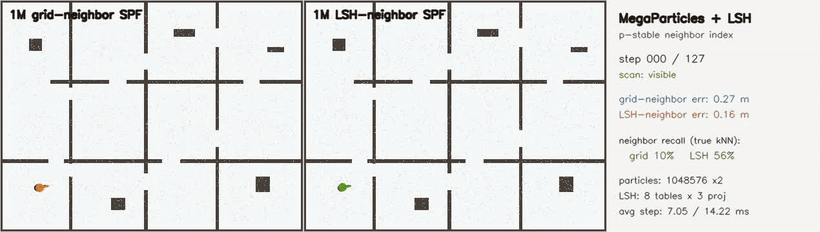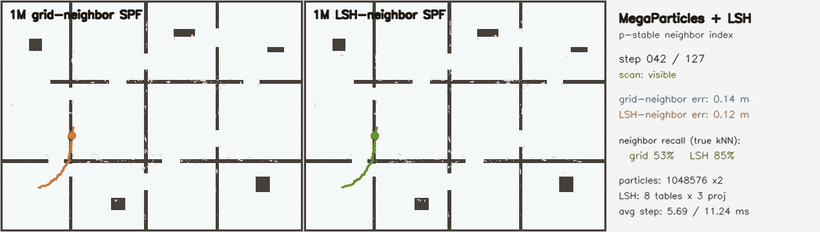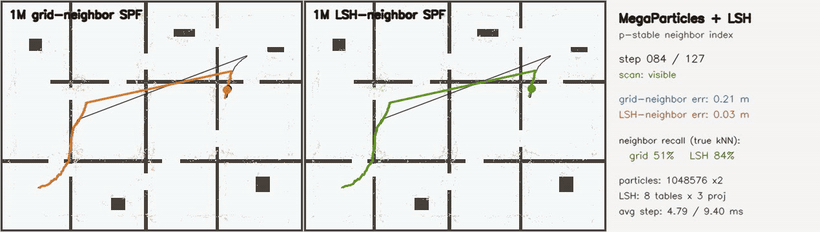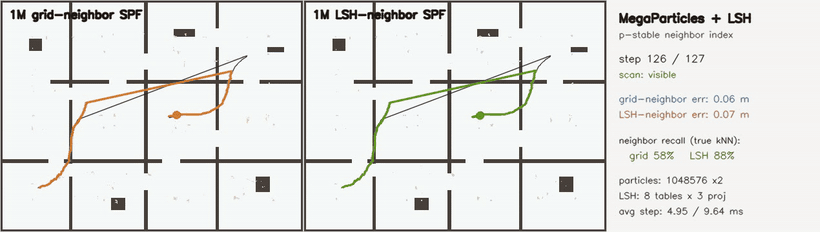 |
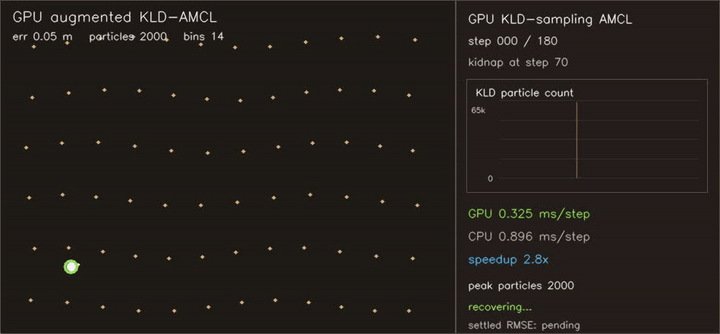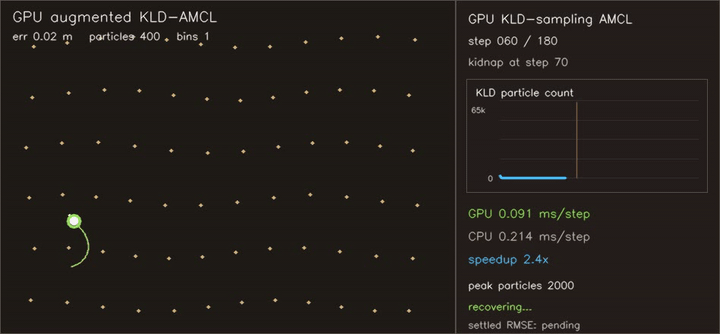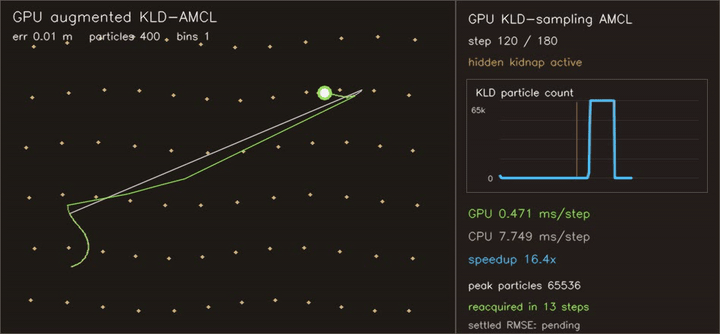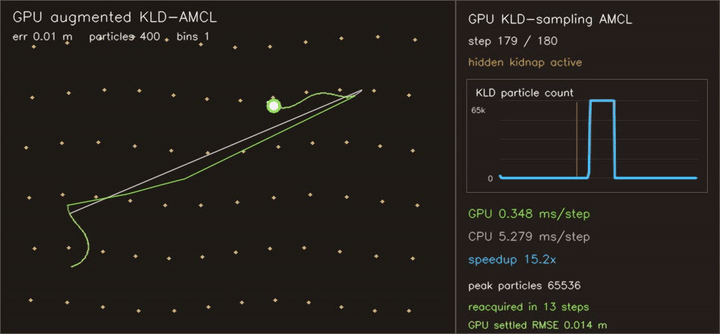
| KLD-AMCL | MegaParticles global localization (LSH) |
 |
|
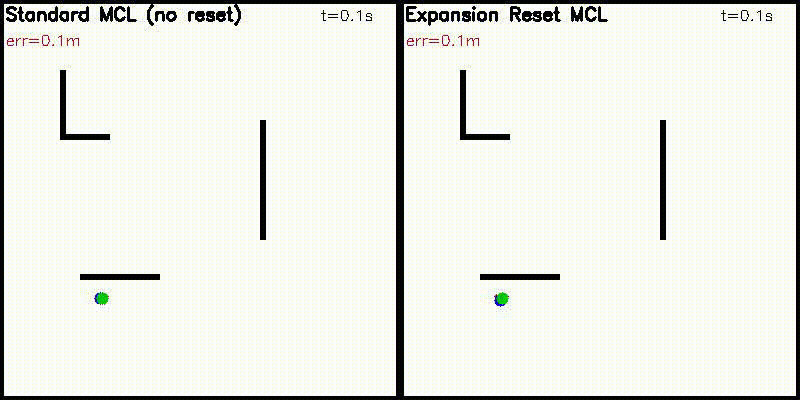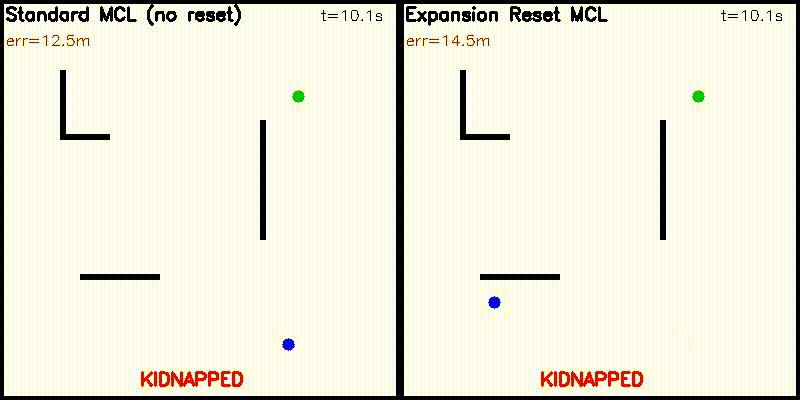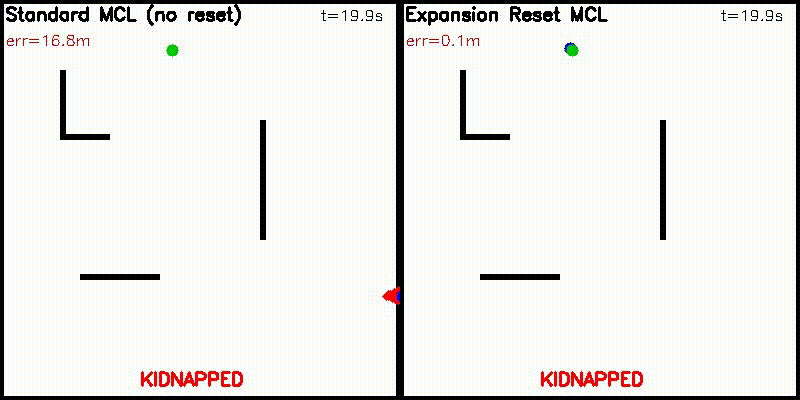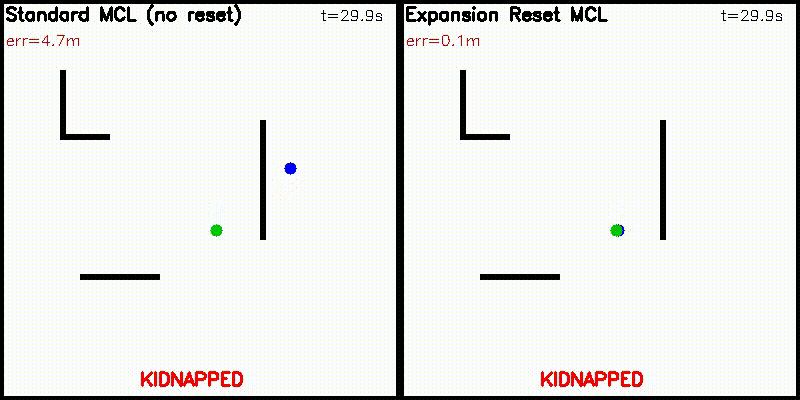
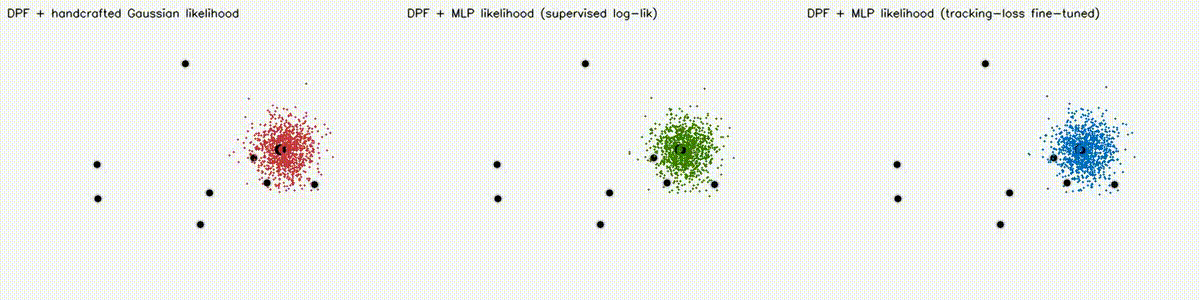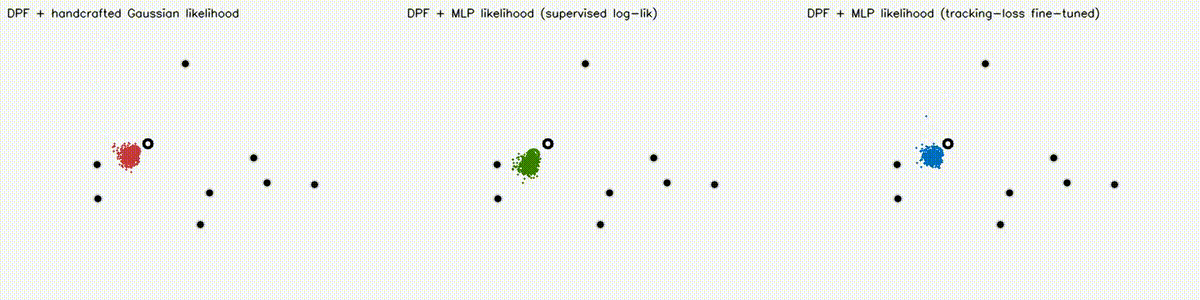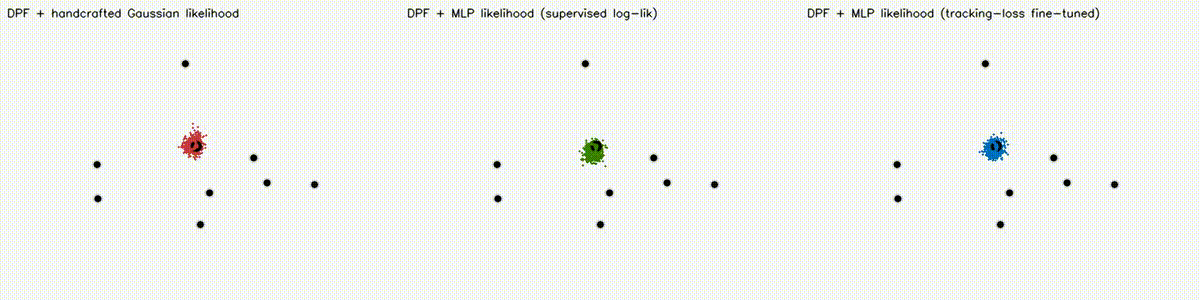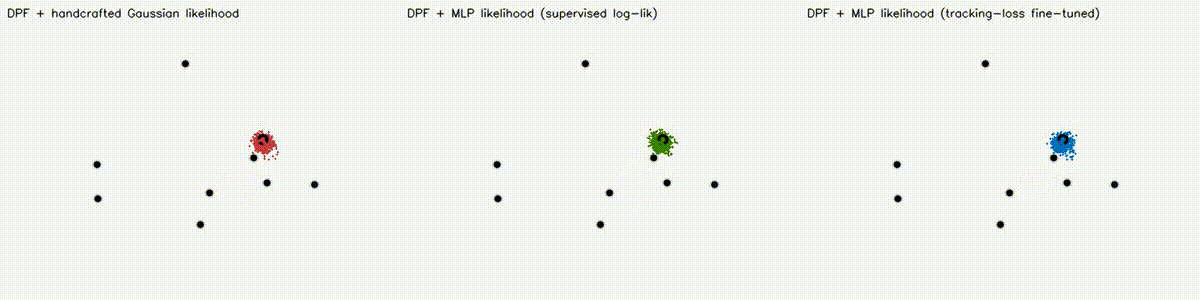
| Differentiable particle filter (MLP) | Expansion-reset MCL |
 |
 |
| Global localization MCL | MegaParticles Stein MCL |
 |
 |
| AMCL (CPU vs GPU) | MegaParticles 6-DOF |
