struct
shmdb的存储结构首先分为头部和正文两部分,头部存储占用物理内存大小、当前索引使用数目等信息,正文储存HASH索引和索引指向的数据区域。其中索引部分还分为基本索引区和扩展索引区。
图1.1 整体结构
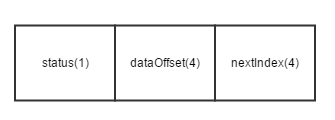
shmdb的索引是用的哈希算法,但是哈希算法存在的一个问题就是,不同的key经过哈希运算之后,求出来的值有可能会相同。所以shmdb采用拉链法来解决这种问题,即将索引区划分为两块,具体的使用逻辑是:对key进行哈希运算得到值index,然后检查基本索引区的index位置有没有被占用(检查status的值,如果当前状态为未使用或者已经删除并且之前所删除的key和value长度均小于当前新建的长度,则代表当前索引区域可以使用),如果没有就将当前key的索引位置记录到基本索引区,同时写入在数据区域存储的偏移量,即图2.1.1中的dataOffset的值;否则需要根据基本索引区index位置存储的nextIndex值来在扩展索引区寻找一个可用索引位置。
图2.1.1索引区域结构
这里我们在小括号中标注的是当前字段储存时所占用的字节数。
为了解释shmdb的拉链法,这里把头部的介绍放到了第二小节。首先看头部的数据结构:
图2.2.1头部区域结构
其中totalLen、baseLen、totalUsed、baseUsed都是针对索引来说的,分别代表总的索引个数(基本索引+扩展索引)、基本索引个数、总共被谁用的索引个数,总共被使用的基本索引个数以及被使用的基本索引个数。函数shmdb_initParent中的第二个参数传入的是基本索引的个数,在程序中计算总索引数和扩展区域索引数的算法如下:首先记基本索引数目为n,然后计算n内的最大质数得到p,则总索引数位p2,响应的扩展索引数位p2-n。
valueOffset字段是下一条可以被写入的数据内容的偏移量,注意这个偏移量当前共享内存块的第0个字节开始算起的,所以初始化valueOffset的值=头部长度+索引区长度。
memLen的值为申请的整个共享内存块的大小。

首先看图
图2.3.1数据区域结构
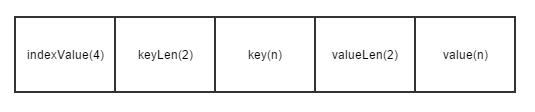
其中indexValue里存储的是在索引区域的位置,keyLen里存储的是key的长度,虽然这里用两字节来存储它,但是在程序中要求其不能大于255,单个内容区块(包含indexValue、keyLen、key、valueLen、value)要求最长不能超过4KB,由此可以计算出valueLen的不能大于4KB-4-2-2-255。