This project started under the impetus of a series of lectures by Dr. M. Heydari Malāyeri titled "Persian Writing" (available on youtube since Oct 2018.) For the time being, this page is the single document capturing the software design specifications and tracking the developments. It also includes linguistic insights which drive the design and development. As we progress, some of the information will migrate to designated websites and wiki pages to make this page shorter. Some of the features described here may also migrate to designated repositories.
Pārsi, also known as Persian or Fārsi, is a Western Iranian language belonging to the Iranian branch of the Indo-Iranian subdivision of the Indo-European languages. The Present Pārsi Writing System (PPWS) resembles Arabic writing. Pārstin is the name proposed by Iranian Astronomer, Astrophysicist and Linguist Dr. Mohammad Heydari-Malayeri for an alternative writing system for Pārsi, which resembles the Latin transcription. It has significant advantages and improvements to offer over PPWS. The proposed writing system (Pārstin) was justified and explained in detail, after an in-depth analysis by Iranian Philosopher and Translator Dr. Mir Šamsoddin Adib-Soltāni in his book: "Darāmad-i bar cegunegi-ye šive-ye xatt-e fārsi" An Introduction to Problems of Persian Orthography. Amirkabir Publications, Tehran, 1976. Thanks to Dr. M. Heydari-Malayeri for preparing the following infographic showing the new alphabet.

(Source: https://t.me/persianmalayeri/1738)