|
 |
| MPPI autonomous racing | MPPI vs Diff-MPPI |
 |
|
MPPI zoo: vanilla vs step_mppi_smooth on dynamic_crossing |
|
 |
|
| Wavefront planner | Diffusion planner |
 |
 |
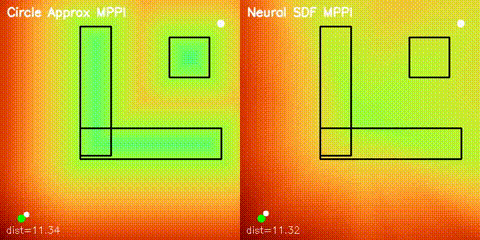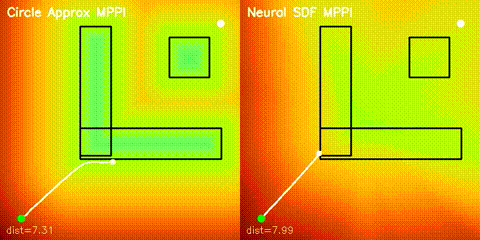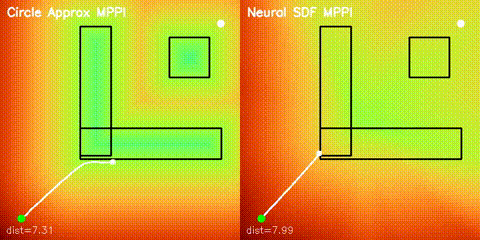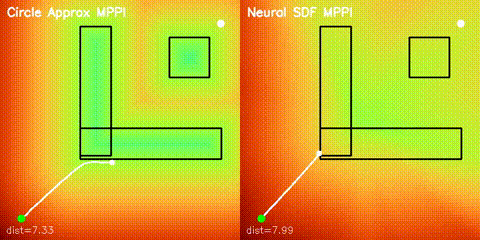
| Batched iLQR | SDF-MPPI |
|
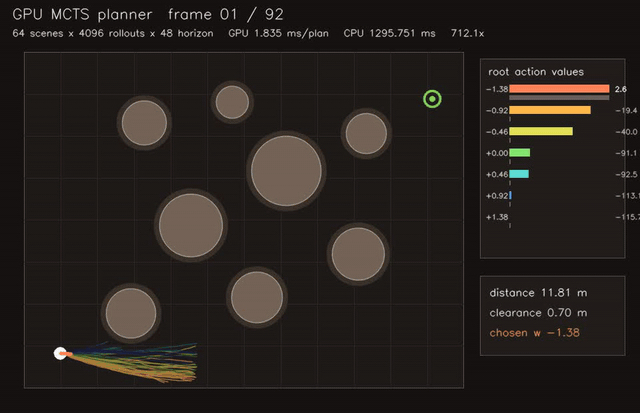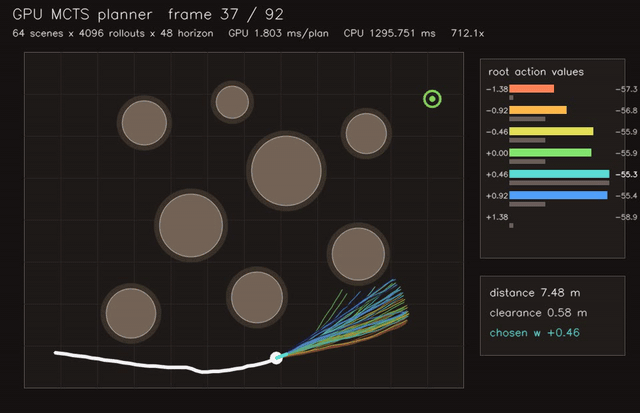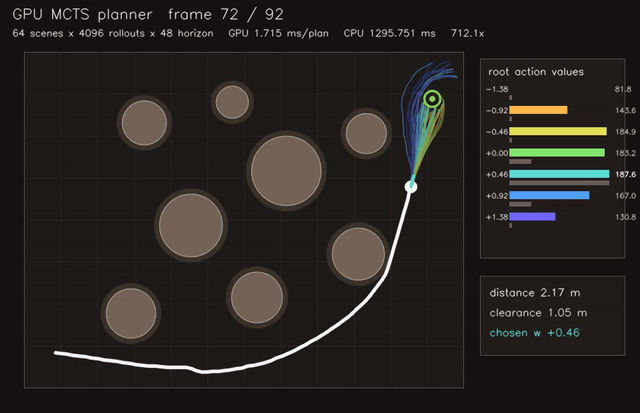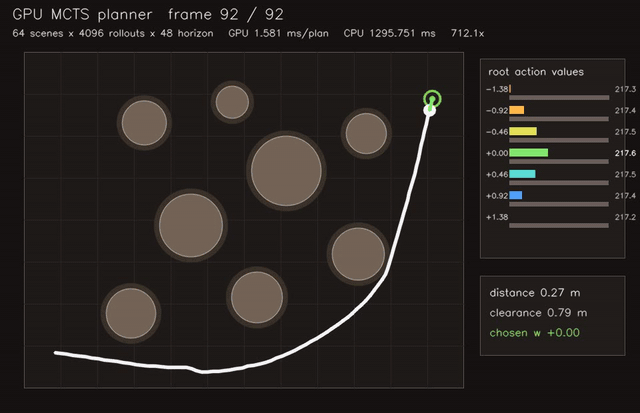 |
| Multi-robot planner | MCTS planner |
 |
 |
| Convex MPC: 1024 batched box-QPs via ADMM (OSQP-style) | Constrained nonlinear MPC: 400 robots, AL-iLQR with hard obstacle limits |
|
|
| SGM stereo | TSDF fusion |
 |
 |
| KD-tree nearest-neighbour | Direct visual odometry |
|
 |
| Marching Cubes | Lucas-Kanade optical flow |
 |
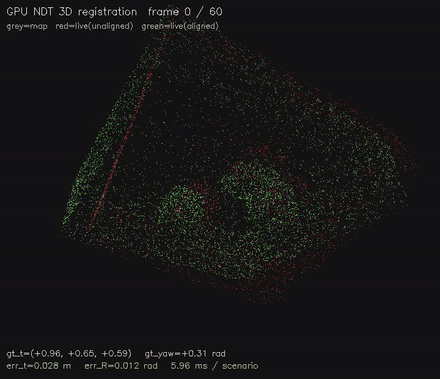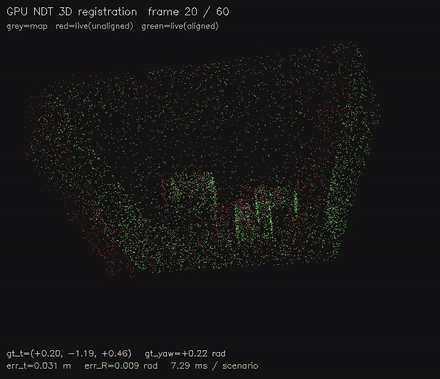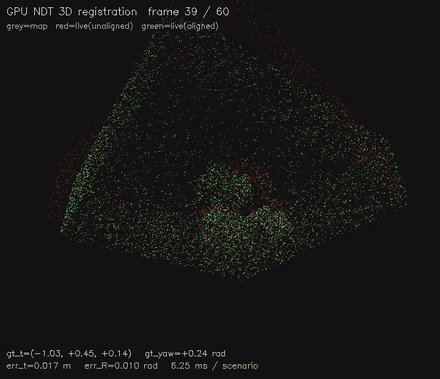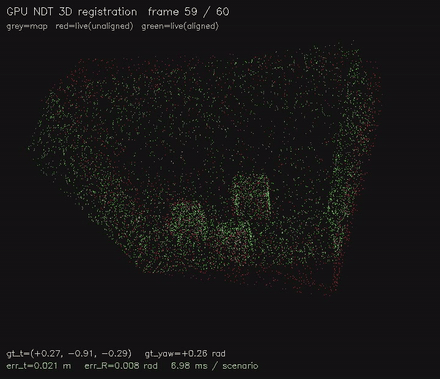 |
| Jump-flood EDT | NDT 3D scan matching |
Modern probabilistic registration in the spirit of probreg, spanning the main
paradigms: filtered EM, Bayesian non-rigid, optimal transport, heavy-tailed
robust EM, and a point-to-plane filtered EM. Each demo recovers a known
transform / warp and is verified in-binary.
 |
 |
| FilterReg (filtered-EM rigid) | BCPD (Bayesian non-rigid) |
 |
 |
| Sinkhorn-OT (unbalanced optimal transport) | Robust Student's-t (2x outlier tolerance vs Gaussian) |
 |
 |
| FilterReg point-to-plane (removes soft-mean curvature bias; 43x lower error at coarse sigma) | Flagship: robust Student's-t x point-to-plane (best under outliers x curvature) |
 |
 |