The primary objective here is to provide the public with free tools for seamlessly transliterating the digitized Persian literature, documents and web content in PPWS into the Pārstin script.
Recommending Pārsi equivalents for the words, in the rendered text, that come from other languages.
According to Dr. M. Heydari-Malayeri, here are two promises of changing the writing system to Pārstin:
1- "Equipping Pārsi with the alphabet which is compatible with the language."
2- "A cultural excitation, or trigger, for associating Iranians with methodology and precision in thinking."
It's thrilling that with this project's success we can get one step closer to such values.
I came up with the following initial design. Feedbacks are encouraged and appreciated.
Pārstin Engine Preliminary Workflow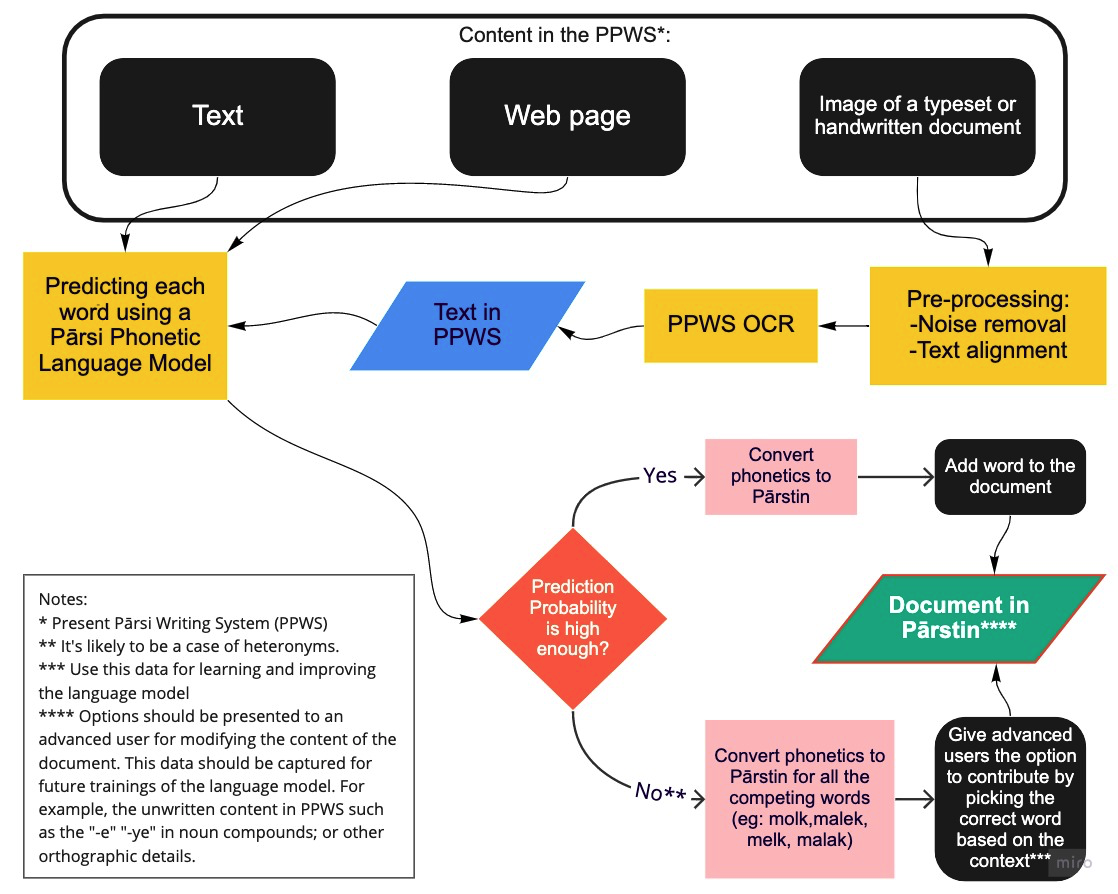
The most time-and-effort-consuming step in a machine learning project is almost always the data collection stage, and should be planned as early as possible. The hardest-to-obtain data in our case is how a Pârsi reader would interpolate all the unwritten information in PPWS (a, e, o, etc) in order to interpret a phrase and pronounce it. Therefore, this should be our primary focus. In this phase we aim to develop the means for transliterating all the heteronyms, for any words written in PPWS, into Pârstin. Also, we want to display all the possible Pârstin interpretations of a phrase to a user as options to choose between them, and to collect their input from this interaction. More specifically, these are the requirements to be satisfied:
- Explaining the rationals as well as establishing the orthographic rules for Pārstin.
- Adapting or developing a Comprehensive Index of Pârsi words (in PPWS) and their pronunciation (either phonetics or Pârstin transcription).
- Implementing the mapping for converting between phonetics and Pârstin.
- Developing an AI model for predicting the pronunciation of a word in PPWS based on the training data available from 2. This is specially useful when we encounter a new word which is not in our index.
- Deriving all the possible transliterations for each word in a phrase (or each unit separated by a space, e.g. when dealing with non-particular, plural nouns, or noun compounds).
- Developing an interactive UI for visualizing all the available options for pronouncing a phrase, taking the user input, and collecting this data.
- Setting up a secure server and an encrypted database for storing the data collected in 6, to be used for the next phase.
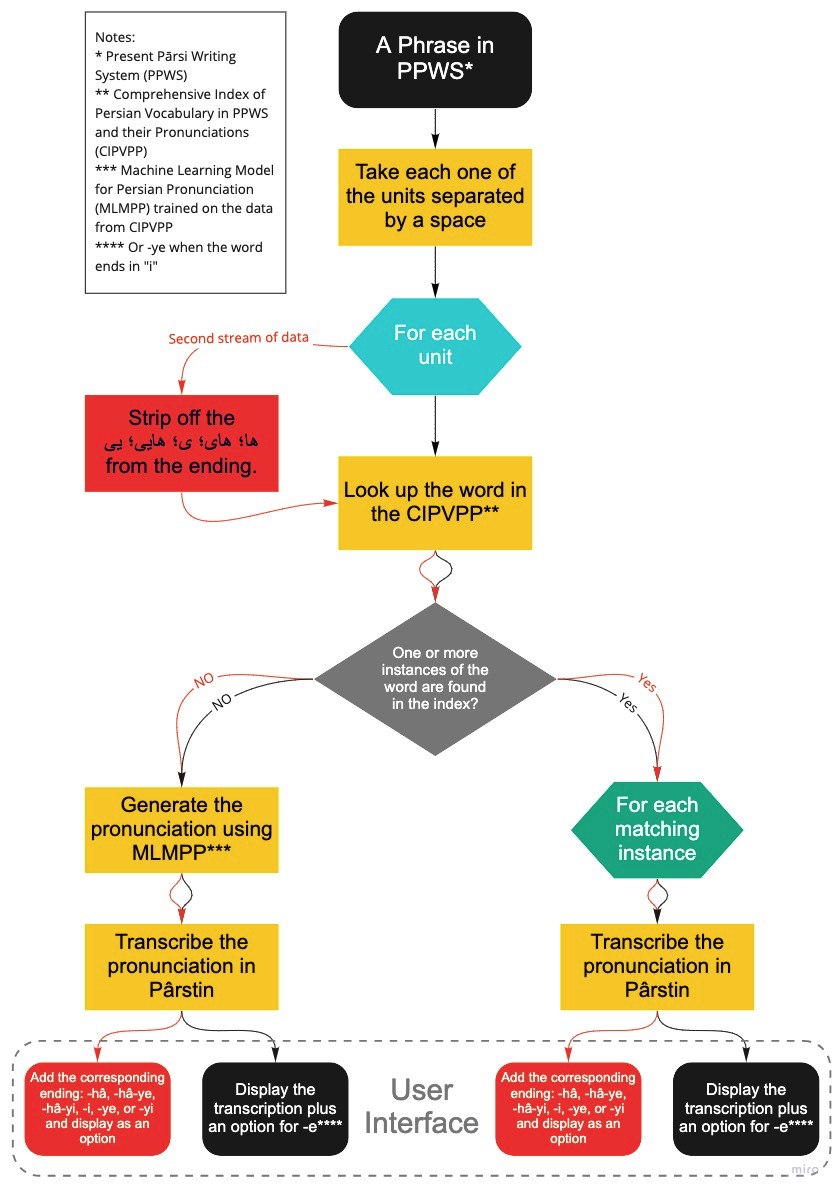
Example: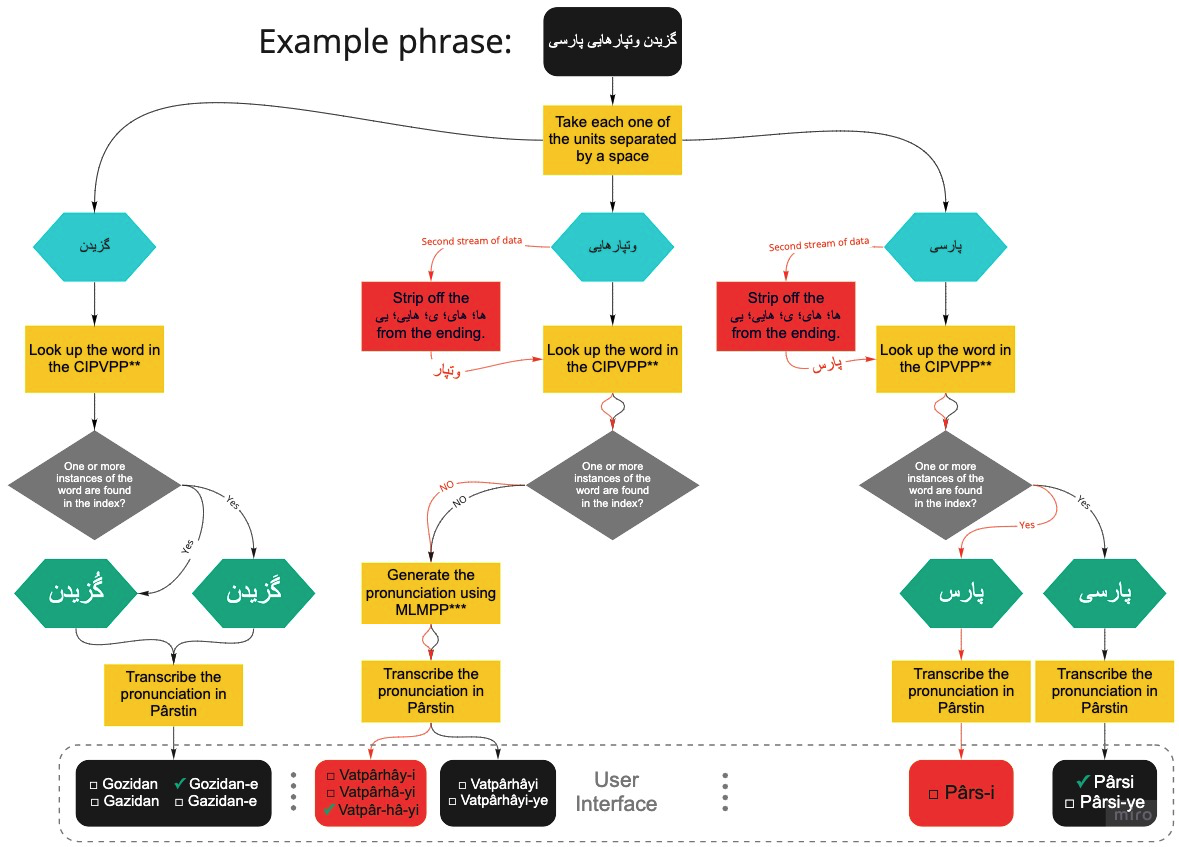
A conceivable interpretation can involve a web interface showing the user a random verse from a piece of modern poetry (e.g. from Yušij, Axawān Sāles, Sepehri, Šāmlu, etc.) and presenting them with pronunciation choices for that verse. If the user found themselves interested, they could choose to conduct the same exercise for a larger portion of the same poem one verse at a time.