| Real data: Stanford bunny scan, known SE(3) recovered to 0.1 deg | Fast Global Registration: FPFH + GNC recovers 72 deg from no initial guess |
 |
 |
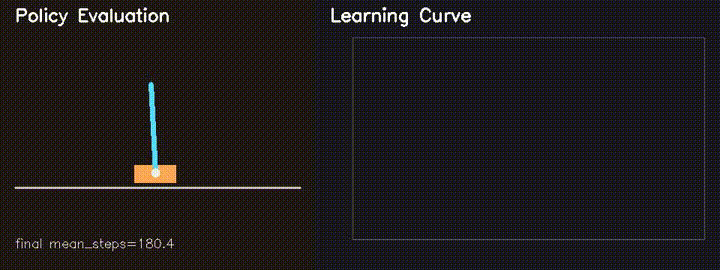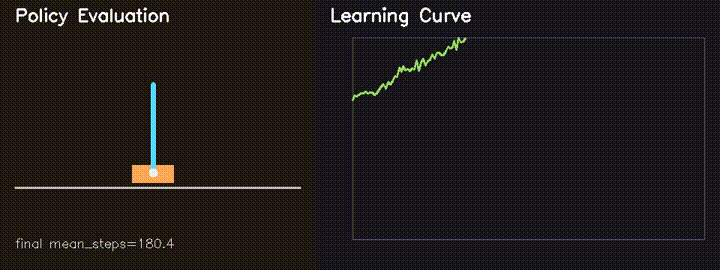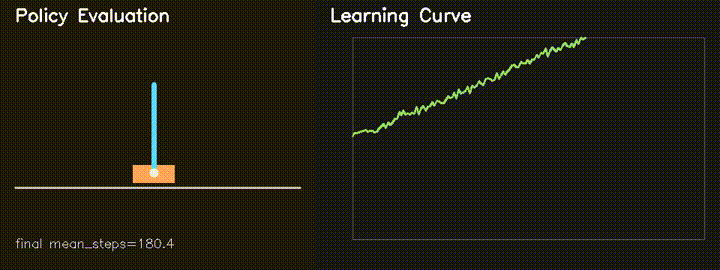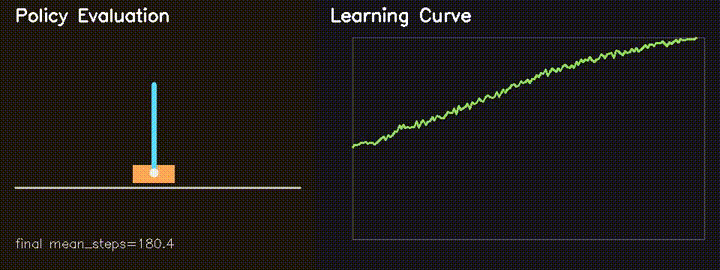
| Parallel CartPole RL (REINFORCE) | GPU neuroevolution |
 |
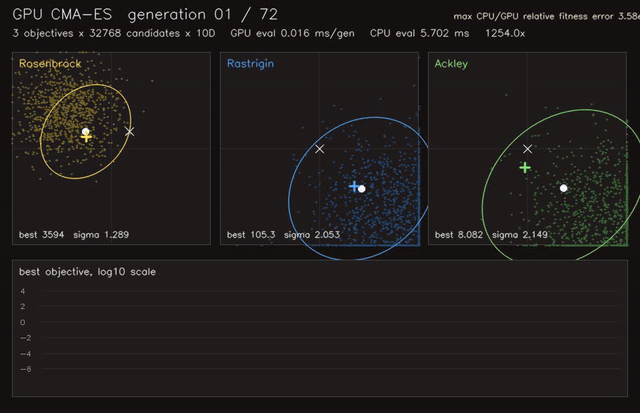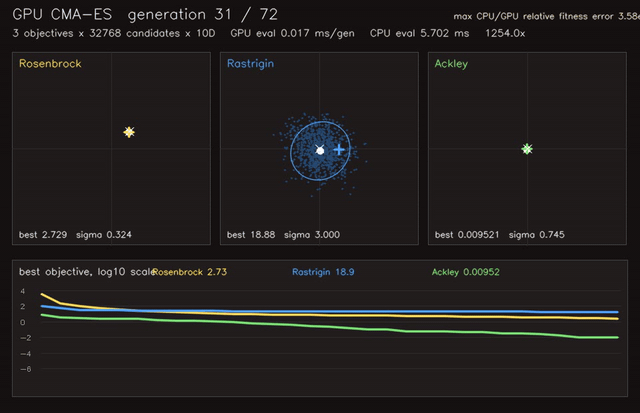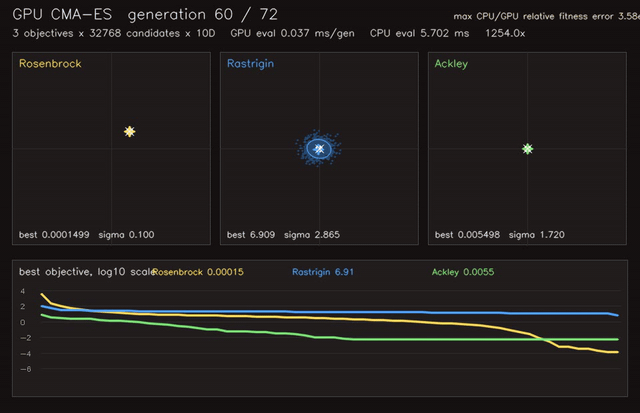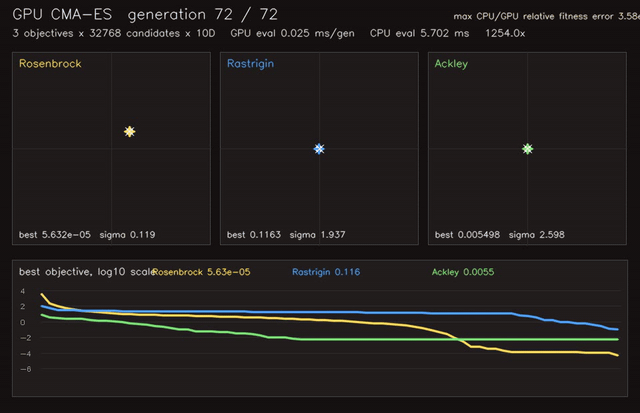 |
| Neural SDF navigation | GPU CMA-ES |
 |
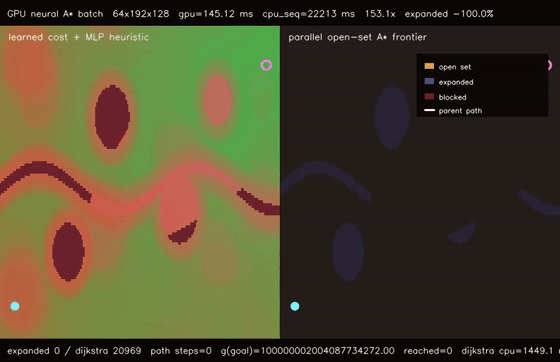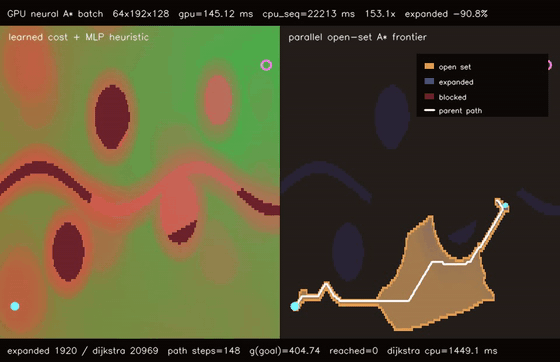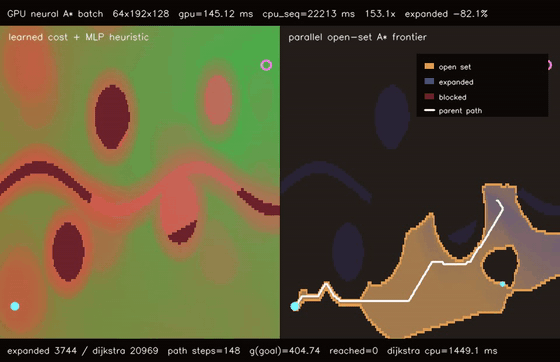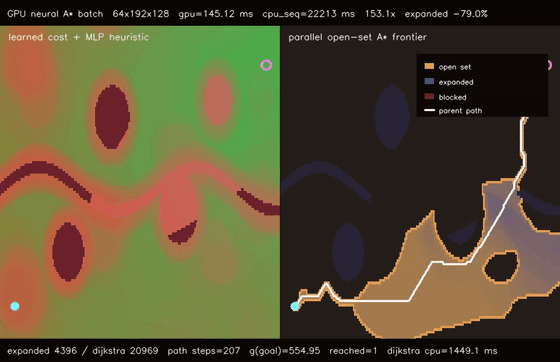 |
| Diffusion policy | Neural A* traversability |
 |
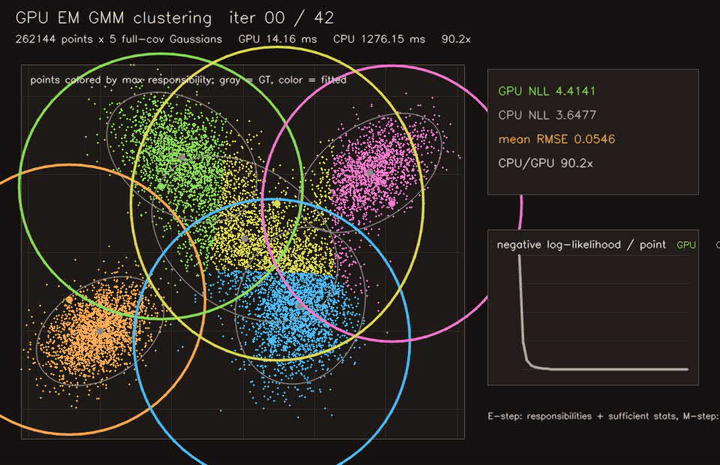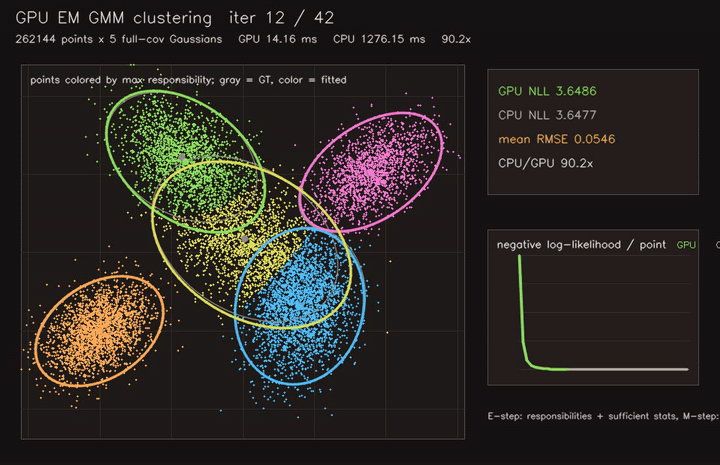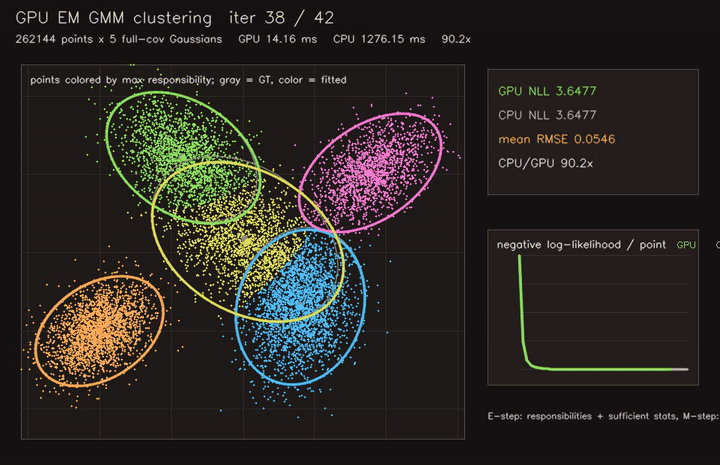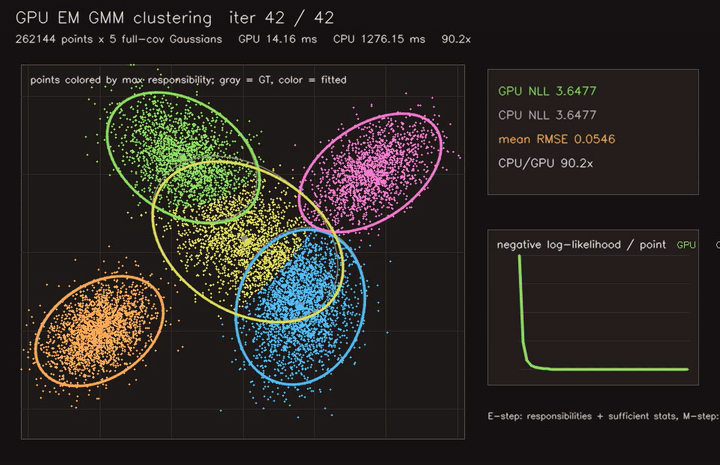 |
| PSO swarm optimization | EM / GMM clustering |
|
|
| Differentiable contact: autodiff-through-contact pushing to a target pose |
 |
 |
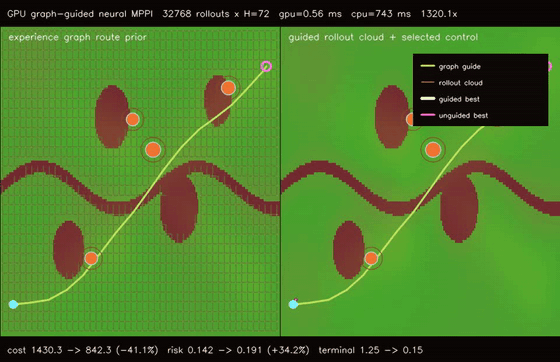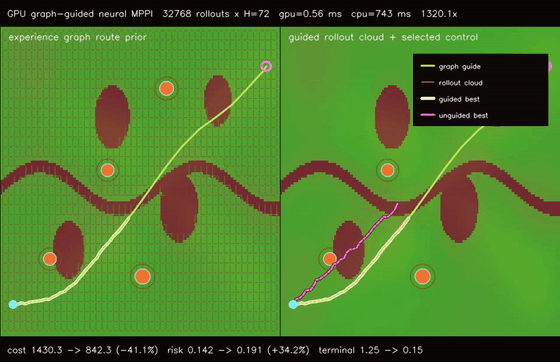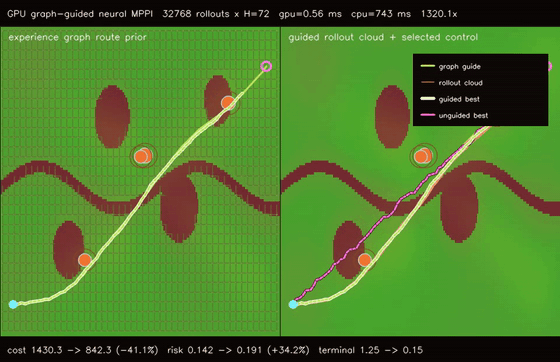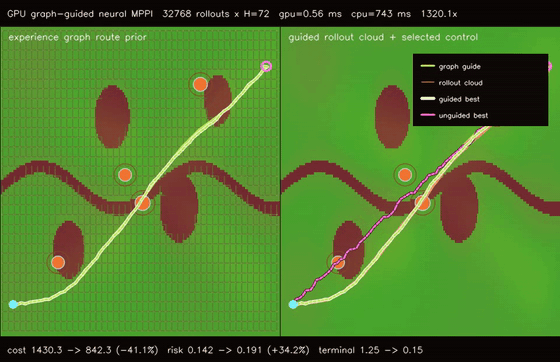
| Graph-guided neural MPPI | No-regret game graph MPPI |
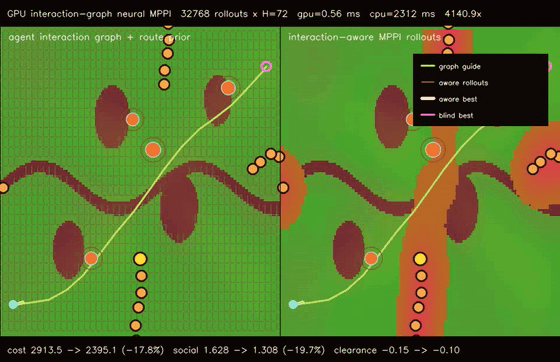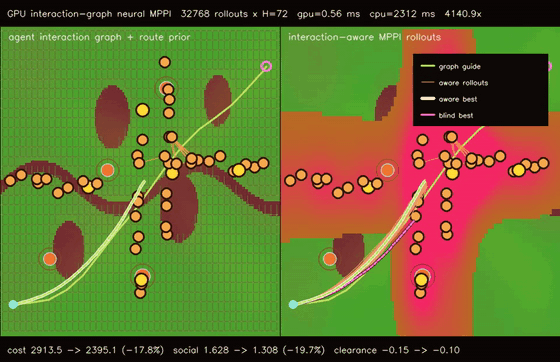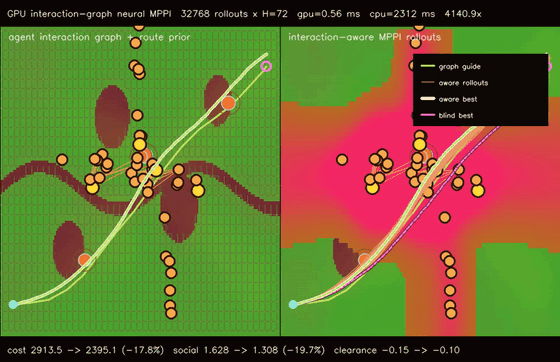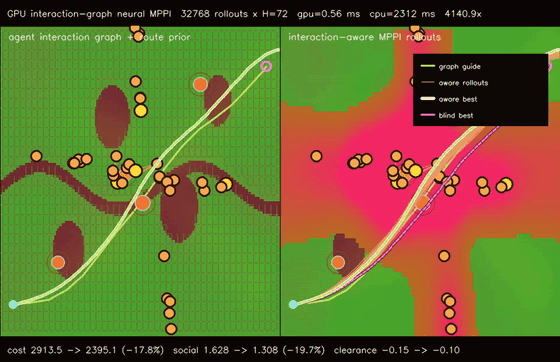 |
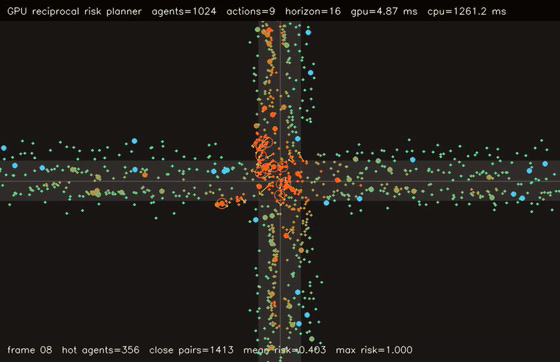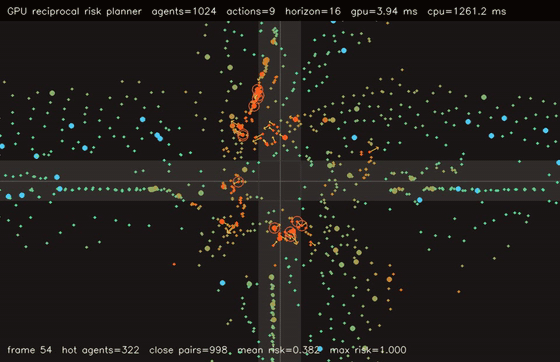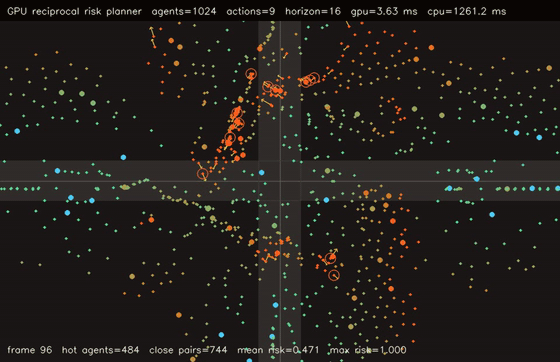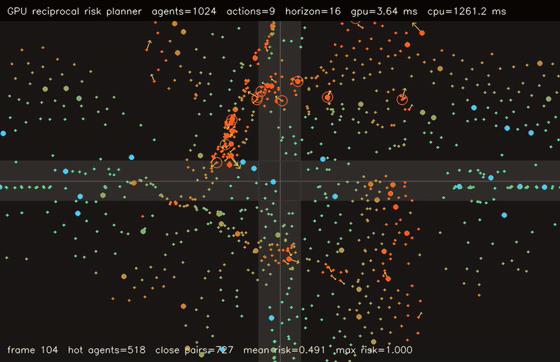 |
| Interaction-graph neural MPPI | Reciprocal-risk planner |
 |
|