- Any (semi-)comprehensive database of persian words (in PPWS) accompanied with their phonetics or Pārstin transliteration would be extremely crucial and helpful. At this time, the only avialble resource that I could locate with such data is the Etymological Astronomy and Astrophysics Encyclopedia by Dr. M. Heydari-Malayeri.
- A community of users and developers who can relate with the rationals of this project and acknowledge its value to the point that they would be willing to contribute to its developments.
Once the amount of data collected in PHASE 1 is sufficient enough to train an AI algorithm for interpreting the pronunciation of phrases, we can present the user with the AI's predictions transcribed in Pārstin and encourage the user to correct them when needed. It is important to collect this data as well.
This Phase can also be implemented in a web browser environment. For example, as an extension which overlays the webpages in PPWS with Pārstin transliteration, or as a designated website which presents the reader with the predicted Pārstin transliteration of Pārsi literature, and gives them the option to correct the predictions when required.
While the databases described in previous phases are being populated, and the Machine Learning Models are being periodically retrained with new data, we can focus on:
- OCR (Optical Character Recognition) of texts and manuscripts,
- Advancing the AI to become capable of transliterating even the Classical Persian Literature and Poetry,
- Making a user-friendly app which can work between scanners and printers as seamlessly as possible,
- Developing composition tools (e.g. a keyboard for smartphones) for suggesting precise Pārsi equivalents for the obscure and imprecise foreign vocabulary that has infiltrated Pārsi through ages.
For this process, a good approach might be to first evaluate the existing PPWS OCRs and if the performance was not satisfactory (close to perfect) we need to consider creating a better OCR tool. Here are some ideas that I can imagine being helpful: 1- Taking advantage of the common textbook fonts as well as the wealth of the novel fonts resembling handwriting and calligraphy that has recently become available, thanks to the creative work of iranian typographers, to creating training datasets. This way the OCR will more likely be effective for handwritings as well as texts. 2- Take advantage of Image Augmation methods such as imgaug for adding various noise, rotation and distortion effects to the dataset. 3- Use the database of classical Persian literature available from Ganjoor for creating the dataset.
A quick test of Google Translate's handwriting input for Pārsi shows promising results. However, it is not Open Source, therefore we cannot rely on it for this project.
Google translate: does not provide text-to-speech for sentences in PPWS. Ariana text-to-speech: I could determine that this tool is capable of converting simple sentences to speech, so it can derive some of the unwritten phonetic information but as the complexity increases mistakes become prevalent to the point that it barely works for poetry. Also it is not an open source application.
This step seems to have the least amount of complexity as there is a one-to-one mapping between the phonemes in Pārsi and the Pārstin graphemes.
There is a fundamental distinction between Pārstin and other transliteration algorithms. Here the pronounciation of the words are interpreted based on the context of the phrases that they make up.
For example, he "-e" and "-ye" in the middle of a noun compound.
Such information is almost always absent from the present farsi writing, and added in the minds of the reader. Therefore, we need to populate a database from the users' input for training the model for this purpose. Two approaches come to mind at the initial stage when the database is so small that the Pārstin conversion is still unreliable. 1- A web extension that overlays text with Parstin can add an optional -e or -ye at the end of such noun compounds so people can make the correct choice based on the context. 2- A website can provide readers with short excerpts from literature written in both writing systems and provide them with tools to correct the Pārstin text.
They share the same letter in PPWS.
Linux (Ubuntu): all the special characters in the Pārstin alphabet can be entered through the definition and use of the Compose key.
Android (G-board), MacOS, iOS: all the special Pārstin characters are accessible by long-pressing the corresponding letter (e.g z for ž, and a for ā) on the key board. (Update: MacOS cannot do ğ by default. iOS TBD)
Windows 10 - after 2019 the special characters can be found in the Emoji Panel (WindowsKey + . ).