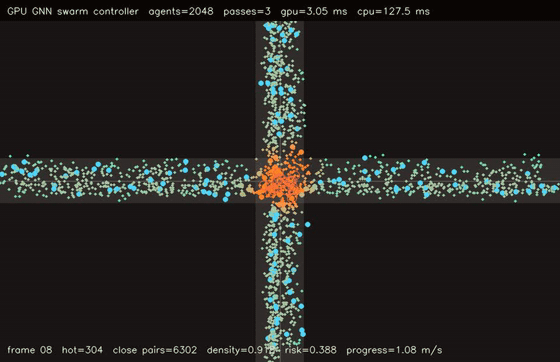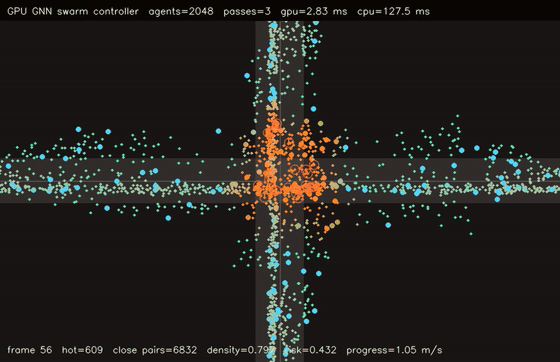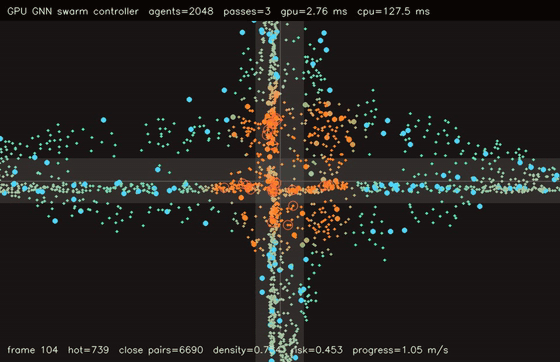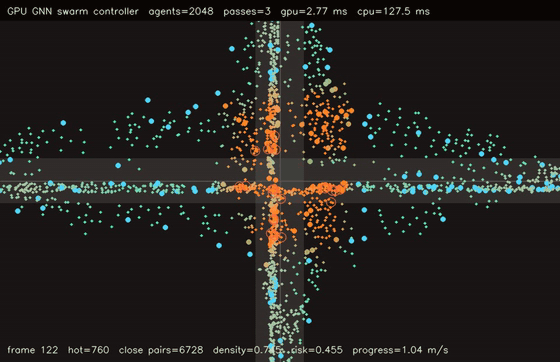
| GNN swarm controller | Crowd / swarm simulation |
- SLAM and scan matching: multi-robot place-graph SLAM, pose-graph SLAM, online SLAM, correlative scan matching, branch-and-bound CSM, submap loop closure, Gaussian-Splatting SLAM, KISS-ICP-style LiDAR odometry.
- Localization and filtering: particle filters, KLD-AMCL, MegaParticles-style global localization, LSH neighbour consensus, robust smoothers.
- Planning and control: MPPI, Diff-MPPI, graph-neural MPPI, no-regret game planners, DWA, RRT family, value iteration, wavefront planning, batched and parallel-in-time (associative-scan) iLQR, convex MPC (batched ADMM box-QP), constrained nonlinear MPC (augmented-Lagrangian iLQR).
- Perception and mapping: LiDAR simulation, occupancy grids, ESDF/JFA, TSDF, Marching Cubes, SGM stereo, optical flow, direct visual odometry, KD-tree NN.
- Point-cloud registration: global front-end (FPFH + Fast Global Registration) plus local probabilistic refiners (FilterReg filtered-EM and its point-to-plane variant, BCPD Bayesian non-rigid, Sinkhorn unbalanced optimal transport, robust Student's-t mixture), NDT, GICP, ICP.
- Learning and optimization: differentiable value iteration, neural A*, GNN/GAT policies, diffusion planners, CMA-ES, MCTS, EM/GMM, graph CRF.
| Path | Purpose |
|---|---|
src/ |
Self-contained C++/CUDA demos and benchmarks. |
include/ |
Shared CUDA helpers. |
docs/ |
Per-demo notes and reproducibility docs. |
scripts/ |
Summary, plotting, and repro-suite tooling. |
gif/ |
Local generated media and benchmark artifacts. |
paper/ |
Diff-MPPI draft material and experiment notes. |
Requirements: CMake >= 3.18, CUDA Toolkit >= 12.0, OpenCV >= 4.5, Eigen 3.
mkdir -p build
cd build
cmake ..
make -j$(nproc)Executables are written to bin/.
Build and run one demo:
cmake --build build --target gpu_mppi_racing -j$(nproc)
./bin/gpu_mppi_racingpython3 scripts/run_repro_suite.py --dry-run --suite smoke
python3 scripts/run_repro_suite.py --build --suite diff-mppiThe runner writes CSVs, summaries, logs, manifest.json, and a human-readable
report.md under build/repro_suite/. See
docs/reproducibility.md for suite details.
- Gallery: https://rsasaki0109.github.io/CudaRobotics/
- MPPI reproduction zoo:
docs/mppi_reproduction_zoo.md - Contributing guide:
CONTRIBUTING.md - Repro suite docs:
docs/reproducibility.md - Next-actions snapshot:
docs/next_actions.md - Diff-MPPI paper draft material:
paper/ - Long-form agent handoff:
plan.md
See LICENSE.md.